






特征工程
特征是数据中抽取出来的对结果预测有用的信息,可以是文本或者数据,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,因此有必要进行特征工程,其目的就是最大限度地从原始数据中筛选出更好的特征,获取更好的训练数据,以供算法和模型使用。因为好的特征具有更强的灵活性,可以用简单的模型做训练,更可以得到优秀的结果。“工欲善其事,必先利其器”,特征工程可以理解为利其器的过程。互联网公司里大部分复杂的模型都是极少数的数据科学家在做,大多数工程师们做的事情基本是在数据仓库里搬砖,不断地做数据清洗,再者是分析业务不断地找特征。 例如,某广告部门的数据挖掘工程师,两周内可以完成一次特征迭代,一个月左右可以完成模型的小优化,来提升AUC。
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。过程包含了特征构建、特征提取、特征选择等模块:


数据采集 / 清洗 / 采样
数据采集:数据采集前需要明确采集哪些数据,一般的思路为:哪些数据对最后的结果预测有帮助?数据我们能够采集到吗?线上实时计算的时候获取是否快捷?
举例1:我现在要预测用户对商品的下单情况,或者我要给用户做商品推荐,那我需要采集什么信息呢?
-店家:店铺的评分、店铺类别……
-商品:商品评分、购买人数、颜色、材质、领子形状……
-用户:历史信息(购买商品的最低价最高价)、消费能力、商品停留时间……
数据清洗: 数据清洗也是很重要的一步,机器学习算法大多数时候就是一个加工机器,至于最后的产品如何,取决于原材料的好坏。数据清洗就是要去除脏数据,比如某些商品的刷单数据。
那么如何判定脏数据呢?
1) 简单属性判定:一个人身高3米+的人;一个人一个月买了10w的发卡。
2) 组合或统计属性判定:号称在米国却ip一直都是大陆的新闻阅读用户?你要判定一个人是否会买篮球鞋,样本中女性用户85%?
3) 补齐可对应的缺省值:不可信的样本丢掉,缺省值极多的字段考虑不用。
数据采样:采集、清洗过数据以后,正负样本是不均衡的,要进行数据采样。采样的方法有随机采样和分层抽样。但是随机采样会有隐患,因为可能某次随机采样得到的数据很不均匀,更多的是根据特征采用分层抽样。
正负样本不平衡处理办法:
正样本 >> 负样本,且量都挺大 => downsampling
正样本 >> 负样本,且量不大 =>
1)采集更多的数据
2)上采样/oversampling(比如图像识别中的镜像和旋转)
3)修改损失函数/loss function (设置样本权重)
特征处理
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。
# 实例数据集 - sklearn中的IRIS(鸢尾花)数据集 # IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米
# 其目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾)) from sklearn.datasets import load_iris #导入IRIS数据集 iris = load_iris() #特征矩阵 iris.data #目标向量 iris.target
数据预处理
通过特征提取,能得到未经处理的特征,这时的特征可能有以下问题:
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
单变量分析:先逐个对变量进行观察。对连续的变量,或者标签的变量,采用不同的方式。
- 连续变量
需要理解连续变量的中心趋势,还有变量的离散程度

可视化单个变量

单变量分析可以用来帮助解决缺失值和异常值
- 标签变量
对于标签变量要分析数据在每个维度上的分布情况,可以通过条形图展示

按不同处理方法:
无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
标准化
标准化需要计算特征的均值和标准差,公式表达为:

计算时对每个属性/列分别进行 - 将数据按属性/列减去其均值,并除以其方差。得到的结果是,对于每个属性/列来说所有数据都聚集在0附近,方差为1
方式1:使用sklearn.preprocessing.StandardScaler类对数据进行标准化,优点在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据
from sklearn.preprocessing import StandardScaler # 标准化,返回值为标准化后的数据 StandardScaler().fit_transform(iris.data)
scaler = preprocessing.StandardScaler().fit(X)
print(scaler)
StandardScaler(copy=True, with_mean=True, with_std=True)
print(scaler.mean_)
array([ 1. ..., 0. ..., 0.33...])
print(scaler.std_)
array([ 0.81..., 0.81..., 1.24...])
print(scaler.transform(X))
array([[ 0. ..., -1.22..., 1.33...], [ 1.22..., 0. ..., -0.26...], [-1.22..., 1.22..., -1.06...]])
# 可以直接使用训练集对测试集数据进行转换 scaler.transform([[-1., 1., 0.]])
array([[-2.44..., 1.22..., -0.26...]])
方式2:使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化
from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) X_scaled = preprocessing.scale(X) print(X_scaled)
array([[ 0. ..., -1.22..., 1.33...], [ 1.22..., 0. ..., -0.26...], [-1.22..., 1.22..., -1.06...]])
# 处理后数据的均值和方差 print(X_scaled.mean(axis=0))
array([ 0., 0., 0.])
print(X_scaled.std(axis=0))
array([ 1., 1., 1.])
区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:

