







 API接口是应用程序编程接口,用于不同系统间的交互。在电商领域,item_get接口用于获取商品详情,如淘宝、1688、suning和抖音的商品。请求参数包括商品ID和是否获取促销价,响应通常以JSON格式返回。
API接口是应用程序编程接口,用于不同系统间的交互。在电商领域,item_get接口用于获取商品详情,如淘宝、1688、suning和抖音的商品。请求参数包括商品ID和是否获取促销价,响应通常以JSON格式返回。
API接口是什么? API
API全称是:Application Programming Interface,即:应用程序接口。开发人员可以使用这些API接口进行编程开发,而又无需访问源码,或理解内部工作机制的细节。
比较常见的现实场景是,在开发安卓应用时需要使用到安卓系统提供的API,在进行Windows桌面应用开发时需要用到微软系统提供的API,在进行微信小程序开发时可使用微信开放接口API。
更为常见的是,API接口很可能是远程的服务端API,其背后采用Java、PHP、C#、Pyhon、C/C++、Ruby、Scala等一种或多种后端语言开发搭建,提供了数据存储、通讯、各类服务等功能。一般是使用HTTP协议进行通讯,使用JSON格式序列化返回接口结果和数据。

电商商品详情api接口有哪些?

item_get - 获得淘宝商品详情
item_get - 获得1688商品详情
item_get - 获得suning商品详情
item_get - 获得抖音商品详情
item_get-获得淘宝商品详情
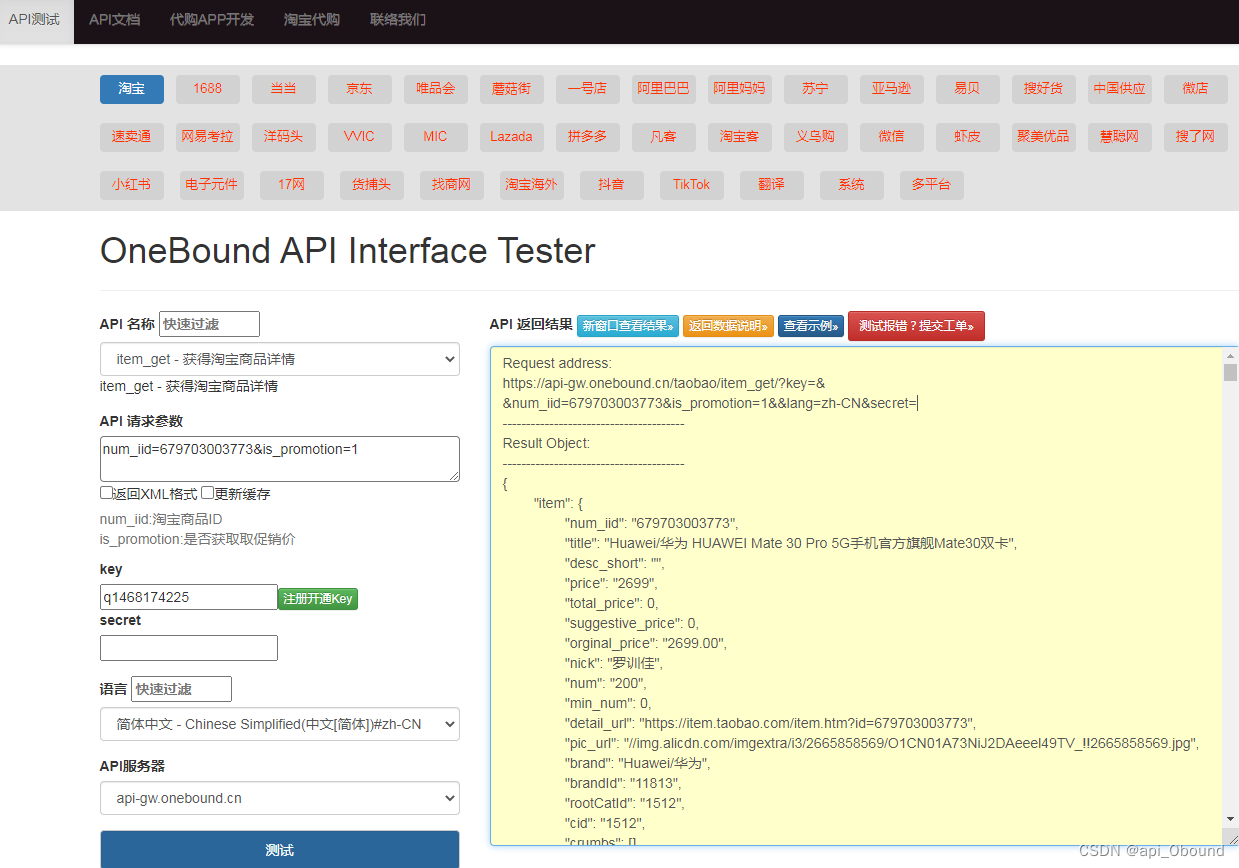
请求参数
请求参数:num_iid=520813250866&is_promotion=1
参数说明:num_iid:淘宝商品ID
is_promotion:是否获取取促销价
响应示例
Request address:
https://api-gw.onebound.cn/taobao/item_get/?key=&
&num_iid=679703003773&is_promotion=1&&lang=zh-CN&secret=
---------------------------------------
Result Object:
---------------------------------------
{
"item": {
"num_iid": "679703003773",
"title": "Huawei/华为 HUAWEI Mate 30 Pro 5G手机官方旗舰Mate30双卡",
"desc_short": "",
"price": "2699",
"total_price": 0,
"suggestive_price": 0,
"orginal_price": "2699.00",
"nick": "罗训佳",
"num": "200",
"min_num": 0,
"detail_url": "https://item.taobao.com/item.htm?id=679703003773",
"pic_url": "//img.alicdn.com/imgextra/i3/2665858569/O1CN01A73NiJ2DAeeel49TV_!!2665858569.jpg",
"brand": "Huawei/华为",
"brandId": "11813",
"rootCatId": "1512",
"cid": "1512",
"crumbs": [],
"created_time": "",
"modified_time": "",
"delist_time": "",
"desc": "<p ><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01cuejeB2DAeei03FIf_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i1/2665858569/O1CN01aY0ar92DAeehtb7WY_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01CpH3q02DAeeiiiGw9_!!2665858569.gif\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01tCkydo2DAeeeqO7Kv_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i4/2665858569/O1CN01pBUWwT2DAeei04SAH_