






- 一、限流思路 -
常见的系统服务限流模式有:熔断、服务降级、延迟处理和特殊处理四种。
1、熔断
将熔断措施嵌入到系统设计中,当系统出现问题时,若短时间内无法修复,系统会自动开启熔断开关,拒绝流量访问,避免大流量对后端的过载请求。
除此之外,系统还能够动态监测后端程序的修复情况,当程序已恢复稳定时,就关闭熔断开关,恢复正常服务。
常见的熔断组件有 Hystrix 以及阿里的 Sentinel。
在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。
熔断机制的注解是@HystrixCommand,Hystrix会找有这个注解的方法,并将这类方法关联到和熔断器连在一起的代理上。
2、服务降级
将系统的所有功能服务进行一个分级,当系统出现问题需要紧急限流时,可将不是那么重要的功能进行降级处理,停止服务,保障核心功能正常运作。
例如在电商平台中,如果突发流量激增,可临时将商品评论、积分等非核心功能进行降级,停止这些服务,释放出机器和 CPU 等资源来保障用户正常下单。
这些降级的功能服务可以等整个系统恢复正常后,再来启动,进行补单/补偿处理。
除了功能降级以外,还可以采用不直接操作数据库,而全部读缓存、写缓存的方式作为临时降级方案。
熔断&降级
-
相同点:
目标一致 都是从可用性和可靠性出发,为了防止系统崩溃;
用户体验类似,最终都让用户体验到的是某些功能暂时不可用。
-
不同点:
触发原因不同,服务熔断一般是某个服务(下游服务,即被调用的服务)故障引起;
-
而服务降级一般是从整体负荷考虑。
3、延迟处理
延迟处理需要在系统的前端设置一个流量缓冲池,将所有的请求全部缓冲进这个池子,不立即处理。后端真正的业务处理程序从这个池子中取出请求依次处理,常见的可以用队列模式来实现。
这就相当于用异步的方式去减少了后端的处理压力,但是当流量较大时,后端的处理能力有限,缓冲池里的请求可能处理不及时,会有一定程度延迟。
4、特权处理
这个模式需要将用户进行分类,通过预设的分类,让系统优先处理需要高保障的用户群体,其它用户群的请求就会延迟处理或者直接不处理。

- 二、限流算法 -
常见的限流算法有三类:计数器算法、漏桶算法和令牌桶算法。
1、计数器算法
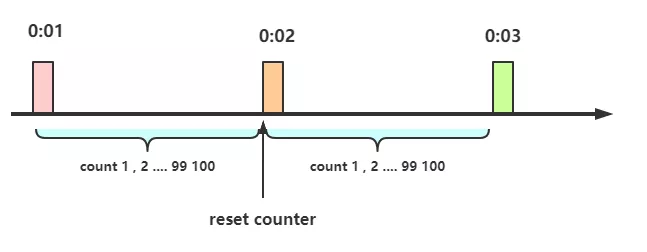
计数器算法是限流算法中最简单最容易的一种,如上图每分钟只允许100个请求,第一个请求进去的时间为startTime,在startTime + 60s内只允许100个请求 。
当60s内超过十个请求后,则拒绝请求;不超过的允许请求,到第60s 则重新设置时间。
package com.todaytalents.rcn.parser.util;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 计数器实现限流:
* 每分钟只允许100个请求,第一个请求进去的时间为startTime,在startTime + 60s内只允许100个请求
* 60s内超过100个请求后,则拒绝请求,
* 不超过,允许请求,到第60s 重新设置时间。
*
* @author: Arafat
* @date: 2021/12/29
* @company: 澳B99999
**/
public class CalculatorCurrentLimiting {
/**
* 限流个数
*/
private int maxCount = 100;