计算时将属性缩放到一个指定的最大和最小值(通常是1-0)之间,目的包括:
1、对于方差非常小的属性可以增强其稳定性。
2、维持稀疏矩阵中为0的条目。
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler # 区间缩放,返回值为缩放到[0, 1]区间的数据 MinMaxScaler().fit_transform(iris.data)
X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) min_max_scaler = preprocessing.MinMaxScaler() X_train_minmax = min_max_scaler.fit_transform(X_train) print(X_train_minmax)
array([[ 0.5 , 0. , 1. ], [ 1. , 0.5 , 0.33333333], [ 0. , 1. , 0. ]])
# 将相同的缩放应用到测试集数据中 X_test = np.array([[ -3., -1., 4.]]) X_test_minmax = min_max_scaler.transform(X_test) print(X_test_minmax)
array([[-1.5 , 0. , 1.66666667]])
# 缩放因子等属性 print(min_max_scaler.scale_)
array([ 0.5 , 0.5 , 0.33...])
print(min_max_scaler.min_)
array([ 0. , 0.5 , 0.33...])
在构造类对象的时候也可以直接指定最大最小值的范围:feature_range=(min, max),此时应用的公式变为:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
归一化/正则化
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。其主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm、l2-norm)等于1。
p-范数的计算公式:||X||p=(|x1|p+|x2|p+...+|xn|p)1/p

该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性
标准化与归一化的区别:简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。
规则为l2的归一化公式如下:

方式1:可以使用preprocessing.normalize()函数对指定数据进行转换
X = [[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]] X_normalized = preprocessing.normalize(X, norm='l2') print(X_normalized)
array([[ 0.40..., -0.40..., 0.81...], [ 1. ..., 0. ..., 0. ...], [ 0. ..., 0.70..., -0.70...]])
方式2:可以使用processing.Normalizer()类实现对训练集和测试集的拟合和转换,使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
from sklearn.preprocessing import Normalizer #归一化,返回值为归一化后的数据 Normalizer().fit_transform(iris.data)
normalizer = preprocessing.Normalizer().fit(X) # fit does nothing print(normalizer)
Normalizer(copy=True, norm='l2')
print(normalizer.transform(X))
array([[ 0.40..., -0.40..., 0.81...], [ 1. ..., 0. ..., 0. ...], [ 0. ..., 0.70..., -0.70...]])
print(normalizer.transform([[-1., 1., 0.]]))
array([[-0.70..., 0.70..., 0. ...]])
对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:

使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer #二值化,阈值设置为3,返回值为二值化后的数据 Binarizer(threshold=3).fit_transform(iris.data)
对定性特征哑编码
由于IRIS数据集的特征皆为定量特征,故使用其目标值进行哑编码(实际上是不需要的)。
使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder #哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据 OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
缺失值计算
由于IRIS数据集没有缺失值,故对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失。
使用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
from numpy import vstack, array, nan from sklearn.preprocessing import Imputer #缺失值计算,返回值为计算缺失值后的数据 #参数missing_value为缺失值的表示形式,默认为NaN #参数strategy为缺失值填充方式,默认为mean(均值) Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))
数据变换
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的。4个特征,度为2的多项式转换公式如下:

