






说了这么多,这一节是本文最后一节啦。就是程序的进一步优化。
这一节呢。还分那么几个小意思。- -!
1.程序逻辑和机制的优化
2.源代码级代码的优化
3.针对CPU和操作系统的编译优化
问:大侠。我是过来人,排序哈希我渐渐习惯了,不痛了,还有哪些地方能够更刺激的
答:前面我们提到检測局面反复。不要让后面的局面有跟走过的局面一样。导致无限的堕落。无法自拔,另一样是能够算作反复的
那就是失败的局面,即没有一个箱子能够有效推的局面。再出现这个局面就不要分析了。直接删掉吧,那么我们就要再创建一个失败
局面队列,把失败过的局面箱子坐标和哈希值以及搬运工的位置保存下来。哈希值是为了哈希计算,而坐标则是为了万一的万一的万
一的万一有反复,局面解不出来,那么就原汁原味的使用坐标比較。当然使用纯哈希比較求解的时候坐标既不保存也不分配内存。
问:那么就仅仅有这个吗?
答:相同。失败的局面向父级递归,tagStage.Slaves递减,假设降到零,那么父级也是失败局面。跟着连坐。也增加失败局面队列。
问:爽!
我想立即看源代码,我要看,我要看……
答:
// 记录失败场景快照(临时未完毕測试)
int fnStageSnap(PQUEUE pQueue, PSTAGE pStage)
{
union {
PSNAP pSnap; // 快照指针
BYTE *pDummy;
};
PSHOT pShot;
int dwRet;
pShot = pQueue->Shots;
if(pShot->Count)
{
pSnap = (PSNAP)realloc(pShot->Snaps, pShot->Size * (pShot->Count + 1));
}else
{
pSnap = (PSNAP)malloc(pShot->Size);
}
if(pSnap)
{
pShot->Snaps = pSnap; // 更新指针
//pSnap = &pSnap[pNext->Shots->Count]; // 结构体不定大小
pDummy += pShot->Size * pShot->Count;
pSnap->Position = pStage->Position;
pSnap->Hash = pStage->Hash; // 布局指纹
if((pStage->Flags & SGF_CRC32) == 0)
{
// 排序存储坐标详情(仅仅要不归位, 都会撤销回到最初, 不必排序)
//fnStageSort(pNext->Stars, NULL, pSnap->Stars, pNext->Count);
V32Copy(pSnap->Stars, pStage->Series, sizeof(STAR) * pStage->Count);
}
pShot->Count++; // 递增失败局面数量
// 向上递归父级场景, 全部待分析子场景数量为零的都将记录到失败列表并弹出队列
pStage = pStage->Host;
if(pStage != NULL)
{
#ifdef _DEBUG
fnPrint("父级场景=0x%08X, 剩余子级场景数量=%d.\r\n", pStage, pStage->Slaves);
dwRet = fnQueueRange(pQueue, pStage);
if(dwRet <= 0)
{
fnPrint("[警告]场景0x%08X不在有效队列中!\r\n", pStage);
return 1;
}
if(pStage->Slaves == 0)
{
fnPrint("[警告]场景0x%08X已经没有子场景!\r\n", pStage);
return 1;
}
#endif
pStage->Slaves--; // 调试完毕能够确保计数为正
if(pStage->Slaves == 0)
{
#ifdef _DEBUG
fnPrint("记录父级场景=0x%08X到失败集合.\r\n", pStage);
#endif
dwRet = fnStageSnap(pQueue, pStage);
if(dwRet <= 0) return dwRet - 1;
#ifdef _DEBUG
fnPrint("移除父级场景=0x%08X.\r\n", pStage);
#endif
fnQueueRemove(pQueue, pStage);
return dwRet + 1; // 返回级数
}
}
return 1;
}
fnStageCode(SEC_CACHE_NULL);
return 0; // 内存不足, 数据不变
}问:那么,可有执行效果比較?
答:
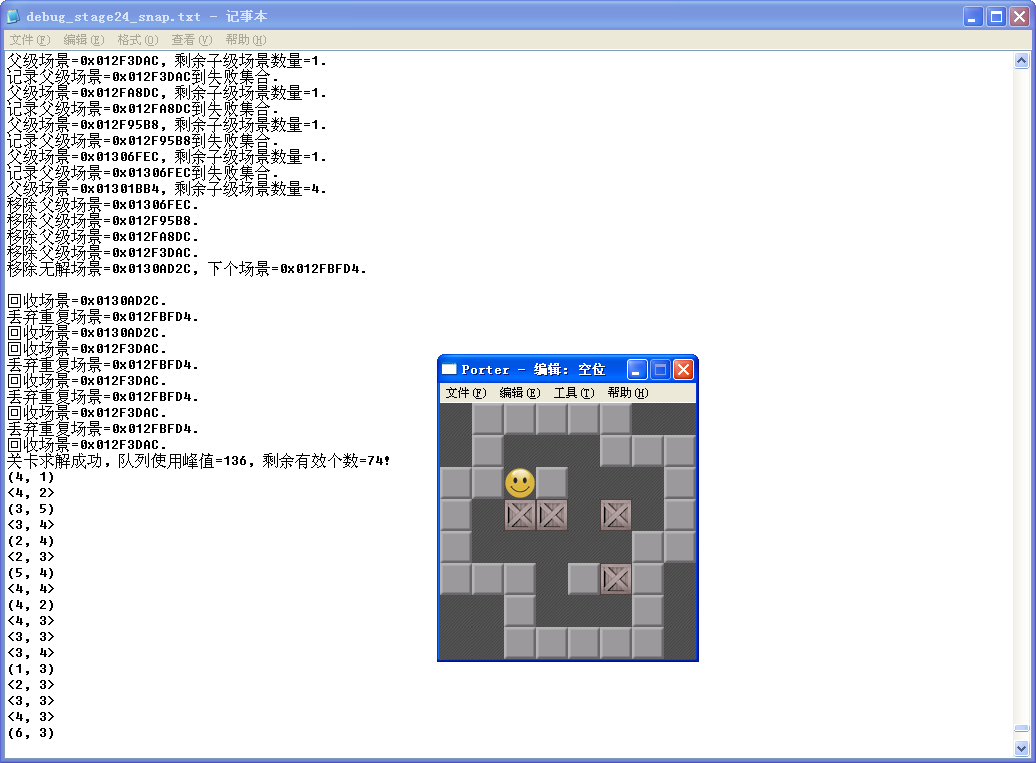
没有失败队列。在前面已有。这里再贴一次:

