






基于微信小程序云开发,我搭建了两款百科类的小程序
我会从云开发基本能力与场景实战两个方面来总结一篇我的实战过程中的心得
希望这篇文章可以对刚接触云开发的朋友有所帮助。
准备
在开发之前我们需要做一些准备
- 使用一个未注册微信公众平台的邮箱
- 使用该邮箱申请一个小程序账号
- 拿下AppID(这里需要注意的是,如果没有appid是无法使用云开发服务)
- 在开发者工具中使用AppID创建一个项目
如果你从0开始
可以使用开发者工具的云开发模板,快速创建一个云开发项目
如果你已经拥有项目
可以在项目基础上使用云开发
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-stBPwJJz-1656811456323)(https://raw.githubusercontent.com/hogB/Img/main/202207030916894.png)]
- 最后在云开发控制台开通云开发,并拿到环境ID。
基本能力
云开发主要包含云函数,云存储,数据库等基本能力,云开发官方文档介绍:微信开放文档 (qq.com),这里不再赘述
云函数
云函数,词如其名,即运行在云端环境的函数,其运行环境为node,可以简单地概括一下他的作用
只需要一行代码就可以完成数据操作
基本使用
构建我们的第一个云函数(这里为在原来的基础上使用云开发的步骤)
-
在项目根目录创建一个
cloud文件夹,用来存放我们的云函数 -
在
project.config.json配置文件中配置云函数存储路径"cloudfunctionRoot": "cloud/" -
查看开发者工具中该文件是否出现云端logo,若出现则说明配置完成
-
新建一个云函数,右键我们的云函数目录文件,如下,开发者工具会自动生成一个云函数模板供我们使用,具体的云函数配置介绍可以直接参考官方文档:我的第一个云函数 | 微信开放文档 (qq.com)
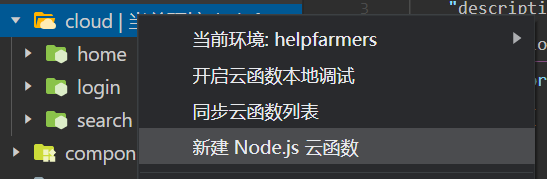
-
编写好我们的云函数后,将我们的云函数上传到云端
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9FJypI4T-1656811456324)(https://raw.githubusercontent.com/hogB/Img/main/202207030916383.png)]
-
上传后我们就可以调用我们的云函数
wx.cloud.callFunction({ name: 'login', }).then(res => {})
数据库
云开发数据库为JSON 数据库,所以没接触过的小伙伴上手起来是非常快的
创建
我们可以在云开发控制台中创建我们的数据集合,导入数据记录
- 创建并命名一个集合
- 在集合中添加数据记录,可以使用手动或者json格式
- 每个数据记录都会生成唯一标识符即**_id**
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NJ71YcUI-1656811456324)(https://raw.githubusercontent.com/hogB/Img/main/202207030916856.png)]
增删改查
官方增删改查文档增删改查,提供了增加add(),查询where(),唯一查询doc,删除remove()等数据库操作api,当然我们可以联合使用这些api来达到我们的目的,因为官方给出的非常详细,在这里也不再赘述,下面举一个简单的例子来让大家快速入门使用,比如我想要删除collects集合中一个作者为"猪痞恶霸",标题为"微信小程序万字总结"的数据记录,那么我们可以这么做。
let db = wx.cloud.database()
db.collection('collects').
