







高性能,高可靠,高可扩展NoSQL数据库
前记
1、NoSQL数据库
1、概述
NoSQL = Not Only SQL 泛指非关系型数据库,不依赖业务逻辑存储,而以简单的key-value模式存储,因此大大增加了数据库的扩展能力
- 不遵循SQL标准
- 不支持ACID
- 远超于SQL的性能
2、NoSQL适用场景
- 对数据高并发的读写
- 海量数据的读写
- 对数据高可扩展性的
3、NoSQL不适用场景
- 需要事务支持
- 基于sql的结构化存储,处理复制的关系,需要即席查询
- 用不着sql和用了sql也不行的情况,考虑用Nosql
2、Redis采用单线程+多路IO复用技术
1、与Memcache的三点不同:支持多数据类型,支持持久化,单线程+多路IO复用
2、多路复用指使用一个线程来检查多个文件描述符(Socket)的就绪状态,
比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就位,则返回,否则阻塞直到超时。
得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启用线程执行(比如使用线程池)、
就是说多路IO复用起到一个监视的效果,就绪后,Redis直接执行,不需要等待
3、串行 vs 采用多线程+锁(Memcached)vs 单线程+多路IO复用的比较
- 1、串行:阻塞IO,一件事一件事的做,在做当前事时,不能做其他事,有等待
- 2、采用多线程+锁:非阻塞IO,一直重复做当前的事,没有等待
- 3、单线程+多路IO复用:做某件事情需要一定的时间,可以监视这件事,我们可以做其他的事。
多路IO复用有select,poll,epoll这些模式。
select监测数量能力有限。poll监测数量没有限制,但是需要一个一个核查。
配epoll监测数量没有限制,也不需要一个一个核查,直接看是否有一个正确的标识。

3、Redis的"两大维度,三大主线"

一、安装配置Redis
redis官网
1、下载最新版本tar.gz
2、安装C语言编译器gcc
yum install gcc
查看gcc版本
gcc --version
3、解压redis-tar.gz(解压到当前目录,本文的目录为/study,解压后为/study/redis-6.2.6)
tar -zxvf redis-6.2.6.tar.gz
4、编译为C文件(进入解压好的redis-6.2.6目录)
1、make
安装bin启动器到/study/redis-6.2.6目录下
2、make PREFIX=/study/redis-6.2.6 install
5、拷贝一份redis.conf到conf目录
cp /study/redis.6.2.6/redis.conf /study/redis.6.2.6/conf/redis.conf
vim /study/redis.6.2.6/conf/redis.conf
开启后台运行
daemonize no 改为 yes
6、以配置文件后台启动(进入/study/redis-6.2.6/bin目录),连接客户端
./redis-server ../conf/redis.conf
./redis-cli
7、关闭服务进程
客户端输入 showdown
ps -ef|grep redis
kill -9 pid
二、常用五大数据类型
Key
keys * 查看所有key
exists <key> 判断key是否存在
type <key> 查看key是什么类型
del <key> 删除指定key数据
unlink <key> 根据value选择非阻塞删除,仅将key从keyspace元数据删除,真正的删除会在后续异步操作
expire <key> 10 设置10秒过期时间
ttl <key> 查看存活时间 -1永不过期 -2已过期
select ? 切换数据库 默认0-15
dbsize 查看当前数据库key数量
flushdb 清空当前库
flushall 清空所有库
1、字符串(String)-- ArrayList
1、简介
简单动态字符串(Simple Dynamic String SDS)
类似ArrayList,采用预分配冗余空间的方式减少内存的频繁分配
二进制安全,最大存储512M
2、数据结构