使用preproccessing库的PolynomialFeatures类对数据进行多项式转换的代码如下:
from sklearn.preprocessing import PolynomialFeatures #多项式转换 #参数degree为度,默认值为2 PolynomialFeatures().fit_transform(iris.data)
基于单变元函数的数据变换可以使用一个统一的方式完成,使用preproccessing库的FunctionTransformer对数据进行对数函数转换的代码如下:
from numpy import log1p from sklearn.preprocessing import FunctionTransformer #自定义转换函数为对数函数的数据变换 #第一个参数是单变元函数 FunctionTransformer(log1p).fit_transform(iris.data)
按不同数据类型:
数值型
1. 幅度调整/归一化:python中会有一些函数比如preprocessing.MinMaxScaler()将幅度调整到 [0,1] 区间。
2.统计值:包括max, min, mean, std等。python中用pandas库序列化数据后,可以得到数据的统计值。

3.离散化:把连续值转成非线性数据。例如电商会有各种连续的价格表,从0.03到100元,假如以一元钱的间距分割成99个区间,用99维的向量代表每一个价格所处的区间,1.2元和1.6元的向量都是 [0,1,0,…,0]。pd.cut() 可以直接把数据分成若干段。
4.柱状分布:离散化后统计每个区间的个数做柱状图。
类别型
类别型一般是文本信息,比如颜色是红色、黄色还是蓝色,我们存储数据的时候就需要先处理数据。处理方法有:
1. one-hot编码,编码后得到哑变量。统计这个特征上有多少类,就设置几维的向量,pd.get_dummies()可以进行one-hot编码。
2. Hash编码成词向量:
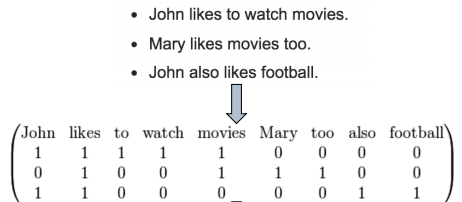
3. Histogram映射:把每一列的特征拿出来,根据target内容做统计,把target中的每个内容对应的百分比填到对应的向量的位置。优点是把两个特征联系起来。
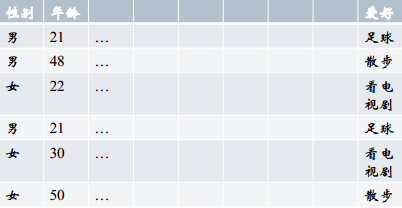
上表中,我们来统计“性别与爱好的关系”,性别有“男”、“女”,爱好有三种,表示成向量 [散步、足球、看电视剧],分别计算男性和女性中每个爱好的比例得到:男[1/3, 2/3, 0],女[0, 1/3, 2/3]。即反映了两个特征的关系。
时间型
时间型特征的用处特别大,既可以看做连续值(持续时间、间隔时间),也可以看做离散值(星期几、几月份)。
连续值
a) 持续时间(单页浏览时长)
b) 间隔时间(上次购买/点击离现在的时间)
离散值
a) 一天中哪个时间段(hour_0-23)
b) 一周中星期几(week_monday...)
c) 一年中哪个星期
d) 一年中哪个季度
e) 工作日/周末
数据挖掘中经常会用时间作为重要特征,比如电商可以分析节假日和购物的关系,一天中用户喜好的购物时间等。
文本型
1. 词袋:文本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋.
2. 把词袋中的词扩充到n-gram:n-gram代表n个词的组合。比如“我喜欢你”、“你喜欢我”这两句话如果用词袋表示的话,分词后包含相同的三个词,组成一样的向量:“我 喜欢 你”。显然两句话不是同一个意思,用n-gram可以解决这个问题。如果用2-gram,那么“我喜欢你”的向量中会加上“我喜欢”和“喜欢你”,“你喜欢我”的向量中会加上“你喜欢”和“喜欢我”。这样就区分开来了。
3. 使用TF-IDF特征:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数),IDF(t) = ln(总文档数/ 含t的文档数),TF-IDF权重 = TF(t) * IDF(t)。自然语言处理中经常会用到。
统计型
加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过平均用户多少,用户连续登录天数超过平均多少...
分位线:商品属于售出商品价格的多少分位线处
次序型:排在第几位
比例类:电商中,好/中/差评比例,你已超过全国百分之…的同学
组合特征
1. 拼接型:简单的组合特征。例如挖掘用户对某种类型的喜爱,对用户和类型做拼接。正负权重,代表喜欢或不喜欢某种类型。
- user_id&&category: 10001&&女裙 10002&&男士牛仔
- user_id&&style: 10001&&蕾丝 10002&&全棉
2. 模型特征组合:
- 用GBDT产出特征组合路径
- 组合特征和原始特征一起放进LR训练
降维(Dimension Reduction)- 特征选择(Feature Selection)