where({
name : "猪痞恶霸",
title: "微信小程序万字总结"
}).remove({
success: res => {}
})
权限管理
数据库的权限管理是一个奇怪的踩坑点
在刚刚入门使用的时候就遇到这么一个坑,调用查询函数,拿不到数据,奇了个怪,这就是因为没有打开数据权限导致的问题
在每个集合中都会有一个权限管理,支持如下四个数据权限,除此之外还可以自定义数据权限。
- 所有用户可读,仅创建者可读写
- 仅创建者可读写
- 所有用户可读
- 所有用户不可读写
如果我们想要对用户展现某些数据,比如商品信息,那么我们就可以将权限更改为所有用户可读,如果我们想为用户展示他的todo待办项,那么我们就可以将权限更改为仅创建者可读写
批量导入
一个项目中如果需要存储大量的数据,一条一条手动导入json也是非常耗费时间的,而云开发数据库控制台支持我们直接导入json文件,orz,太爽了。
- 可以先创建一个集合模板,通过数据库导出为json文件
- 导入我们的数据到json中
- 导入,自动生成**_id**
注意:由于**_id为自动生成的,所以我们的json文件每个数据记录中无需_id**,如果存在导入就会导致报错,导入失败。

云存储
很多功能都需要存储一些图片文件资源,如用户上传的图片,使用云存储来存储这些资源。
存储控制台
在云开发存储控制台台中我们可以创建或者上传文件夹or文件,同一目录下会生成相同的序列+文件名
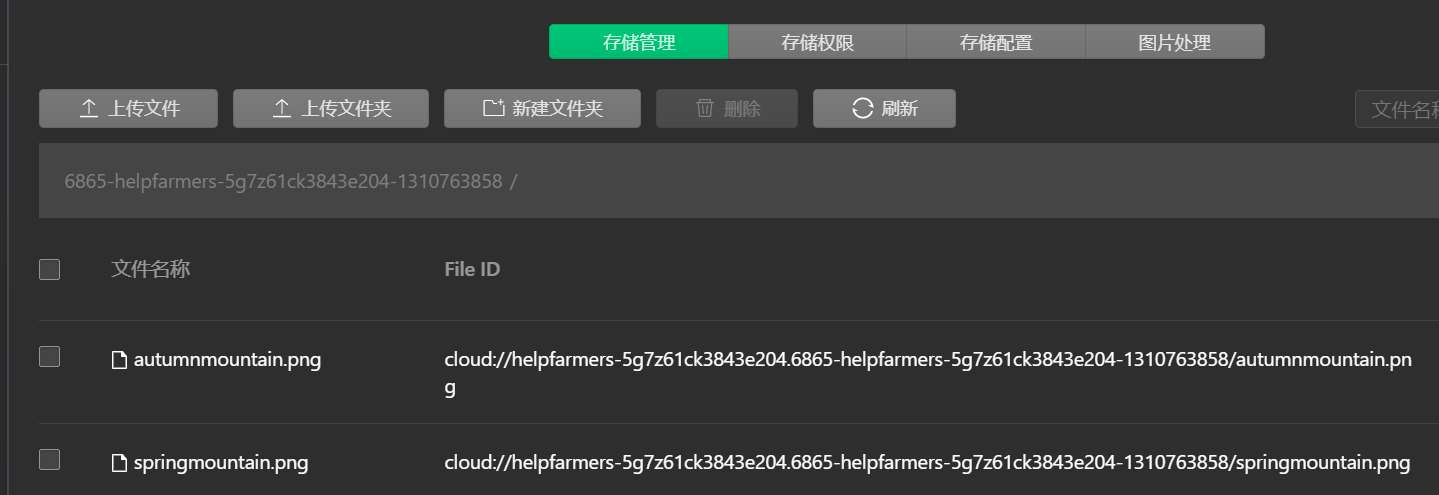
当然存储也有权限管理其和数据库权限相同,根据不同的场景制定不同的权限规则,并且小程序的相关组件如image,video可以直接通过FileID来对资源进行加载。
<image src="cloud://cloud1-0gekdmc8c1d576f8.636c-cloud1-0gekdmc8c1d576f8-1311277417/mingjia/linliankun.png"></image>
基本使用
如果我们想操作文件,那么我们可以调用api,官方api文档:API 指引
上传文件wx.cloud.uploadFile,删除文件wx.cloud.deleteFile,下载文件wx.cloud.downloadFile等
场景实战
第一部分的基础能力了解完之后,你肯定对于云开发有了基本的能力
第二部分为场景实战,我将自己的实战经历整理了出来,满满的干货
登录
进行云开发让我感触最深的就是登录模块了,我们来对比一下云开发和非云开发登录的流程
非云开发登录
- 调用
wx.login()获取code - 调用
wx.request()将code发送到我们自己的服务器 - 服务端需要凭借
appID,appsecret,code通过微信接口服务拿到session_key与openid - 将登录状态返回给小程序,小程序再其存储到
storage中
云开发登录
- 调用login云函数,即可拿到
openid
这仅仅只是登录步骤的区别,其实就是少了中间商赚差价,云开发没有了中介,所以就少了繁琐的步骤,我们来实际看一下云开发登录的实现
- 在云函数目录下创建一个login的云函数并部署到云端
- 调用
wx.getUserProfile获取用户的头像与昵称信息(自2021年4月13日起,getUserInfo将不再弹出弹窗,并直接返回匿名的用户个人信息) - 存储用户基本信息在
storage中 - 调用云函数
login - 存储调用登录云函数拿到的
openid到storage
wx.getUserProfile({desc: '用户完善会员资料'})
.then(res => {
wx.setStorageSync('userInfo', res.userInfo)
wx.cloud.callFunction({name: 'login',})
.then(res => {
this.setData({
openid: res.result.openid
})
wx.setStorageSync('openid', res.result.openid)
})
})
收藏
收藏功能在很多应用中都很常见,商品收藏,小说收藏,文章收藏,等等
大致分为三个模块,分别为:加入收藏,收藏列表,取消收藏
首先需要先建立一个collect收藏集合,并将这个集合的数据权限设置为仅创建者可读写。
加入收藏
将一本书加入用户收藏,那么则需要我们将书的信息,与用户openid作为一个数据记录加入我们的collect集合中
wx.cloud.database().collection('collects').add({
data: {
title: this.data.title,
intro: this.data.intro,
img: this.data.img,
isCollect: true,
},
success: res => {
}
})
需要注意的是,我们无需手动地去添加openid这个字段,因为在用户添加地过程中会自动附加上用户的openid,非常好用,在加入收藏后,我们就可以在我们的数据集合中看到我们加入的书本,其额外多的是唯一标识_id与用户**_openid**。
收藏列表
获取用户的收藏列表,只需要我们通过**_openid**这个数据条件获取用户的收藏书本信息
- 锁定集合
collection('collects') - 筛选数据