/**
* 指定的时间内:秒
*/
private long specifiedTime = 60;
/**
* 原子类计数器
*/
private AtomicInteger atomicInteger = new AtomicInteger(0);
/**
* 起始时间
*/
private long startTime = System.currentTimeMillis();
/**
* @param maxCount 限流个数
* @param specifiedTime 指定的时间内
* @return 返回true 不限流,返回false 则限流
*/
public boolean limit(int maxCount, int specifiedTime) {
atomicInteger.addAndGet(1);
if (1 == atomicInteger.get()) {
startTime = System.currentTimeMillis();
atomicInteger.addAndGet(1);
return true;
}
// 超过时间间隔,重新开始计数
if (System.currentTimeMillis() - startTime > specifiedTime * 1000) {
startTime = System.currentTimeMillis();
atomicInteger.set(1);
return true;
}
// 还在时间间隔内,检查是否超过限流数量
if (maxCount < atomicInteger.get()) {
return false;
}
return true;
}
}利用计数器算法比如要求某一个接口,1分钟内的请求不能超过100次。
可以在开始时设置一个计数器,每次请求,该计数器+1;如果该计数器的值大于10并且与第一次请求的时间间隔在1分钟内,那么说明请求过多则限制请求直接返回或不处理,反之。
如果该请求与第一次请求的时间间隔大于1分钟,并且该计数器的值还在限流范围内,那么重置该计数器。
计算器算法虽然简单,但它有一个狠致命的临界问题。
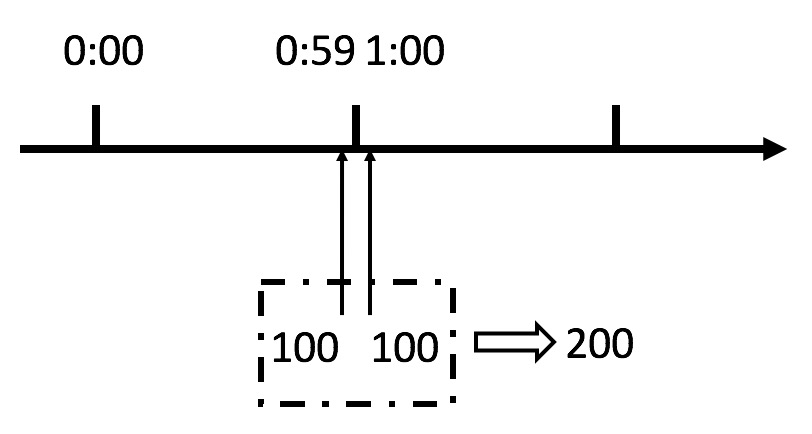
上图可以看出假若有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且在1:00时,又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。
而上述计数器算法规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,而用户通过在时间窗口的重置节点处突发请求,可以瞬间超过限流的速率限制,这个漏洞可能会瞬间压垮服务应用。
上述漏洞问题其实是因为计数器限流算法统计的精度太低,可以借助滑动窗口算法将临界问题的影响降低。
2、滑动窗口
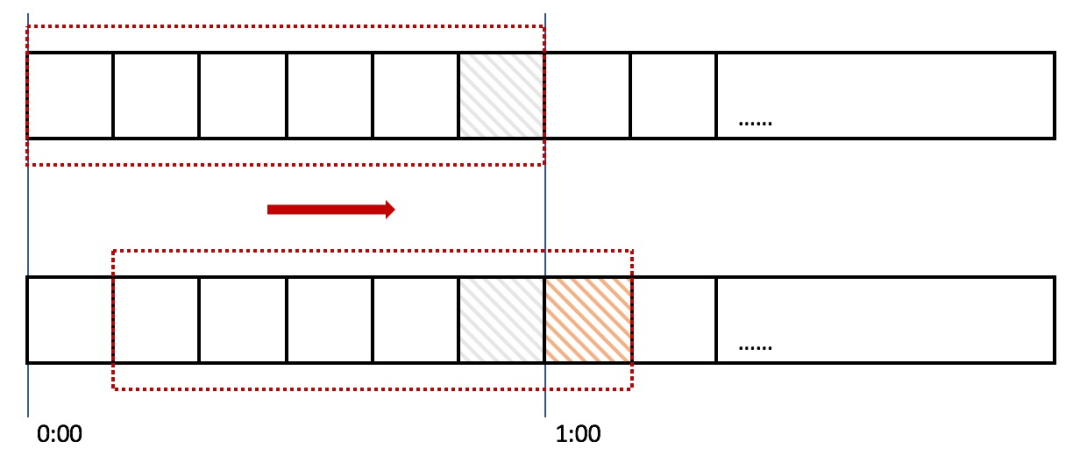
上图中,整个红色的矩形框表示一个时间窗口。在计数器算法限流的例子中,一个时间窗口就是一分钟。在这里将时间窗口进行划分,比如图中,将滑动窗口划成了6格,每格代表的是10秒钟。每过10秒钟,时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
那么滑动窗口怎么解决刚才的临界问题的呢?