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。特征选择,就是从多个特征中,挑选出一些对结果预测最有用的特征。因为原始的特征中可能会有冗余和噪声。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- 方法:评估单个特征和结果值之间的相关程度, 排序留下Top相关的特征部分。
- 评价方式:Pearson相关系数, 互信息, 距离相关度。
- 缺点:只评估了单个特征对结果的影响,没有考虑到特征之间的关联作用, 可能把有用的关联特征误踢掉。因此工业界使用比较少。
- python包:SelectKBest指定过滤个数、SelectPercentile指定过滤百分比。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个优化问题,有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,粒子群算法PSO,DE,人工蜂群算法ABC等。
- 方法:把特征选择看做一个特征子集搜索问题, 筛选各种特征子集, 用模型评估效果。
- 典型算法:“递归特征删除算法”。
- 应用在逻辑回归的过程:用全量特征跑一个模型;根据线性模型的系数(体现相关性),删掉5-10%的弱特征,观察准确率/auc的变化;逐步进行, 直至准确率/auc出现大的下滑停止。
- python包:RFE
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
- 方法:根据模型来分析特征的重要性,主要方法位正则化,如岭回归就是在基本线性回归的过程中加入了正则项,最常见的方式为用正则化方式来做特征选择。
- 举例:最早在电商用LR做CTR预估, 在3-5亿维的系数特征上用L1正则化的LR模型。上一篇介绍了L1正则化有截断作用,剩余2-3千万的feature, 意味着其他的feature重要度不够。
- python包:feature_selection.SelectFromModel选出权重不为0的特征。
特征选择的目标大致如下:
-
- 提高预测的准确性
- 构造更快,消耗更低的预测模型
- 能够对模型有更好的理解和解释
使用sklearn中的feature_selection库来进行特征选择。
Filter
1 方差选择法使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.feature_selection import VarianceThreshold #方差选择法,返回值为特征选择后的数据 #参数threshold为方差的阈值 VarianceThreshold(threshold=3).fit_transform(iris.data)
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest from scipy.stats import pearsonr #选择K个最好的特征,返回选择特征后的数据 #第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数 #参数k为选择的特征个数 SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
<img src="https://pic2.zhimg.com/50/7bc586c806b9b8bf1e74433a2e1976bc_hd.jpg" data-rawwidth="162" data-rawheight="48" class="content_image" width="162"/>不难发现,此统计量的含义即自变量对因变量的相关性。
用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 #选择K个最好的特征,返回选择特征后的数据 SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
<img src="https://pic3.zhimg.com/50/6af9a077b49f587a5d149f5dc51073ba_hd.jpg" data-rawwidth="274" data-rawheight="50" class="content_image" width="274"/>
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest from minepy import MINE #由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5 def mic(x, y): m = MINE() m.compute_score(x, y) return (m.mic(), 0.5) #选择K个最好的特征,返回特征选择后的数据 SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
5 信息增益(Information gain)
决策树中,ID3算法是以信息熵和信息增益作为衡量标准来进行特征选择,以构建分类算法
1、信息熵(Entropy)
熵的概念主要是指信息的混乱程度,变量的不确定性越大,熵的值也就越大,熵的公式可以表示为:

