






###########################################
在工作中,我们经常需要将数据导出成表格的形式。常见的cvs格式(使用逗号分隔),虽然生成简单,但难免存在以下问题:
1、需要对文本中的逗号进行转义,特别是当文本中需要保留逗号的时候,往往无能为力。
2、字符编码问题,对于Office的一些版本,直接打开utf8编码的cvs,可能会出现乱码。因此,依然需要将cvs另存为Excel格式,才能方便使用。
下面我们介绍开源模块openpyxl,它能够帮助我们在Python中,直接操作Excel 2000文件格式(xlsx)。
###################################################
1 下载地址http://download.csdn.net/detail/kernelke/5192910
2 下载文件openpyxl-1.6.1.tar.gz
3 解压到任意路径下,例如:解压后的路径为C:\openpyxl-1.6.1
4 安装
打开window窗口输入以下:
cd C:\openpyxl-1.6.1
python setup.py install
5 简单使用
直接在shell下面把玩一下
>>> from openpyxl.reader.excel import load_workbook #包导入
>>> wb = load_workbook(filename=r'C:/test.xlsx')#打开文件
>>> print "Worksheet ranges(s):",wb.get_named_ranges()
Worksheet ranges(s): []
>>> print "Worksheet names(s):",wb.get_sheet_names()
Worksheet names(s): ['Sheet1', 'Sheet2', 'Sheet3']
>>> sheetnames = wb.get_sheet_names()
>>> ws = wb.get_sheet_by_name(sheetnames[0]) #打开sheet1
>>> for rx in range(ws.get_highest_row()): #对第一个column遍历打印值
print ws.cell(row=rx,column=0).value
二、解析、读取xlsx文件
1、从xlsx到工作表(worksheet)
我们知道,一个Excel文件称作一个workbook。在它之中,可以包含多个worksheet(工作表)。
我们先来看一下如何定位到工作表。假设我们的Excel文件如下:
![]()
下述代码,将列出所有worksheet:
|
1
2
3
4
|
import openpyxl
work_book = openpyxl.load_workbook("./test.xlsx")
work_book.get_sheet_names()
# >>> ['Sheet1', 'Sheet2', 'Sheet3']
|
将会一数组的形式,输出所有表名:
我们在关闭xlsx的时候,会保存当前活动的worksheet。get_active_sheet返回的是一个WorkSheet对象,用它可以操控具体的工作簿,后文会提到。在这里,我们打印其title属性即标题:
|
1
2
|
work_book.get_active_sheet().title
# >>> 'Sheet1'
|
除了上述方法,我们也可以通title,直接选择worksheet:
|
1
2
|
work_book.get_sheet_by_name("Sheet2").title
# >>> 'Sheet2'
|
2、读取工作表中的内容
openpyxl的强大之处在于:支持使用’A2′、’D10′这种Excel的坐标格式,直接定位单元格。
我们用于测试的Excel中,预设了如下内容:
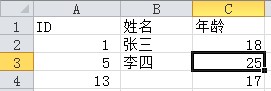
下面,我们直接获取Cell中的值
|
1
2
3
4
5
|
work_sheet = work_book.get_sheet_by_name("Sheet1")
work_sheet.cell('A1').value
# >>> u'ID'
print work_sheet.cell('B2').value
# >>> 张三
|
我们可以注意到,中文被直接输出为了UTF8(我的测试环境为Linux、LC为UTF8)。
如果只是为了获取所有的Cell,不考虑其顺序,可以直接使用collection:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
for cell in work_sheet.get_cell_collection():
print cell.value
# The follwing are outputs
ID
5
1
姓名
张三
李四
25
18
年龄
17
13
|
当然,再更多的时候,我们希望按照行、列遍历表格。
openpyxl除了支持’A3′这种直接定位,也可以通过行、列定位Cell。而行、列可以通过get_highest_*函数获得。下述代码,展示了按照行、列顺序,打印Cell
|
1
2
3
4
5
|
for r in xrange(0, work_sheet.get_highest_row()):
for c in xrange(0, work_sheet.get_highest_column()):
val = work_sheet.cell(row=r, column=c).value
if val != None:
print r,c, val
|
输出为:
|
1
2
3
4
5
6
7
8
9
10
11
|
0 0 ID
0 1 姓名
0 2 年龄
1 0 1
1 1 张三
1 2 18
2 0 5
2 1 李四
2 2 25
3 0 13
3 2 17
|
这里需要注意一个细节,对于单元格“李四”,数字下标定位为:row=2,col=1;字母定位为“B3”。
也就是说,row, col定位,下标都是从0开始。而字母方式,行从1开始,列从A开始。
在使用中,一定要注意这一点!
三、修改工作表
1、新增行、列
下述代码在列A下,新增一行:
|
1
|
work_sheet.append({'A':'新增@列A'})
|
下述代码,新增一列D,并新增一行
|
1
|
work_sheet.append({1:'新增列D'})
|
2、直接指定行列
更多的时候,我们直接设定单元格的值。
下面的代码,将在excel中打印9* 9 乘法口诀。
|
1
2
3
4
5
|
for r in xrange(0, 9):
for c in xrange(0, 9):
val = (r+1)*(c+1)
if val != 0:
work_sheet.cell(row=r, column=c).set_value_explicit(value=val, data_type='n')
|
我们可以发现,设定cell也是用的cell函数。set_value_explicit的data_type应该是支持设定cell类型的,遗憾的是,我在使用中发现该设定不管用。
修改完后,需要保存,这需要用到我们最开始使用的work_book对象:
|
1
|
work_book.save("test2.xlsx")
|
四、其他
在默认情况下,openpyxl会将整个xlsx都读入到内存中,方便处理。
这使得操作大文件的时候,速度较慢,可以使用Optimized reader和Optimized writer。它们提供了流式的接口,速度更快。
更多的API、使用方法,可以参考官方文档:http://pythonhosted.org/openpyxl/api.html















 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