3、命令
1、设值
set <key> v 设置单个键值
mset <key> v <key> v 设置多个键值
setex <key> <time> v 设置单个键值并设置过期时间 t 秒
setnx <key> v 当key不存在时设置
msetnx <key> v <key> v 当每个key不存在时设置
getset <key> v 设置新值同时获取旧值
setrange <key> <index> v 覆写k所存储的v,从i下标开始追加
append <key> v 将给定的v追加到原值末尾
2、查询
get <key> 查询单个键值
mget <key> <key> 查询多个键值
getrange <key> <s> <e> 按下标查询键值
strlen <key> 获取值的长度
3、数字值操作(原子操作:得益于redis单线程,不会被其他线程打断的)
incr k 储存的数字值增 1
incrby k ? 储存的数字值增 ?
decr k 储存的数字值减 1
decrby k ? 储存的数字值减 ?
2、列表(List)-- quickList
1、简介
单键多值

2、数据结构:

3、命令
例:从左插入v1 v2 v3,实际从左到右为v3 v2 v1
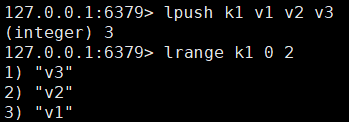
1、插吐值
lpush/rpush k v1 v2 v3 从左/右插入v1,v2,v3
lpop/rpop k 从左/右吐出一个值,吐完值键消失
rpoplpush k1 k2 从k1右边吐一个值插到k2左边
2、查询(并非吐值)
lrange k s e 按照索引下标范围获得元素s start, e end
lindex k i 按照索引下标获得元素
llen l 获取列表长度
3、插值
linsert k before "v1" "new v1" 在v1后面插入newv1
演示

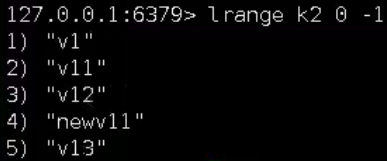
4、特殊删除
lrem k 2 "v" 删除k左边的两个"v"
演示

5、替换
lset k i v 将k下标为i的值换为v
演示

3、集合(Set)-- Hash
1、简介
自动排重
String类型的无序集合
底层是一个value为null的hash表,增删查复杂度都为O(1)
一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变
2、数据结构
是dict字典,字典使用哈希表实现的
Java中的HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也一样,内部也使用Hash结构,所有的value指向同一个对象
3、命令
sadd k v1 v2 v3 添加
smembers k 返回集合中所有元素
srandmember k n 随机从集合查询n个值
sismember k v 判断集合中是否有v
scard k 查询集合中元素个数
srem k v1 v2 删除集合中的某个元素
spop k 随机从集合k吐出某个值(吐出的值消失)
smover k1 k2 v1 把集合k1中的值v1移到k2
sinter k1 k2 返回两个集合的交集元素
sunion k1 k2 返回两个集合的并集元素
sdiff k1 k2 返回两个集合的差集元素(k1中的存在的,k2中不存在的)
4、哈希(Hash)
1、简介
Hash是一个String类型的field和value的映射表,类似于Map<String,Object>
2、数据结构
Hash类型对应数据结构为:ziplist(压缩列表),hashtable(哈希表),
当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable
3、命令
hset k f v 给k中的f赋值v
hsetnx k f v 给k中的f赋值v,仅当f不存在时
例 hset user:1001 id 1 设置user1001的id为1
hmest k f1 v1 f2 v2 给k中的多个f赋值v
hexist k f 查看k中是否存在f
hkeys k 查看k中的所有field
hvals k 查看k中的所有value
hget k f 从k集合f查询v
hincrby k f n 为k中的f的v加上增量n
5、有序集合(Zset)
1、简介

2、数据结构

跳跃表实现过程


3、命令
zadd k s v s v 将一个或多个member元素及其score值加入有序集k中
zrange k s e 返回k中下标在s-e中的元素
zrange k s e withscores 返回k中下标在s-e中的元素并带score(按评分从小到大)
zrevrange k s e withscores 返回k中下标在s-e中的元素并带score(按评分从大到小)
zrangebyscore k min max 返回评分在min max的元素(包含min,max)从小到大
zrevrangebyscore k max min 返回评分在max min的元素(包含min,max)从大到小
zincrby k <increment> v 为元素的scrore加上增量
zrem k v 删除k中指定元素
zcount k min max 统计个数,返回个数
zrank k v 返回v的排名,小的是第一名,排名从0开始
三、Redis配置文件详解
1、### NETWORK 网络相关配置###
1、bind