其中p(ui)=|ui|/|S|,p(ui)为类别在样本中出现的概率。
2、信息增益(Information gain)
信息增益指的是划分前后熵的变化,可以用下面的公式表示:

其中,A表示样本的属性,Value(A)是属性A所有的取值集合。V是A的其中一个属性值,SV是S中A的值为V的样例集合。
Wrapper
递归特征消除法(Recursive feature elimination algorithm)递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression #递归特征消除法,返回特征选择后的数据 #参数estimator为基模型 #参数n_features_to_select为选择的特征个数 RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
Embedded
1 基于惩罚项的特征选择法使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.linear_model import LogisticRegression #带L1惩罚项的逻辑回归作为基模型的特征选择 SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
实际上,L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故可结合L2惩罚项来优化。
具体操作为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型:
from sklearn.linear_model import LogisticRegression class LR(LogisticRegression): def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1): #权值相近的阈值 self.threshold = threshold LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight=class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs) #使用同样的参数创建L2逻辑回归 self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight = class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs) def fit(self, X, y, sample_weight=None): #训练L1逻辑回归 super(LR, self).fit(X, y, sample_weight=sample_weight) self.coef_old_ = self.coef_.copy() #训练L2逻辑回归 self.l2.fit(X, y, sample_weight=sample_weight) cntOfRow, cntOfCol = self.coef_.shape #权值系数矩阵的行数对应目标值的种类数目 for i in range(cntOfRow): for j in range(cntOfCol): coef = self.coef_[i][j] #L1逻辑回归的权值系数不为0 if coef != 0: idx = [j] #对应在L2逻辑回归中的权值系数 coef1 = self.l2.coef_[i][j] for k in range(cntOfCol): coef2 = self.l2.coef_[i][k] #在L2逻辑回归中,权值系数之差小于设定的阈值,且在L1中对应的权值为0 if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0: idx.append(k) #计算这一类特征的权值系数均值 mean = coef / len(idx) self.coef_[i][idx] = mean return self
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel #带L1和L2惩罚项的逻辑回归作为基模型的特征选择 #参数threshold为权值系数之差的阈值 SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import GradientBoostingClassifier #GBDT作为基模型的特征选择 SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
降维(Dimension Reduction)- 特征抽取\特征提取(Feature Extraction)
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,过高的维度会严重影响计算效率并造成数据稀疏,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。
特征提取,是将原始特征转换为一组具有明显物理意义(Gabor、几何特征[角点、不变量]、纹理[LBP HOG])或者统计意义或核的特征。
特征选择和特征提取的区别:前者只去掉原本特征里和结果预测关系不大的,目标是从原始的d个特征中选择k个特征(原始空间的子集);后者做特征的计算组合构成新特征,目标是根据原始的d个特征的组合形成k个新的特征,即将数据从d维空间映射到k维空间(改变了原来的特征空间)。
特征选择和特征提取的共同点:都属于降维,都是试图去减少特征数据集中的属性(或者称为特征)的数目,都是尽可能保持原始数据中包含的信息。
常见的降维(特征提取)方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)、线性判别分析(LDA)、奇异值分解(SVD)等,线性判别分析本身也是一个分类模型。
PCA vs LDA:PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
PCA VS ICA:PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,如果一个模型的方差很大,那就说明模型不稳定了。但是对于用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。

ICA是找出构成信号的相互独立部分(不需要正交),对应高阶统计量分析。ICA理论认为用来观测的混合数据阵X是由独立元S经过A线性加权获得。ICA理论的目标就是通过X求得一个分离矩阵W,使得W作用在X上所获得的信号Y是独立源S的最优逼近,该关系可以通过下式表示:
Y=WX=WAS,A=W−1Y=WX=WAS,A=W−1
ICA相比与PCA更能刻画变量的随机统计特性,且能抑制高斯噪声。

PCA vs SVD:PCA本质上是去中心化的SVD,这可以看出PCA内在上与SVD的联系。PCA是先将原始数据X的每一个样本,都减去所有样本的平均值,然后再用每一维的标准差进行归一化。假如原始矩阵X的每一行对应着每一个样本,列对应着相应的特征,那么上述去中心化的步骤对应着先所有行求平均值,得到的是一个向量,然后再将每一行减去这个向量,接着,针对每一列求标准差,然后再把每一列的数据除以这个标准差。这样得到的即是去中心化的矩阵。
线性特征提取
1 主成分分析法(PCA)思想:寻找表示数据分布的最优子空间(降维,可以去相关)。
其实就是取协方差矩阵前s个最大特征值对应的特征向量构成映射矩阵,对数据进行降维。

使用decomposition库的PCA类选择特征的代码如下:
from sklearn.decomposition import PCA #主成分分析法,返回降维后的数据 #参数n_components为主成分数目 PCA(n_components=2).fit_transform(iris.data)
思想:寻找可分性判据最大的子空间。
用到了Fisher的思想,即寻找一个向量,使得降维后类内散度最小,类间散度最大;其实就是取S−1wSbSw−1Sb前s个特征值对应的特征向量构成映射矩阵,对数据进行处理。