增加失败队列后,注意队列使用峰值。剩余值和步数比較:
问:太TM神了,还有没有?我还要,我还要。
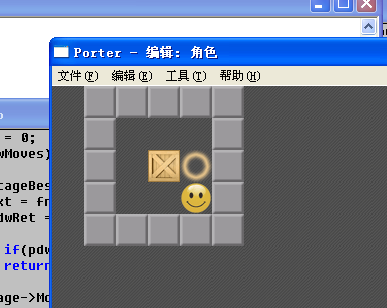
答:当我们针对一个箱子进行分析的时候,不管上下左右。总有个固定次序。比方就是上下左右。有可能最好的走法是后面的方向
得到走法列表后,依照归位数量从大到小依次生成场景。如图,假设不优化这个机制。上下左三个方向会先被生成分析。而增加这
个机制,向右的归位数量最大,先被分析,事实上就一步完毕了,也就是立马到达最优解。
问:暴走了。。还有吗?
答:留点空间给后来者发挥吧。 以下是源代码级别的优化。比方内部指针
tagStage有几个内部指针,在申请内存时一并计算分配,而不是后面再分配,动态分配在32位Windows中以4K为
单位,你申请一个字节也是4K,浪费内存。重复申请释放,过程复杂easy写错。同一时候easy产生碎片手榴弹。。。
另外。是一维数组取代若干个一维或多维数组,比方Stars。简化内存管理逻辑,详见资源包代码
再者,使用内联汇编的裸函数取代库函数。能够大幅提升效率,比方内存复制。在V32.dll中:
// 复制两个内存块, 不检測指针
void __declspec(naked) __stdcall fnCopy(void *dst, const void *src, int len)
{
// 调试时mov esi, esp, 调用完毕cmp esi, esp检查堆栈
//__asm{
// mov edi, dst ; [esp + 4]
// mov esi, src ; [esp + 8]
// mov ecx, len ; [esp + c]
// rep movsb
//}
__asm{
push esi ; 保护寄存器esi和edi, 第一个变量由[esp+4h]推移至[esp+0ch], 第二个为+10h
push edi
mov esi, [esp+10h] ; 串操作原始地址
mov edi, [esp+0ch] ; 串操作目标地址
mov ecx, [esp+14h] ; 串操作计数
and ecx, 3 ; 先复制余数
rep movsb ; 逐字节复制
mov ecx, [esp+14h]
shr ecx, 2 ; 求四的商(双字个数)
rep movsd ; 逐双字复制
pop edi
pop esi
ret 0ch ; 裸函数返回(三个參数)
}
}
当你赋值两个结构体时,编译出来事实上差点儿相同就是类似的指令,而不会调用memcpy之类的函数。
就像把比較放在循环外,有程序来控制指针,我们干嘛每次都去检測这个指针呢?
最后针对CPU和操作系统的优化,时间差点儿相同了,就不说了,Intel有专门的编译优化工具。
事实上,我仅仅是写个小礼物给莲花妹妹开心一下,写到这里。也算尽心尽力了。但愿编程之美,能带给世人很多其它的欢笑,释放很多其它的压力和痛苦
我的计算机说,反重复复的事情就TM交给我吧!!!
致佳茵 全文毕
虎胆游侠
2015-03-15 00:34:56















 7233
7233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