where()
wx.cloud.database().collection('collects').where({
_openid: openid
}).get().then(res => {})
取消收藏
取消用户收藏,与加入收藏异曲同工,只要将add操作替换为remove操作,将查询信息更改为opneid与书本名
wx.cloud.database().collection('collects').where({
_openid: openid,
title: this.data.title
}).remove({
success: res => {}
})
内容详情
商品详情信息,书本内容,等等场景都需要内容的加载渲染
我在我的项目中将wxparse进行了二次组件封装,简单的使用可能太过臃肿,下面我概述了封装的步骤
项目中组件目录下的prebuild为封装的组件,大家可以参考使用
解析器组件封装
解析器为开源wxparse,原作者已经不再维护,github地址:wxParse-微信小程序富文本解析自定义组件,支持HTML及markdown解析
-
将项目中的wxParse文件引入到项目根目录中
-
封装一个文本解析组件
-
在组件的wxml文件中引入
<import src="/wxParse/wxParse.wxml" /> -
在组件的wxss文件中引入
@import "/wxParse/wxParse.wxss"; -
在组件的js文件中引入
import wxParse from "../../wxParse/wxParse.js"; -
定义组件属性,根据wxparse提供的参数项,定义我们解析器组件所需要的属性
properties: { bindName: { type: String }, type: { type: String, value: "html" }, data: { type: String }, imagePadding: { type: Number, value: 0 } },- bindName绑定的数据名(必填)
- type可以为html或者md(必填)
- data为传入的具体数据(必填)
- target为Page对象,一般为this(必填)
- magePadding为当图片自适应是左右的单一padding(默认为0,可选)
-
封装一个解析方法,根据我们设定的组件属性进行解析,并在其中将解析好的内容即
nodes响应式设置为数据valuebuild() { let { bindName, type, data, imagePadding } = this.properties; wxParse.wxParse(bindName, type, data, this, imagePadding) this.setData({ value: this.data[bindName].nodes }) }, -
在组件的wxml中使用数据渲染组件
template<template is="wxParse" data="{{wxParseData:value}}" />
解析器组件使用
封装好解析器组件后,其与正常组件的引入使用方式相同
正如下面,我们只需要在拿到我们的html或者md字符串后调用this.selectComponent('#preContent').build(),这种无脑传入我们的插值数据即可完成渲染,非常好用。
<pre-build id="preContent" bindName="{{title}}" data="{{content}}"/>
多种数据解析问题
如果你的应用需要出现不同种类的文本解析情况,那么就需要考虑这个问题,比如我需要解析出:资讯详情,新闻详情,百科详情,三种详情,那么会不会就有人去app.json初始化三个详情页,我猜肯定会有人这么干,下面我来提供我的思路
页面传参进行工厂化处理
下面是我们的路由跳转传参函数,将数据获取的id作为一个参数,将要获取数据的数据集合作为一个参数即cont
goCont:function(e) {
let data = e.currentTarget.dataset
wx.navigateTo({
url: '../cont/cont?id=' + data.id+'&port='+data.cont
})
},
在onload生命周期中获取到路由参数进行调用即可自由得获取任何数据集合中得内容
let { id, port } = options
wx.cloud.database().collection(port).where({_id:id})
自定义tabbar与headbar
不同的场景有不同的需求,我们需要自己封装tabbar或headbar来达到我们的效果
tabbar封装与使用
官方文档给出了tabbar封装说明:自定义 tabBar | 微信开放文档 (qq.com),下面我具体说一下我的封装和使用步骤
-
在官方文档中下载封装的tab项目示例,得到
custom-tab-bar文件 -
将文件存放在自己项目的根目录中
-
在
app.json更改tab配置"custom": true, -
在app.json中配置全局组件
"usingComponents": { "x-tabbar": "./custom-tab-bar/index" },
headbar的封装与使用