使用lda库的LDA类选择特征的代码如下:
from sklearn.lda import LDA #线性判别分析法,返回降维后的数据 #参数n_components为降维后的维数 LDA(n_components=2).fit_transform(iris.data, iris.target)
Hua Yu and JieYang, A direct LDA algorithm for high - dimensional data with application to face recognition, Pattern Recognition Volume 34, Issue 10, October 2001,pp.2067- 2070
3 奇异值分解(SVD)
SVD本质上是一种数学的方法, 不属于机器学习算法,但它在机器学习领域里有非常广泛的应用
4 独立成分分析(ICA)
思想:PCA是将原始数据降维,并提取不相关的部分;ICA是将原始数据降维并提取出相互独立的属性;寻找一个线性变换z=Wxz=Wx,使得z的各个分量间的独立性最大,I(z)=Elnp(z)p(z1)...p(zd)I(z)=Elnp(z)p(z1)...p(zd)

A. Hyvarinenand E. Oja. Independent Component Analysis: Algorithms and Applications. Neural Networks, 13(4- 5):411 -430, 200
5 二维PCA
J. Yang, D. Zhang, A.F. Frangi , and J.Y. Yang, Two - dimensional PCA: a new approach to appearance - based face representation and recognition, IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 26, no. 1, pp. 131- 137, Jan. 2004
6 典型对应分析(CCA,Canonical Correlaton Analysis)
思想:找到两组基,使得两组数据在这两组基上的投影相关性最大。
用来描述两个高维变量之间的线性关系
用PLS(Partial Least Squares)来求解
R. H. David, S. Sandor and S.- T. John,Canonical correlation analysis: An overview with application to learning methods, Technical Report, CSD - TR- 03-02,2003
非线性特征提取
1 Kernel PCA
B. Scholkopf , A. Smola , and K.R. Muller. Nonlinear component analysis as a kernel eigenvalue problem, Neural Computation, 10(5): 1299- 1319, 1998
2 Kernel FDA
Mika, S., Ratsch , G., Weston, J., Scholkopf , B., Mullers, K.R., Fisher discriminantanalysis with kernels, Neural Networks for Signal Processing IX, Proceedings of the IEEE Signal Processing Society Workshop, pp. 41 – 48, 1999
3 Manifold Learning(流形学习)
找到流形上的低维坐标。
利用流形学上的局部结构进行降维的方法有:ISOMAP、LLE、Laplacian Eigenmap、LPP
J. B. Tenenbaum , V. de Silva, and J. C. Langford, A global geometric framework for nonlinear dimensionality reduction, Science, 290, pp. 2319 - 2323, 2000
Sam T. Roweis , and Lawrence K. Saul, Nonlinear Dimensionality Reduction by Locally Linear Embedding,Science 22 December 2000
Mikhail Belkin , Partha Niyogi ,Laplacian Eigenmaps for Dimensionality Reduction and Data Representation , Computation , 200
Xiaofei He, Partha Niyogi, Locality Preserving Projections, Advances in Neural Information Processing Systems 16 (NIPS 2003), Vancouver, Canada, 2003
准则性质
特征提取与特征选择的准则需要满足:
- 单调性:J(x1,...,xn)<=J(x1,...,xs,xs+1)J(x1,...,xn)<=J(x1,...,xs,xs+1)
- 可加性:J(x1,...,xs)=∑iJ(xi)J(x1,...,xs)=∑iJ(xi)
- 不变性:J(x)=J(AX)J(x)=J(AX)线性变换下
- 度量性:Jij>=0,Jij=Jji,Jij=0ifandonlyifi=jJij>=0,Jij=Jji,Jij=0ifandonlyifi=j
- 与错误率的上界或者下届有单调关系,或者说本身就是错误率的上界或者下届
大致可分为三类:
1 基于欧式距离的准则
- 整体散度 St=12N2∑i,j(xi−xj)(xi−xj)‘=Sw+SbSt=12N2∑i,j(xi−xj)(xi−xj)‘=Sw+Sb
- PCA:tr(St)tr(St)
- LDA:tr(Sb)/tr(Sw)tr(Sb)/tr(Sw)
- 基于距离的准侧概念直观,计算方便,但与错误率没有直接关系
2 基于概率距离的准则
- Bhattacharyya距离 JB=−ln∫Ω[p(⃗a|w1)p(⃗a|w2)]12d⃗xJB=−ln∫Ω[p(a→|w1)p(a→|w2)]12dx→
- Chernoff界限 JC=−ln∫Ωp(⃗a|w1)sp(⃗a|w2)1−sd⃗x,0<s<1JC=−ln∫Ωp(a→|w1)sp(a→|w2)1−sdx→,0<s<1
- KL散度 Iij(⃗x)=Ei[lnp(⃗x|wi)p(⃗x|wj)]Iij(x→)=Ei[lnp(x→|wi)p(x→|wj)]
3 基于熵的准则
- 熵函数 H=JC[P(w1|x),...,P(wc|x)]H=JC[P(w1|x),...,P(wc|x)]
- 香农熵 J1C=−∑Ci=1P(wi|x)log2P(wi|x)JC1=−∑i=1CP(wi|x)log2P(wi|x)
- 平方熵 J2C=2[1−∑ci=1P2(wi|x)]JC2=2[1−∑i=1cP2(wi|x)]
- 广义熵 JaC[P(w1|x),...,P(wc|x)]JCa[P(w1|x),...,P(wc|x)]
