







要通过Python采集1688app商品详情数据,你可以使用以下步骤:
- 安装必要的 Python 模块:requests, BeautifulSoup4 和 lxml。
- 使用 requests 模块发送 HTTP 请求获取网站 HTML 内容。
- 使用 BeautifulSoup4 模块解析 HTML 页面并提取所需的数据。
- 编写一个爬虫程序,从网站下载商品详情页,并使用 BeautifulSoup4 解析 HTML 代码,提取商品信息。
以下是具体实现步骤:
- 安装必要的 Python 模块:requests, BeautifulSoup4 和 lxml。
pip install requests BeautifulSoup4 lxml
- 使用 requests 模块发送 HTTP 请求获取网站 HTML 内容。
import requests
url = 'https://m.1688.com/offer/xx.html'
response = requests.get(url)
if response.status_code == 200:
html = response.text
# 处理 HTML 页面
else:
print('请求失败:', response.status_code)
- 使用 BeautifulSoup4 模块解析 HTML 页面并提取所需的数据。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# 提取商品标题(title)
title = soup.find('h1').text
# 提取商品价格(price)
price = soup.find('div', class_='price').find('em').text
# 提取商品描述(description)
description = soup.find('div', class_='desc').text
# 提取商品图片(images)
images = []
for img in soup.find_all('img', class_='swiper-slide'):
images.append(img['data-src'])
- 编写一个爬虫程序,从网站下载商品详情页,并使用 BeautifulSoup4 解析 HTML 代码,提取商品信息。
import os
import requests
from bs4 import BeautifulSoup
def get_html(url):
"""
获取网页 HTML 内容
"""
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def parse_html(html):
"""
解析 HTML 内容,提取商品信息
"""
soup = BeautifulSoup(html, 'lxml')
title = soup.find('h1').text
price = soup.find('div', class_='price').find('em').text
description = soup.find('div', class_='desc').text
images = []
for img in soup.find_all('img', class_='swiper-slide'):
images.append(img['data-src'])
return {
'title': title,
'price': price,
'description': description,
'images': images
}
def save_images(url, images):
"""
下载并保存图片
"""
dir_name = url.split('/')[-1].split('.')[0] # 获取商品 ID
if not os.path.exists(dir_name):
os.makedirs(dir_name)
for i, img_url in enumerate(images):
response = requests.get(img_url)
if response.status_code == 200:
with open(dir_name + '/' + str(i) + '.jpg', 'wb') as f:
f.write(response.content)
def main():
"""
主程序
"""
url = 'https://m.1688.com/offer/xx.html'
html = get_html(url)
if html:
data = parse_html(html)
print(data)
save_images(url, data['images'])
else:
print('获取网页失败')
if __name__ == '__main__':
main()
运行程序,即可下载并保存商品图片,同时输出商品信息。
1688.item_get_app-获得1688商品详情数据接口
1.请求方式:HTTPS POST GET 请求URL地址
2.公共参数:
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中,复制Taobaoapi2014) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
3.请求参数:
请求参数:num_iid=商品ID
参数说明:num_iid:1688商品ID
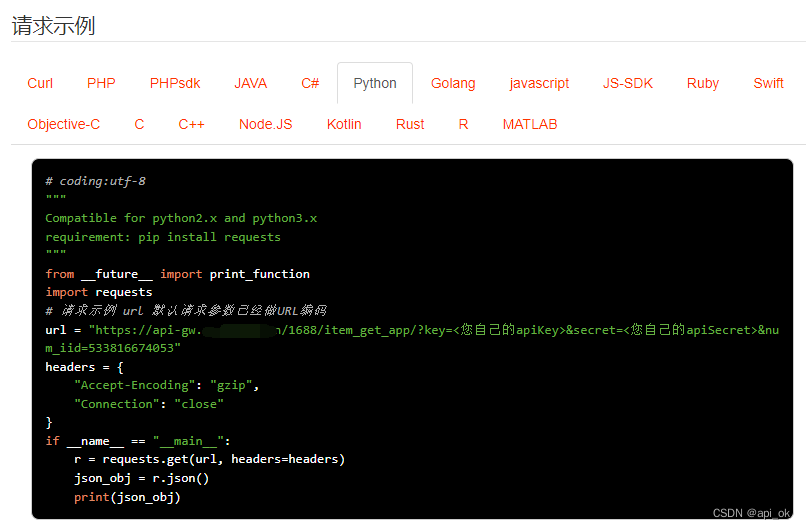
4. 请求示例,支持高并发(CURL、PHP 、PHPsdk 、Java 、C# 、Python...)
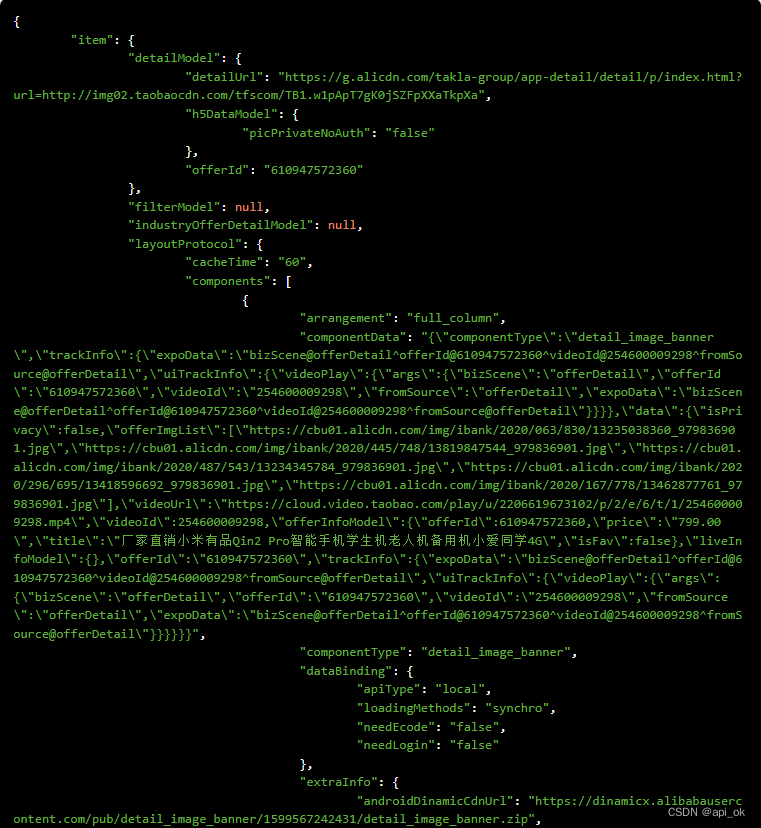
5.响应示例(展示部分)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