2、protected-mode
默认为yes,远程无法访问
修改为no,远程可以访问
3、Port
默认6379
4、tcp-backlog

5、timeout

2、### SECURITY 安全###
1.requirepass
修改配置文件中的 requirepass 参数,
把前面 # 注释去掉,后面 foobared 改成自己想用的密码,
重启redis即可。
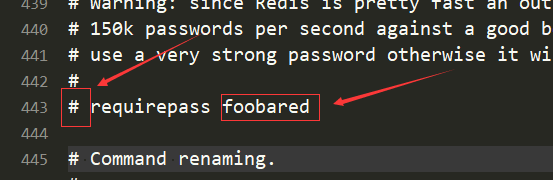
进入客户端输入
auth *** 连接
3、### GENERAL 通用###
1.daemonize

2.pidfile

3.loglevel

4.logfile

5、database 16
数据库设置默认16个 0-15
4、### LIMITS 限制###
1.maxclients

2.maxmemory

3.maxmemory-policy

4.maxmemory-samples

四、Redis的发布与订阅
1、什么是发布与订阅

2、流程

3、命令行实现
1.打开一个客户端订阅channel1
subscribe channel1
2.打开另一个客户端,给channe11发布消息hello
publish channel1 hello
3.打开第一个客户端收到hello
五、Redis新数据类型
1、Bitmaps
1.简介


2、命令
汇总
1、setbit <key> <offset> <value> 设置bitmaps中某个偏移量的值(0或1)
*offset:偏移量从0开始 设置成功返回0
2、getbit <key> <offset> 获取bitmaps中某个偏移量的值
3、bitcount <key> [start end] 统计字符串从start字节到end字节比特值为1的数量
4、bitop and(or/not/xor) <destkey> [k1 k2...] 获取多个k中的and(交集),or(并集),not(非),xor(异或)
的操作结果并将结果保存在destkey中 返回值为and(or/not/xor)后的数量
1、设置bitmaps中某个偏移量的值
setbit <key> <offset> <value> 设置bitmaps中某个偏移量的值(0或1)
*offset:偏移量从0开始 设置成功返回0
实例



2、getbit
getbit <key> <offset> 获取bitmaps中某个偏移量的值
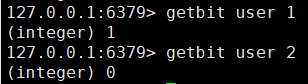
3、bitcount(获取的数量是byte并非bit)

bitcount <key> [start end] 统计字符串从start字节到end字节比特值为1的数量

4、bitop
bitop and(or/not/xor) <destkey> [k1 k2...] 获取多个k中的and(交集),or(并集),not(非),xor(异或)
的操作结果并将结果保存在destkey中 返回值为and(or/not/xor)后的数量
演示

Bitmaps与set的对比


2、HypeLogLog
1、简介

2、命令
1、pfadd
如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0
pfadd <key> <element> 添加指定元素
2、pfcount
pfcount <key> 计算HLL的近似基数,返回数量
3、pfmerge
pfmerge <destkey> <sourcekey> 将一个或多个HLL合并后的结果存在<destkey>
3、Geospatial
1、简介