上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格子中。当时间到达1:00时,窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触发了限流。
经比较发现发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。所以,当滑动窗口的格子划分的越多,则滑动窗口的滚动就越平滑,限流的统计就会越精确。
3、漏桶算法
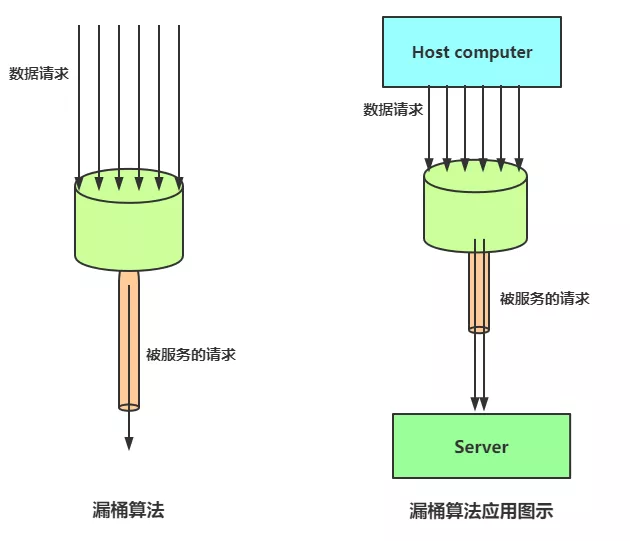
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会超过桶可接纳的容量时直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
使用漏桶算法,可以保证接口会以一个常速速率来处理请求,所以漏桶算法必定不会出现临界问题。
漏桶算法实现类:
import java.util.concurrent.atomic.AtomicInteger;
/**
* 漏桶算法:把水滴看成请求
*
* @author: Arafat
* @date: 2021/12/29
**/
public class LeakyBucket {
/**
* 桶的容量
*/
private int capacity = 100;
/**
* 桶剩余的水滴的量(初始化的时候桶为空)
*/
private AtomicInteger water = new AtomicInteger(0);
/**
* 水滴的流出的速率 每1000毫秒流出1滴
*/
private int leakRate;
/**
* 第一次请求之后,木桶在这个时间点开始漏水
*/
private long leakTimeStamp;
public LeakyBucket(int leakRate) {
this.leakRate = leakRate;
}
public boolean acquire() {
// 如果是空桶,就用当前时间作为桶开始漏出的时间
if (water.get() == 0) {
leakTimeStamp = System.currentTimeMillis();
water.addAndGet(1);
return capacity == 0 ? false : true;
}
// 先执行漏水,计算剩余水量
int waterLeft = water.get() - ((int) ((System.currentTimeMillis() - leakTimeStamp) / 1000)) * leakRate;
water.set(Math.max(0, waterLeft));
// 重新更新leakTimeStamp
leakTimeStamp = System.currentTimeMillis();
// 尝试加水,并且水还未满
if ((water.get()) < capacity) {
water.addAndGet(1);
return true;
} else {
// 水满,拒绝加水,直接溢出
return false;
}
}
}使用漏桶限流:
/**
* @author Arafat
*/
@Slf4j
@RestController
@AllArgsConstructor
@RequestMapping("/test")
public class TestController {
/**
* 漏桶:水滴的漏出速率是每秒 1 滴
*/
private LeakyBucket leakyBucket = new LeakyBucket(1);
private UserService userService;
/**
* 漏桶限流
*
* @return
*/
@RequestMapping("/searchUserInfoByLeakyBucket")
public Object searchUserInfoByLeakyBucket() {
// 限流判断
boolean acquire = leakyBucket.acquire();
if (!acquire) {
log.info("请您稍后再试!");
return Reply.success("请您稍后再试!");
}
// 若没有达到限流的要求,直接调用接口查询
return Reply.success(userService.search());
}
}漏桶算法的两个优点:
-
削峰:有大量流量进入时,会发生溢出,从而限流保护服务可用。
-
缓冲:不至于直接请求到服务器,缓冲压力,消费速度固定,因为计算性能固定。
4、令牌桶算法
令牌桶算法思想:以固定速率产生令牌,放入令牌桶,每次用户请求都得申请令牌,令牌不足则拒绝请求或等待。
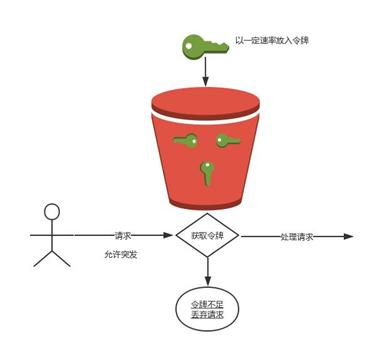
上图,令牌桶算法会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 令牌桶算法限流
*
* @author: Arafat
* @date: 2021/12/30
**/
public class TokensLimiter {
/**
* 最后一次令牌发放时间
*/
public long timeStamp = System.currentTimeMillis();
/**
* 桶的容量
*/
public int capacity = 10;
/**
* 令牌生成速度10/s
*/
public int rate = 10;
/**
* 当前令牌数量
*/
public int tokens ;
/**
* 周期性线程池
*/
private ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
/**
* 线程池每0.5s发送随机数量的请求,
* 每次请求计算当前的令牌数量,
* 请求令牌数量超出当前令牌数量,则限流。
*/
public void acquire() {
scheduledExecutorService.scheduleWithFixedDelay(() -> {
long now = System.currentTimeMillis();