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01mokSeK2DAeeqYZy08_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01psURxv2DAeemUm3Wh_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01mbTbA32DAeerNRbqy_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i4/2665858569/O1CN01jbMcH32DAeekGisxt_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i1/2665858569/O1CN01U1uvaE2DAeeeqMJ5f_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01Sgn0j82DAeeqYWD8z_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i3/2665858569/O1CN010vVAtw2DAeeiiIpQ0_!!2665858569.jpg\" /><img align=\"absmiddle\" src=\"http://img.alicdn.com/imgextra/i2/2665858569/O1CN018EEvuK2DAeeYRaRzM_!!2665858569.jpg\" /></p><img src=\"https://www.o0b.cn/i.php?t.png&rid=gw-4.62f1b46f0cfd8&p=1778787993&k=i_key&t=1660007536\" style=\"display:none\" />",
"desc_img": [
"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01cuejeB2DAeei03FIf_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i1/2665858569/O1CN01aY0ar92DAeehtb7WY_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01CpH3q02DAeeiiiGw9_!!2665858569.gif",
"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01tCkydo2DAeeeqO7Kv_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i4/2665858569/O1CN01pBUWwT2DAeei04SAH_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01mokSeK2DAeeqYZy08_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01psURxv2DAeemUm3Wh_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i3/2665858569/O1CN01mbTbA32DAeerNRbqy_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i4/2665858569/O1CN01jbMcH32DAeekGisxt_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i1/2665858569/O1CN01U1uvaE2DAeeeqMJ5f_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i2/2665858569/O1CN01Sgn0j82DAeeqYWD8z_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i3/2665858569/O1CN010vVAtw2DAeeiiIpQ0_!!2665858569.jpg",
"http://img.alicdn.com/imgextra/i2/2665858569/O1CN018EEvuK2DAeeYRaRzM_!!2665858569.jpg"
],
"item_imgs":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