2、命令
1、geoadd
geoadd <key> <longityde> <latitude> <member> 添加地理位置(经度,纬度,名称)
geoadd city 19.21 32.23 guangzhou
2、geopos
geopos <key> <member> 获取指定地区坐标值
geopos city guangzhou
3、geodist
geodist <key> <member1> <member2> [m|km|ft|mi] 获取两个位置的直线距离 单位m默认值
4、georadius
georadius <key> <longitude> <latitude> radius [m|km|ft|mi] 以给定的经纬度为中心,找出某一半径radius内的元素
六、Jedis操作
1、测试连接及jedis方法调用
1、pom文件
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
2、开放防火墙
systemctl status firewalld 查看防火墙状态
systemctl stop firewalld 关闭防火墙
3、配置文件
1、bind127.0.0.1 -》 #bind127.0.0.1 注释掉61行
2、protected-mode yes -》 protected-mode no 关闭保护模式
4、重启redis
1、ps -ef|grep redis 查看进程
2、kill -9 pid 杀掉进程
5、测试连接
public class JedisDemo01 {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.88.129", 6379);
String value = jedis.ping();
System.out.println(value);
//输出PONG
}
}
6、测试String
public void demo1() {
Jedis jedis = new Jedis("192.168.88.129", 6379);
jedis.set("name", "jiali");
String name = jedis.get("name");
System.out.println(name);
Set<String> keys = jedis.keys("*");
for (String key : keys) {
System.out.println("key:" + key);
}
}
2、模拟验证码发送

1、生成6位随机数
public static String getCode() {
Random random = new Random();
String code = "";
for (int i = 0; i < 6; i++) {
//取10之间的数字
int rand = random.nextInt(10);
code += rand;
}
return code;
}
2、每个手机每天只能发送三次,验证码放到redis中,设置过期时间
public static void sendCode(String phone) {
Jedis jedis = new Jedis("192.168.88.129", 6379);
jedis.auth("****");
//拼接key
//手机发送次数key
String countKey = phone + ":count";
//验证码key
String codeKey = phone + ":code";
//每个手机每天只能发送三次
String count = jedis.get(countKey);
if (count == null) {
//没有发送次数,第一次发送
//设置发送次数是1
jedis.setex(countKey, 24 * 60 * 60, "1");
} else if (Integer.parseInt(count) <= 2) {
//发送次数+1
jedis.incr(countKey);
} else if (Integer.parseInt(count) > 2) {
//发送三次,不能再发送
System.out.println("今天发送次数已经超过三次");
jedis.close();
//中断获取验证码后续操作
return;
}
//发送验证码放到redis
String code = getCode();
jedis.setex(codeKey, 120, code);
jedis.close();
}
3、验证码校验
public static void verifyCode(String phone, String inputCode) {
Jedis jedis = new Jedis("192.168.88.129", 6379);
jedis.auth("****");
String codeKey = phone + ":code";
String redisCode = jedis.get(codeKey);
if (redisCode.equals(inputCode)) {
System.out.println("成功");
} else {
System.out.println("失败");
}
}
4、验证
1、sendCode("10086");
2、进入redis-cli,查看keys *,查看验证码填入下面?
3、verifyCode("10086","?");
4、成功
七、Redis6与SpringBoot整合
1、pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
2、配置文件
spring:
redis:
host: 192.168.88.129
port: 6379
password: ****
database: 0
#连接超时时间
timeout: 1800000
lettuce:
pool:
#最大连接数
max-active: 20
#最大阻塞等待时间(负数表示没限制)
max-wait: -1
#最大最小空间连接
max-idle: 5
min-idle: 0
3、RedisConfig
package com.laptoy.redis.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashKeySerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//配置序列化(解决乱码问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
4、测试Controller
@RestController
public class RedisTestController {
@Autowired
RedisTemplate redisTemplate;
@GetMapping("/test")
public String redisTest() {
redisTemplate.opsForValue().set("name", "jiali");
String name = (String) redisTemplate.opsForValue().get("name");
return name;
}
}
八、事务_锁机制_秒杀
1、Redis事务定义

2、Muti,Exec,discard


3、事务的错误处理
1、组队中某个命令出现报告错误,执行时整个的所有队列都会被回滚

2、执行阶段某个命令报错,则只有报错的不会执行,其他正常执行


4、事务冲突的问题
例子:同一个账户有10000块,三个人登录同一个账户同一时刻购买东西

1、悲观锁(效率低)