基于Python进行特征选择
# 数据集:Titanic数据集 # 通过特征筛选来寻找最佳的特征组合,并且达到提高预测准确性的目标 # coding=utf-8 import pandas as pd from sklearn.cross_validation import train_test_split from sklearn.feature_extraction import DictVectorizer from sklearn.tree import DecisionTreeClassifier from sklearn import feature_selection from sklearn.cross_validation import cross_val_score import numpy as np import pylab as pl #-------------download data titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt') #-------------sperate data and target y=titanic['survived'] X=titanic.drop(['row.names','name','survived'],axis=1) #-------------fulfill lost data with mean value X['age'].fillna(X['age'].mean(),inplace=True) X.fillna('UNKNOWN',inplace=True) #-------------split data,25% for test X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #-------------feature vectorization vec=DictVectorizer() X_train=vec.fit_transform(X_train.to_dict(orient='record')) X_test=vec.transform(X_test.to_dict(orient='record')) #------------- print 'Dimensions of handled vector',len(vec.feature_names_) #-------------use DTClassifier to predict and measure performance dt=DecisionTreeClassifier(criterion='entropy') dt.fit(X_train,y_train) print dt.score(X_test,y_test) #-------------selection features ranked in the front 20%,use DTClassifier with the same config to predict and measure performance fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=20) X_train_fs=fs.fit_transform(X_train,y_train) dt.fit(X_train_fs,y_train) X_test_fs=fs.transform(X_test) print dt.score(X_test_fs,y_test) percentiles=range(1,100,2) results=[] for i in percentiles: fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=i) X_train_fs=fs.fit_transform(X_train,y_train) scores=cross_val_score(dt,X_train_fs,y_train,cv=5) results=np.append(results,scores.mean()) print results #-------------find feature selection percent with the best performance opt=int(np.where(results==results.max())[0]) print 'Optimal number of features',percentiles[opt] #TypeError: only integer scalar arrays can be converted to a scalar index #transfer list to array #print 'Optimal number of features',np.array(percentiles)[opt] #-------------use the selected features and the same config to measure performance on test datas fs=feature_selection.SelectPercentile(feature_selection.chi2,percentile=7) X_train_fs=fs.fit_transform(X_train,y_train) dt.fit(X_train_fs,y_train) X_test_fs=fs.transform(X_test) print dt.score(X_test_fs,y_test) pl.plot(percentiles,results) pl.xlabel('percentiles of features') pl.ylabel('accuracy') pl.show()
# -*- coding: utf-8 -*- #过滤式特征选择 #根据方差进行选择,方差越小,代表该属性识别能力很差,可以剔除 from sklearn.feature_selection import VarianceThreshold x=[[100,1,2,3], [100,4,5,6], [100,7,8,9], [101,11,12,13]] selector=VarianceThreshold(1) #方差阈值值, selector.fit(x) selector.variances_ #展现属性的方差 selector.transform(x)#进行特征选择 selector.get_support(True) #选择结果后,特征之前的索引 selector.inverse_transform(selector.transform(x)) #将特征选择后的结果还原成原始数据 #被剔除掉的数据,显示为0 #单变量特征选择 from sklearn.feature_selection import SelectKBest,f_classif x=[[1,2,3,4,5], [5,4,3,2,1], [3,3,3,3,3], [1,1,1,1,1]] y=[0,1,0,1] selector=SelectKBest(score_func=f_classif,k=3)#选择3个特征,指标使用的是方差分析F值 