







一.视图:
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询。我们要知道视图仅仅是用来查看别处的数据的一种设施。视图本身不包含任何数据,因此视图返回的数据都是从其他表中检索出来的。
创建出来的视图用法其实和基本表一样,可以对其进行各种查询和过滤操作。
下面看一个例子:创建了一个学生和课程的表的联结的视图,名为smy_view;
CREATE VIEW smy_view AS SELECT student.*,sc.`C`,sc.`score` FROM student INNER JOIN sc ON sc.`S`=student.`S`;
然后我们就会发现对应的视图索引下就有我们创建的视图

然后我们可以直接对这个视图进行各种查询和过滤。如我们查询课程号为01的学生信息:
SELECT * FROM smy_view WHERE C='01';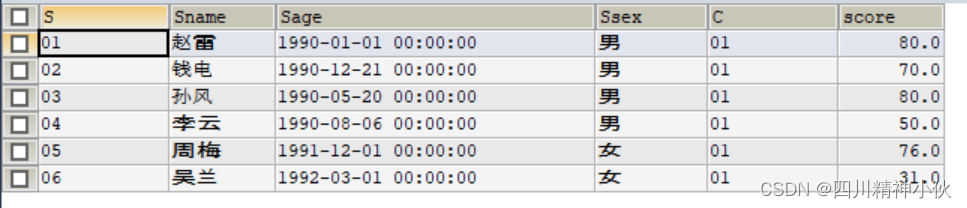
视图的作用:
1.视图最常见的应用是可以简化复杂的SQL语句,尤其是联结语句。
2.视图还可以保护数据,可以给用户授予表的部分访问权限而不是全部访问权限
性能问题:
因为视图不包含数据,所以每次执行视图的时候都要进行一次查询。如果在视图中使用了大量的联结则性能会大幅度下降,所以在部署大规模的视图的时候要先对其性能进行测试。
二.存储过程:
1什么要用存储过程?
MySQL5.0 版本开始支持存储过程。
大多数 SQL 语句都是针对一个或多个表的单条语句。并非所有的操作都那么简单。经常会有一个完整的操作需要多条语句才能完成。
存储过程简单来说,就是为以后的使用而保存的一条或多条 MySQL 语句的集合。可将其视为批处理文件。虽然他们的作用不仅限于批处理。
存储过程的优点
1. 通过把处理封装在容易使用的单元中,简化复杂的操作;
2 简化对变动的管理。如果表名、列名或业务逻辑有变化。只需要更改存储过程的代码,使用它的人员不会改自己的代码;
3.通常存储过程有助于提高应用程序的性能。当创建的存储过程被编译之后,就存储在数据库中。 但是,MySQL 实现的存储过程略有不同。MySQL 存储过程按需编译。在编译存储过程之后,MySQL 将其放入缓存中。MySQL 为每个连接维护自己的存储过程高速缓存。如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询;
4.存储过程有助于减少应用程序和数据库服务器之间的流量,因为应用程序不必发送多个冗长的 SQL 语句,而只用发送存储过程的名称和参数;
5.存储的程序对任何应用程序都是可重用的和透明的。存储过程将数据库接口暴露给所有应用程序,以便开发人员不必开发存储过程中已支持的功能;
6.存储的程序是安全的。数据库管理员可以向访问数据库中存储过程的应用程序授予适当的权限,而不向基础数据库表提供任何权限。
存储过程的缺点:
1.如果使用大量存储过程,那么使用这些存储过程的每个连接的内存使用量将会大大增加。 此外,如果您在存储过程中过度使用大量逻辑操作,则 CPU 使用率也会增加,因为 MySQL 数据库最初的设计侧重于高效的查询,不利于逻辑运算;
2.存储过程的构造使得开发具有复杂业务逻辑的存储过程变得更加困难;
3.很难调试存储过程。只有少数数据库管理系统允许您调试存储过程。不幸的是,MySQL 不提供调试存储过程的功能;
4.开发和维护存储过程并不容易。开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能会导致应用程序开发和维护阶段的问题。
存储过程的创建(和函数类似):
CREATE PROCEDURE 过程名字(参数1,参数2)
BEGIN
END
存储过程的调用:
CALL 过程名字(参数)
DELIMITER //
CREATE PROCEDURE pro_can(IN a INT,IN b INT)
BEGIN
SELECT * FROM student LIMIT a,b;
END //
DELIMITER
CALL pro_can(2,3);#调用存储过程
注意:有三种类型的参数 in(输入参数) out(输出参数) inout(输入输出参数)。对于out参数我们可以用into关键字来对其赋值操作。
DELIMITER //
CREATE PROCEDURE pro_cann(OUT a INT)
BEGIN
SELECT AVG(score) FROM smy_view INTO a;
END //
DELIMITER
CALL pro_cann(@a);
SELECT @a;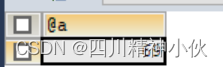















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