2、乐观锁


3、WATCH key [key]

客户端1
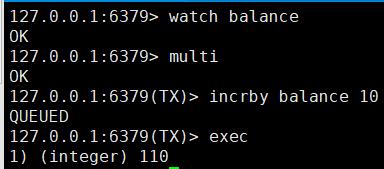
客户端2
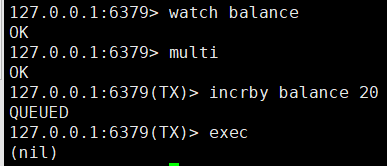
4、UNWATCH
被watch的客户端的key成功执行事务后,自动取消watch状态

5、Redis事务三大特性

5、秒杀
1、核心代码演示
1.客户端添加秒杀商品 iphone 10件
set sk:iphone:kc 10
2.获取随机用户id
public static String getUid() {
Random random = new Random();
String uid = "";
int rand = random.nextInt(20);
uid += rand;
return uid;
}
3.秒杀过程
public static void doSecKill(String uid, String pid) {
if (uid == null || pid == null) {
System.out.println("用户名或商品名不能为空");
}
Jedis jedis = new Jedis("192.168.88.129", 6379);
jedis.auth("****");
//1、库存key
String kcKey = "sk:" + pid + ":kc";
//2、用户key
String userKey = "sk:" + pid + ":user";
//3、判断秒杀是否开始
String kc = jedis.get(kcKey);
if (kc == null) {
System.out.println("秒杀未开始");
jedis.close();
//中止
return;
}
//4、判断用户是否重复秒杀
if (jedis.sismember(userKey, uid)) {
System.out.println("您已经秒杀成功,无法重复参与");
jedis.close();
//中止
return;
}
//5、判断库存数量
if (Integer.parseInt(kc) <= 0) {
System.out.println("秒杀已结束");
jedis.close();
//中止
return;
}
//6、秒杀过程
//6.1、库存-1
jedis.decr(kcKey);
//6.2、把秒杀用户添加到清单里
jedis.sadd(userKey, uid);
System.out.println("秒杀成功");
jedis.close();
}
4.测试
public static void main(String[] args) {
for (int i = 0; i <20 ; i++) {
doSecKill(getUid(), "iphone");
}
}
2、秒杀并发模拟
自行模拟tomcat测试,此处省略
1.使用工具ab模拟测试
centos6默认安装,centos7需要手动安装
2.安装ab
yum install httpd-tools
3.命令
ab --help
ab http://....
-n 请求数量
-c 请求并发量
-p post请求时提交参数
-T 指定参数类型post/put
3、连接超时问题
1.使用数据库连接池解决–单例模式懒加载,双重校验锁
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolUtil{
private static volatile JedisPool jedisPool = null;
private JedisPoolUtil() {
}
public static JedisPool getJedisPoolInstance() {
if (null == jedisPool) {
synchronized (JedisPoolUtil.class) {
if (null == jedisPool) {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(32);
poolConfig.setMaxWaitMillis(100 * 1000);
//超时是否等待
poolConfig.setBlockWhenExhausted(true);
//测试连接状态 ping pong
poolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(poolConfig, "192.168.88.129", 6379, 60000, "****");
}
}
}
return jedisPool;
}
public static void release(JedisPool jedisPool, Jedis jedis) {
if (null != jedis) {
jedisPool.returnResource(jedis);
}
}
}
2.测试连接
JedisPool jedisPoolInstance = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPoolInstance.getResource();
4、超卖问题
1.乐观锁解决

代码演示
1.注释秒杀过程
//6、秒杀过程
//6.1、库存-1
//jedis.decr(kcKey);
//6.2、把秒杀用户添加到清单里
//jedis.sadd(userKey, uid);
2.加了乐观锁
jedis.watch(kcKey);
Transaction multi = jedis.multi();
multi.decr(kcKey);
multi.sadd(userKey, uid);
List<Object> result = multi.exec();
if (result == null || result.size() == 0) {
System.out.println("秒杀失败了,请重试");
jedis.close();
return;
}
5、库存遗留问题
1.Lua脚本