selector.fit(x,y) selector.scores_ #每一个特征的得分 selector.pvalues_ selector.get_support(True) #如果为true,则返回被选出的特征下标,如果选择False,则 #返回的是一个布尔值组成的数组,该数组只是那些特征被选择 selector.transform(x) #包裹时特征选择 from sklearn.feature_selection import RFE from sklearn.svm import LinearSVC #选择svm作为评定算法 from sklearn.datasets import load_iris #加载数据集 iris=load_iris() x=iris.data y=iris.target estimator=LinearSVC() selector=RFE(estimator=estimator,n_features_to_select=2) #选择2个特征 selector.fit(x,y) selector.n_features_ #给出被选出的特征的数量 selector.support_ #给出了被选择特征的mask selector.ranking_ #特征排名,被选出特征的排名为1 #注意:特征提取对于预测性能的提升没有必然的联系,接下来进行比较; from sklearn.feature_selection import RFE from sklearn.svm import LinearSVC from sklearn import cross_validation from sklearn.datasets import load_iris #加载数据 iris=load_iris() X=iris.data y=iris.target #特征提取 estimator=LinearSVC() selector=RFE(estimator=estimator,n_features_to_select=2) X_t=selector.fit_transform(X,y) #切分测试集与验证集 x_train,x_test,y_train,y_test=cross_validation.train_test_split(X,y, test_size=0.25,random_state=0,stratify=y) x_train_t,x_test_t,y_train_t,y_test_t=cross_validation.train_test_split(X_t,y, test_size=0.25,random_state=0,stratify=y) clf=LinearSVC() clf_t=LinearSVC() clf.fit(x_train,y_train) clf_t.fit(x_train_t,y_train_t) print('origin dataset test score:',clf.score(x_test,y_test)) #origin dataset test score: 0.973684210526 print('selected Dataset:test score:',clf_t.score(x_test_t,y_test_t)) #selected Dataset:test score: 0.947368421053 import numpy as np from sklearn.feature_selection import RFECV from sklearn.svm import LinearSVC from sklearn.datasets import load_iris iris=load_iris() x=iris.data y=iris.target estimator=LinearSVC() selector=RFECV(estimator=estimator,cv=3) selector.fit(x,y) selector.n_features_ selector.support_ selector.ranking_ selector.grid_scores_ #嵌入式特征选择 import numpy as np from sklearn.feature_selection import SelectFromModel from sklearn.svm import LinearSVC from sklearn.datasets import load_digits digits=load_digits() x=digits.data y=digits.target estimator=LinearSVC(penalty='l1',dual=False) selector=SelectFromModel(estimator=estimator,threshold='mean') selector.fit(x,y) selector.transform(x) selector.threshold_ selector.get_support(indices=True) #scikitlearn提供了Pipeline来讲多个学习器组成流水线,通常流水线的形式为:将数据标准化, #--》特征提取的学习器————》执行预测的学习器,除了最后一个学习器之后, #前面的所有学习器必须提供transform方法,该方法用于数据转化(如归一化、正则化、 #以及特征提取 #学习器流水线(pipeline) from sklearn.svm import LinearSVC from sklearn.datasets import load_digits from sklearn import cross_validation from sklearn.linear_model import LogisticRegression from sklearn.pipeline import Pipeline def test_Pipeline(data): x_train,x_test,y_train,y_test=data steps=[('linear_svm',LinearSVC(C=1,penalty='l1',dual=False)), ('logisticregression',LogisticRegression(C=1))] pipeline=Pipeline(steps) pipeline.fit(x_train,y_train) print('named steps',pipeline.named_steps) print('pipeline score',pipeline.score(x_test,y_test)) if __name__=='__main__': data=load_digits() x=data.data y=data.target test_Pipeline(cross_validation.train_test_split(x,y,test_size=0.25, random_state=0,stratify=y))















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









