




关于FedAvg的代码架构学习
分别有data log models save utils 四个子目录
data目录
data目录下存放了数据集,fedavg用了2个分别是
CIFAR-10(10类的彩色图片)
每个类别6000张图片,共60000张图片
,其中50000张训练图片,10000张图片
MNIST(手写数字的黑白图片)
0-9的手写数字图片,其中60000张训练图片,10000张测试图片
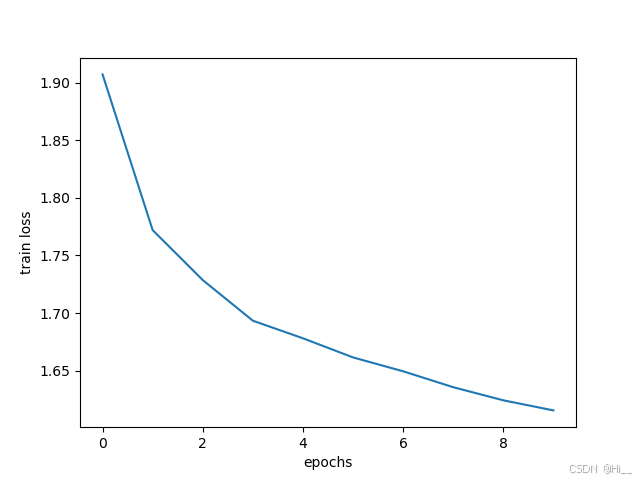
log
存放集中式训练的损失函数随训练轮数变化的图片
models
此目录下有5个py源码文件,分别是Fed,Nets,test,Update
Fed.py
def FedAvg(w)
FedAvg函数实现将客户端的模型参数全部相加并求平均的功能
返回值为平均参数
Nets.py
有三个类分别是
class MLP(nn.Module):
使用库函数实现人工神经网络mlp,首先初始化父类模型,并实例化self对象,然后def forward(self,x)函数,向前传播,经过输入变为一维向量的处理函数-输入层-防止过拟合-激活函数-输出层
最终返回输出值
class CNNMnist(nn.Module):
实现卷积神经网络对mnist的处理,先实现父类函数,使用卷积提取特征再使用最大池化方法减少特征数据量,使用relu激活函数输出并使用正则项损减少过拟合。
class CNNCifar(nn.Module):
实现卷积神经网络对Cifar的处理,首先使用卷积提取特征,使用2*2的最大池化减少特征数据量,放入激活函数并到全连接层整理全局特征最终到输出层输出类别
test.py
实现打印训练过程中相关信息的功能,如打印交叉熵损失,平均损失,预测率等
Updata.py
实现了客户端训练的功能
class DatasetSplit(Dataset) 数据集分割类,实现构造子集的功能
class LocalUpdate(object): 本地训练更新类,实现本地训练的功能
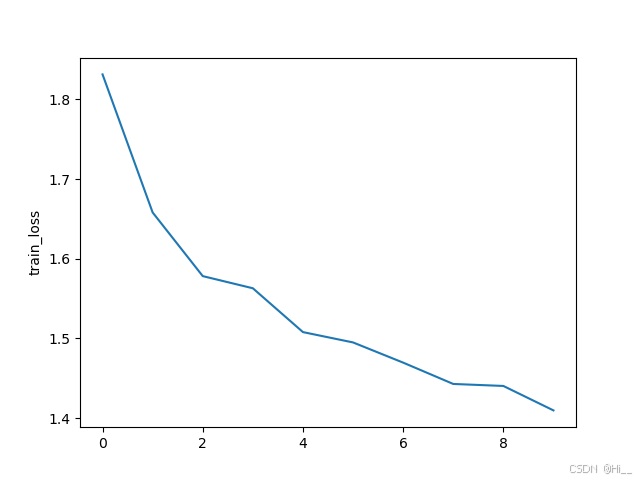
save文件夹
用于存放联邦式训练,损失函数和训练轮数的关系
utils
有两个py文件,分别是options.py和sampling.py
options.py
写明超参数的py文件,例如训练轮数,数据集,batch大小,客户端数量,学习率等
sampling.py
实现了数据集合iid划分和non-iid划分
main_fed.py
主函数,首先根据数据集选择不同的数据处理和构建数据集合的方法
然后创建模型,调用nets.py自定义的模型
然后训练e轮次,在训练轮次中保存客户端参数,最终平均聚合更新到全局模型。
画出损失函数和训练轮数
测试


















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