测试代码
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.slf4j.LoggerFactory;
import ch.qos.logback.core.joran.conditional.ElseAction;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.ShardedJedisPool;
import redis.clients.jedis.Transaction;
public class SecKill_redisByScript {
private static final org.slf4j.Logger logger =LoggerFactory.getLogger(SecKill_redisByScript.class) ;
public static void main(String[] args) {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
System.out.println(jedis.ping());
Set<HostAndPort> set=new HashSet<HostAndPort>();
// doSecKill("201","sk:0101");
}
static String secKillScript ="local userid=KEYS[1];\r\n" +
"local prodid=KEYS[2];\r\n" +
"local qtkey='sk:'..prodid..\":qt\";\r\n" +
"local usersKey='sk:'..prodid..\":usr\";\r\n" +
"local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" +
"if tonumber(userExists)==1 then \r\n" +
" return 2;\r\n" +
"end\r\n" +
"local num= redis.call(\"get\" ,qtkey);\r\n" +
"if tonumber(num)<=0 then \r\n" +
" return 0;\r\n" +
"else \r\n" +
" redis.call(\"decr\",qtkey);\r\n" +
" redis.call(\"sadd\",usersKey,userid);\r\n" +
"end\r\n" +
"return 1" ;
static String secKillScript2 =
"local userExists=redis.call(\"sismember\",\"{sk}:0101:usr\",userid);\r\n" +
" return 1";
public static boolean doSecKill(String uid,String prodid) throws IOException {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
//String sha1= .secKillScript;
String sha1= jedis.scriptLoad(secKillScript);
Object result= jedis.evalsha(sha1, 2, uid,prodid);
String reString=String.valueOf(result);
if ("0".equals( reString ) ) {
System.err.println("已抢空!!");
}else if("1".equals( reString ) ) {
System.out.println("抢购成功!!!!");
}else if("2".equals( reString ) ) {
System.err.println("该用户已抢过!!");
}else{
System.err.println("抢购异常!!");
}
jedis.close();
return true;
}
}
九、持久化之RDB(Redis DataBase)默认开启
优点
- (1)节省磁盘空间
- (2)恢复速度快
缺点
- (1) Fork的时候,内存的数据被克隆了一份,大致2倍的膨胀率需要考虑
- (2)虽然fork时使用了写时拷贝技术,但是如果数据庞大比较消耗性能
- (3)在备份周期一定间隔时间做一次备份,但是如果Redis意外down掉的话,就会丢失最后一次修改
1、是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照
Redis将内存存储和持久化存储相结合,即可提供数据访问的高效性,又可保证数据存储的安全性。
2、备份是如何执行的
当满足条件时,redis需要执行RDB的时候服务器会执行以下操作:
- 1.redis调用系统的fork()函数创建一个子进程
- 2.子进程将数据集写入一个临时的RDB文件
- 3.当子进程完成对临时的RDB文件的写入时,redis用新的RDB文件来替换原来旧的RDB文件,并将旧的RDB文件删除
redis在进行快照的过程中不会对RDB文件进行修改,只有快照结束后才会将旧快照替换成新快照,也就是说任何时候RDB都是完整的
3、Fork

4、配置文件(### SNAPSHOT###)
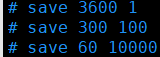
1.Save
1、默认1分钟内改了1万次,或5分钟内改了100次,或15分钟改了1次执行
2、如何禁用
不设置save指令,或者给save传入空字符串
3、动态禁止
redis-cli config set save ""
2.Save VS bgSave
1、save:只管保存,其他不管,全部阻塞。手动保存,不建议
2、bgsave:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。
可以通过lastsave命令获取最后一次成功执行快照的时间
3.stop-writes-on-bgsave-error 停止写入
当Redis无法写入磁盘的话,直接关掉Redis的写操作。推荐开启
 4.rdbcompression 压缩文件
4.rdbcompression 压缩文件
对于存储到磁盘中的快照,可以设置是否进行压缩存储,redis会采用LZF算法进行压缩。推荐开启
缺点:消耗CPU

