







1.什么是MapReduce
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于Hadoop 的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop 集群上。
2.Hadoop 序列化
1)什么是序列化和反序列化
序列化就是把内存中的对象转换成字节序列或者其他数据传输协议,以便于存储到磁盘和网络传输。
反序列化就是将收到的字节序列或者此磁盘上的持久化数据转换成内存中的对象。
2)为什么要序列化
一般来说,对象只能生存在内存中,关机断电就没有了,对象只能由本地的进程使用,不能被发送到网络上的另一台计算机,然而将对象序列化之后就可以将对象发送给远程计算机了。
3)为什么不用Java 的序列化
java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化之后会附带很多额外的信息,不便于在网络中高效的传输,所以hadoop自己开发了一套序列化机制(Writable)。
4)Hadoop 序列化特点:
紧凑:高效的使用存储空间
快速:读写数据的额外开销小
互操作:支持多语言的交互
5)自定义的bean对象实现序列化
1.实现Wriable接口
2.重写序列化和反序列化接口
3.如果自定义的bean要作为key在框架中,还需要实现Comparable接口。
3.FileInputFormat切片解析
1.程序首先找到数据存储的目录。
2.开始处理目录下面的每一个文件。
3.遍历第一个文件a.txt
3.1获取文件的大小
3.2计算切片大小
3.3开始切片(每次切片时都要判断切完剩下的部分是否大于快的1.1倍,不大于1.1倍就划分一块切片)
4.提交切片规划文件到yarn上,yarn上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
4.CombineTextInputFormat 切片机制(防止小文件过多)
1)应用场景:
CombineTextInputFormat 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask 处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3)机制

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2 倍,此时将文件均分成2 个虚拟存储块(防止出现太小切片)。例如setMaxInputSplitSize 值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M 逻辑划分,就会出现0.02M 的小的虚拟存储文件,所以将剩余的4.02M 文件切分成(2.01M 和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize 值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4 个小文件大小分别为1.7M、5.1M、3.4M 以及6.8M 这四个小文件,则虚拟存储之后形成6 个文件块,大小分别为:1.7M,(2.55M、2.55M),3.4M 以及(3.4M、3.4M)
最终会形成3 个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
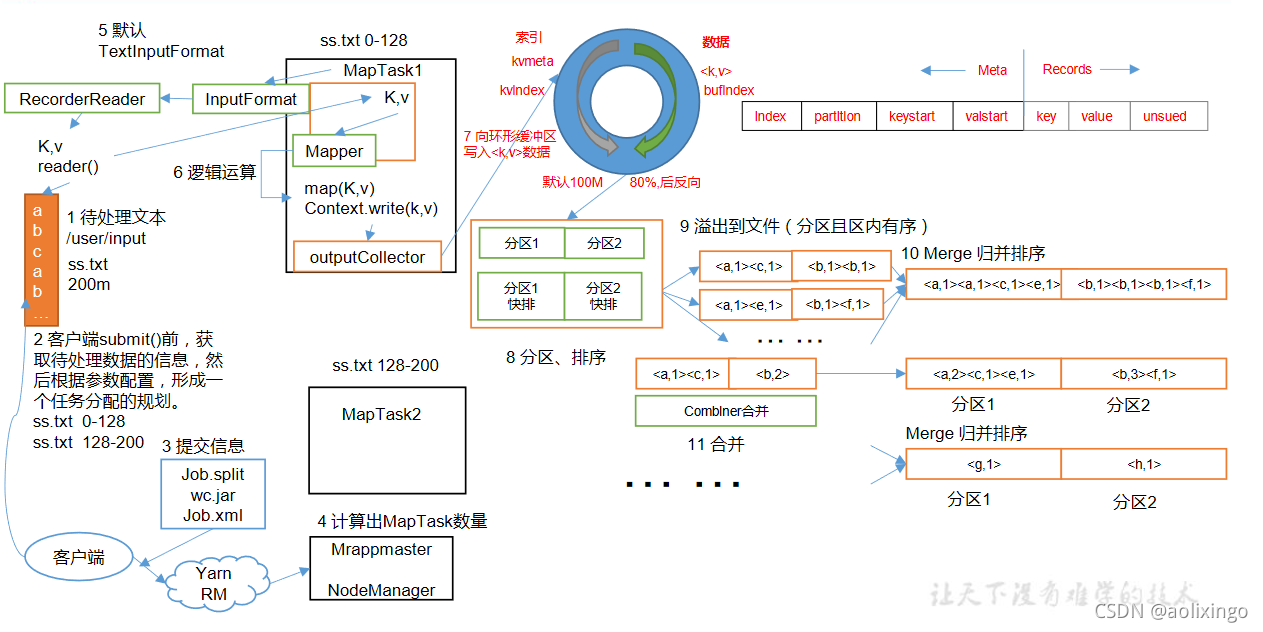
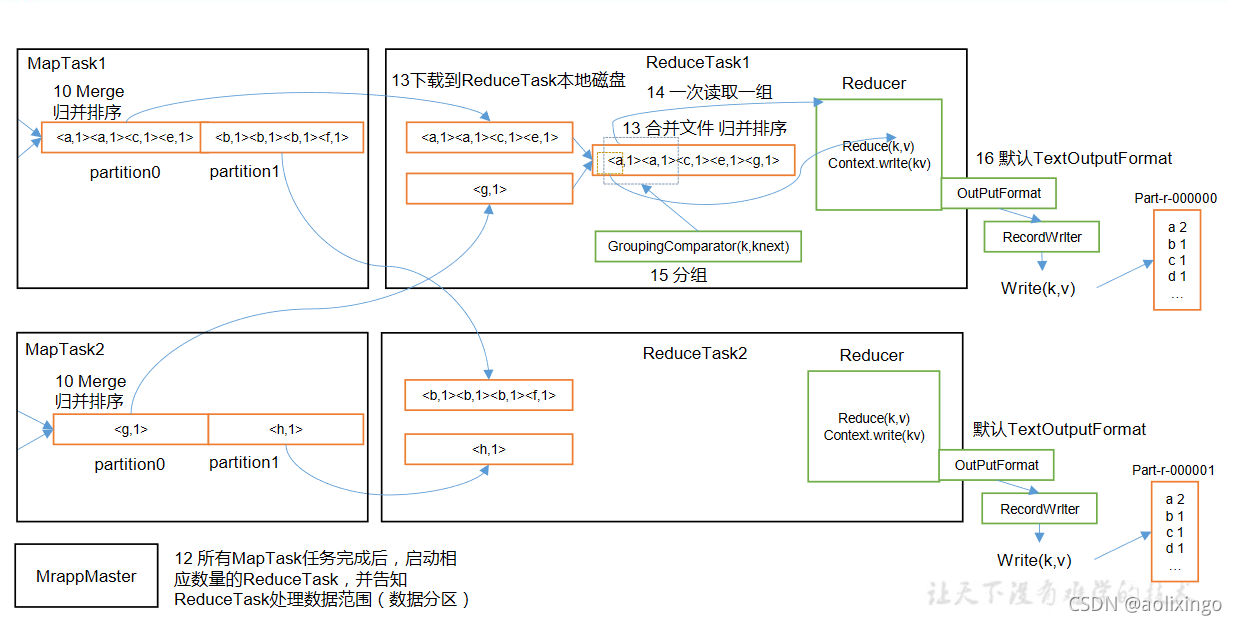
5.MapReduce工作流程















 3855
3855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