// 当前令牌数
tokens = Math.min(capacity, (int) (tokens + (now - timeStamp) * rate) / 1000);
//每隔0.5秒发送随机数量的请求
int permits = (int) (Math.random() * 9) + 1;
System.out.println("请求令牌数:" + permits + ",当前令牌数:" + tokens);
timeStamp = now;
if (tokens < permits) {
// 若不到令牌,则拒绝
System.out.println("限流了");
} else {
// 还有令牌,领取令牌
tokens -= permits;
System.out.println("剩余令牌=" + tokens);;
}
}, 1000, 500, TimeUnit.MILLISECONDS);
}
public static void main(String[] args) {
TokensLimiter tokensLimiter = new TokensLimiter();
tokensLimiter.acquire();
}
}令牌桶算法默认从桶里移除令牌是不需要耗费时间的,如果给移除令牌设置一个延时时间,那么实际上又采用了漏桶算法的思路。
至于临界问题的场景,在0:59秒的时候,由于桶内积满了100个token,所以这100个请求可以瞬间通过。但是由于token是以较低的速率填充的,所以在1:00的时候,桶内的token数量不可能达到100个,那么此时不可能再有100个请求通过。所以令牌桶算法可以很好地解决临界问题。
漏桶与令牌桶算法的区别
-
主要区别在于“漏桶算法”能够强行限制数据的传输速率,而“令牌桶算法”在能够限制数据的平均传输速率外,还允许某种程度的突发传输。
-
在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
-
令牌桶算法由于实现简单,且允许某些流量的突发,对用户友好,所以被业界采用地较多。
-
具体情况具体分析,只有最合适的算法,没有最优的算法。
基于谷歌RateLimiter实现限流
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法(Token Bucket)来完成限流,非常易于使用。RateLimiter经常用于限制对一些物理资源或者逻辑资源的访问速率,它支持两种获取permits接口,一种是如果拿不到立刻返回false(tryAcquire()),另一种会阻塞等待一段时间看能不能拿到(tryAcquire(long timeout, TimeUnit unit))。
import com.google.common.util.concurrent.RateLimiter;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
/**
* @author Arafat
*/
@Slf4j
@RestController
@AllArgsConstructor
@RequestMapping("/test")
public class TestController {
/**
* 每秒钟放入n个令牌,相当于每秒只允许执行n个请求
* n = 1
* n == 5
*/
//private static final RateLimiter RATE_LIMITER = RateLimiter.create(1);
private static final RateLimiter RATE_LIMITER = RateLimiter.create(5);
public static void main(String[] args) {
// 每秒中限制1个请求 0:表示等待超时时间,设置0表示不等待,直接拒绝请求
boolean tryAcquire = RATE_LIMITER.tryAcquire(0, TimeUnit.SECONDS);
// false表示没有获取到token
if (!tryAcquire) {
System.out.println("现在抢购的人数过多,请稍等一下下哦!");
}
// tryAcquire 模拟有20个请求
for (int i = 0; i < 20; i++) {
/**
* 尝试从令牌桶中获取令牌,
* 若获取不到则等待300毫秒看能不能获取到
*/
boolean request = RATE_LIMITER.tryAcquire(300, TimeUnit.MILLISECONDS);
if (request) {
// 获取成功,执行相应逻辑
handle(i);
}
}
// acquire 模拟有20个请求
for (int i = 0; i < 20; i++) {
// 从令牌桶中获取一个令牌,若没有获取到会阻塞直到获取到为止,所以所有的请求都会被执行
RATE_LIMITER.acquire();
// 获取成功,执行相应逻辑
handle(i);
}
}
private static void handle(int i) {
System.out.println("第 " + i + " 次请求OK~~~");
}
}
- 三、集群限流 -
前面几种算法都属于单机限流的范畴,但简单的单机限流仍无法满足复杂的场景。比如为了限制某个资源被每个用户或者商户的访问次数,5s只能访问2次,或者一天只能调用1000次,这种场景单机限流是无法实现的,这时就需要通过集群限流进行实现。
可以使用Redis实现集群限流,大概思路是每次有相关操作的时候,就向redis服务器发送一个incr命令。
redisOperations.opsForValue().increment()比如需要限制某个用户访问某个详情/details接口的次数,只需要拼接用户id和接口名,加上当前服务名的前缀作为redis的key,每次该用户访问此接口时,只需要对这个key执行incr命令,再这个key带上过期时间,就可以实现指定时间的访问频率。















 3169
3169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