5.rdbchecksun 检查完整性
存储快照后,redis可以使用CRC64算法进行数据校验。推荐开启
缺点:消耗CPU

5、rdb备份与恢复
查看文件目录(xxx.rdb文件放到该目录自动进行恢复)
config get dir 查看文件目录(xxx.rdb文件放到该目录自动进行恢复)
十、持久化之AOF(Append Only File) 默认不开启
优点
- 1、备份机制更稳健,丢失数据概率较低
- 2、可读的日志文件,通过操作AOF文件,可以处理误操作
- 3、AOF以appen-only(追加)的模式写入,所以没有任何磁盘寻址的开销,写入性能非常高。
缺点
- 1、比RDB占用更多磁盘空间
- 2、恢复备份速度慢,不适合做冷备
- 3、每次读写都同步,有一定的性能压力
- 4、存在个别bug,造成恢复不能
bin目录输入redis-check-aof --fix xxx.aof可以修复一些操作
1、是什么
- 1、以日志的形式来记录每个写操作
- 2、只许追加文件但不能改写文件
- 3、Redis启动之初会重新构建数据
2、AOF持久化流程
- 1、客户端的请求命令会被append追加到AOF缓存区中
- 2、AOF缓存区根据AOF持久化策略[always,everysec,no]将操作sync同步到AOF文件
- 3、AOF文件超过重写策略或手动重写时,会对AOF文件进行rewrite重写,压缩AOF文件容量
- 4、Redis服务重启时,重写load加载AOF文件的写操作达到数据恢复的目的
3、开启AOF(若RDB同时开启,Redis听AOF的)
appendonly yes 开启AOF
appendfilename "xxx.aof" 自定义文件名称
4、AOF启动/修复/恢复
1、恢复
查看文件目录(xxx.aof文件放到该目录自动进行恢复)
config get dir 查看文件目录(xxx.aof文件放到该目录自动进行恢复)
2、异常修复,修复部分语句错误(bin目录)
redis-check-aof --fix xxx.aof 继续输入y
5、AOF同步频率
appendfsync always 始终同步。性能较差但完整性好
appendfsync everysec 每秒同步。如果宕机,本秒的数据可能丢失
appendfsync no 不主动同步,把同步时机交给操作系统
6、Rewrite压缩
1、是什么
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof
2、如何实现重写
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
redis4.0版本后的重写,实质上就是把rdb的快照以二进制的形式附在新的aof头部,作为已有的历史数据,替换掉原理的流水账操作
no-appendfsync-on-rewrite
举例:
set k1 v1 + set k2 v2 压缩成 set k1 v1 k2 v2
1、auto-aof-rewrite-percentage:设置重写的基准值,文件达到100%开始重写
2、auto-aof-rewrite-min-size:设置重写的基准值,最小文件64M,达到这个值开始重写
例如:
文件达到70MB开始重写,重写为50MB,下次当100MB开始重写
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size
如果Redis的下一次AOF大小>=base_size+base_size*100%且当前大小大于64MB时开始重写
十一、RDB和AOF对比
1、到底如何选择
- 不要仅仅使用RDB这样会丢失很多数据。
- 也不要仅仅使用AOF,因为这一会有两个问题,第一通过AOF做冷备没有RDB做冷备恢复的速度快;第二RDB每次简单粗暴生成数据快照,更加健壮。
- 综合AOF和RDB两种持久化方式,用AOF来保证数据不丢失,作为恢复数据的第一选择;用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,可以使用RDB进行快速的数据恢复。
2、Redis 持久化 之 AOF 和 RDB 同时开启,Redis听谁的?
听AOF的,RDB与AOF同时开启 默认无脑加载AOF的配置文件
相同数据集,AOF文件要远大于RDB文件,恢复速度慢于RDB
AOF运行效率慢于RDB,但是同步策略效率好,不同步效率和RDB相同
十二、主从复制
1、简介
- 读写分离–主机写 从机读
- 容灾快速恢复
- 主机更新后根据配置和策略,自动同步到从机
2、演示(一主两从)
1.创建msconf文件夹存放主从配置文件
2.复制一份redis.conf到msconf
- 开启守护进程 daemonize yes
- 关闭AOF持久化 appendonly no
- 修改dump文件生成到到当前目录 dir /study/redis-6.2.6/msconf/
3.配置三个配置文件
- include /
- pidfile /
- port
- dbfilename