head组件的封装和普通组件的封装方法相同,只不过因为有右上角胶囊的存在,所以是要计算不同机型的高度来进行适配
大概的步骤就是:
-
在需要使用headbar的页面组件进行
json配置"navigationStyle": "custom" -
引入head组件
"usingComponents": { "Header": "/components/headBar/headBar" }, -
应用
<Header backHomeFlag customTitle="详情"></Header>
具体demo大家可以参考项目组件目录中的headBar组件文件与我之前总结的headbar封装和使用方法:微信小程序head组件的封装与使用 - 掘金 (juejin.cn)
换肤
项目有跟随季节换肤的功能,跟随季节的改变更换主题颜色与资源,当然这里我是手动更改了月份。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkHbD0Z7-1656811456325)(https://raw.githubusercontent.com/hogB/Img/main/202207030917155.png)]
全局变量的使用
这个需求肯定是需要存储season作为全局变量,在每个组件内进行使用
-
在
app.js中预设全局变量globalData: { season: 'spring' }, -
在初始化的生命周期中进行季节判断与赋值
const app = getApp() app.globalData.season = 'spring'
具体实现步骤
-
在onload生命周期中获取全局变量并设置季节值
const app = getApp(); this.setData({ season: app.globalData.season }) -
预设好
class,比如spring-text,autumn-text -
插值进行类的变换实现换肤效果
<text bindtap="read" class="{{season}}-text">点击阅读</text>
封装一个获取季节的全局方法
每个页面都需要进行季节值的获取与设置,那我们不如使用util来封装一个工具函数
-
在utils文件目录下的util文件,声明一个获取季节的方法
const setSeason = (that) => { const app = getApp(); that.setData({ season: app.globalData.season }) } -
将这个方法暴露出去
module.exports = { setSeason } -
在我们所需要的页面进行调用
let util = require('../../utils/util.js') let that = this util.setSeason(that)
非常好用!!!
icon的更换
由于tab组件的特殊性,其icon需要在data里进行配置,而如果我们通过if else判断季节,再使用setData做出改变的话很不优雅,所以我们可以采用模板字符串的形式,即可完成tabbar的icon更迭。
list: [{
selectedIconPath: `../images/tabicon/${season}-home-active.png`,
iconPath: `../images/tabicon/spring-home.png`,
pagePath: "../home/home",
text: "首页"
}]
如果我们使用if和响应式替换的话,看起来就很冗余
if(season === "spring") {
this.setData({
list:[{
selectedIconPath: "../images/tabicon/spring-home-active.png",
iconPath: "../images/tabicon/spring-home.png",
pagePath: "../home/home",
text: "首页"
}]
})
}else {
// ...........
}
首屏渲染
谈起首屏渲染肯定是应用优化中重要的部分,而小程序开发者工具中自动生成骨架屏的工具大大地减少了开发者的工作,只需要几步就可以生成对应页面的骨架屏文件,具体实战步骤可以参考我的这篇文章微信小程序实战之骨架屏的应用与实现 - 掘金 (juejin.cn)里面详细概述了微信小程序骨架屏的使用方法和使用注意事项
触底加载与下拉刷新
因为涉及到卡片列表所以触底加载和下拉刷新的实现是必要的,通过灵活使用limit()和skip()来进行集合特定区间内数据记录的获取,来达到我们的目的,具体实战步骤可以参考我的这篇文章小程序触底加载与下拉刷新功能的设计与实现 - 掘金 (juejin.cn)里面详细讲解了我在这个项目中实现触底加载和下拉刷新的过程。
部署上线
大概的上线流程如下
- 在开发者工具中上传我们的代码
- 检查我们调用的api,比如我用到了位置信息,那么我们就需要去公众平台的开发部分的接口管理部分进行一个接口申请
- 申请用户协议
- 提交审核(不进行上面的步骤就会被驳回,我当时被驳回了好几次)
- 通过后即可部署上线使用















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