4.开启服务
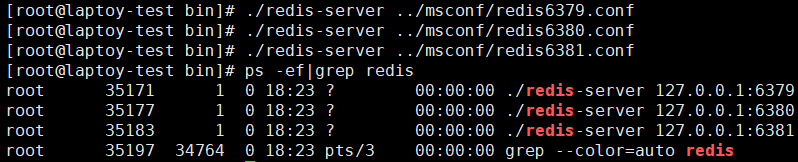
5.查看服务器状态
info replication
6、配置从机 进入从机客户端redis-cli内
slaveof 127.0.0.1 port
3、常用三招
- 1、从服务器如果停止了,重启变为master,需要重新执行该命令变为slave
- 2、主服务器如果停止了,重启还是连接着两台从服务器(你大哥还是你大哥)
1、一主二仆
一台Master多台Slave
2、薪火相传
Master的slave可以被另一台服务器slaveof
3、反客为主
Master挂掉后其中一台slave执行
slaveof no one
成为新的Master
4、复制原理
- 1、slave启动成功连接到master后会发送一个sync同步命令
- 2、当master接到slave发送过来的同步消息,首先把master数据进行持久化成rdb文件,把rdb文件发送到slave,slave拿到rdb文件进行读取
- 3、每次主服务器进行写操作后,和从服务器进行数据同步
1、全量复制:slave接收到数据库文件数据后,将其存盘并加载到内存中
2、增量复制:master继续将新的所有收集到的修改命令依次传给slave
3、但只要时重新连接master,一次完成同步(全量复制)将被自动执行

5、哨兵模式(sentinel)
反客为主的自动版,Master故障自动从Slave选出新的Master
1.新建sentinel.conf文件到/study/redis-6.2.6/msconf/
mymaster为监控对象起的服务器名称 ,1为至少有多少个哨兵同意迁移的数量
sentinel monitor mymaster 127.0.0.1 6379 1
2.启动哨兵
./redis-sentinel /study/redis-6.2.6/msconf/sentinel.conf

3.身份切换
当Master宕机,重新选举一个Slave成为新的Master,旧的Master重启后也成为Slave
4.选举优先级 redis.conf
replica-priority 100 值越小优先级越高
- 1、选择优先级靠前的
- 2、选择偏移量最大的(获得原主机数据最全的)
- 3、选择runid最小的(每个redis实例启动后随机生成40为runid)
5.复制延迟
由于所有写操作都在Master执行,然后同步更新到Slave,所以从Master同步到Slave机器有一点的延迟,当系统很繁忙的时候,延迟问题更严重,Slave机器的增加也会使这个问题更严重
十三、集群(Redis Cluster)
优点
- 实现扩容
- 分摊压力
- 无中心化配置简单
不足
- 不支持多键操作
- 不支持多键的Redis事务,不支持lua脚本
- 由于集群方案出现较晚,很多公司已经采用了其他方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大
1、简介
Redis集群实现对Redis的水平扩容,即启动N个Redis节点,将整个数据库分布存储在这N个节点中,每个节点存储数据的1/N.
Redis集群通过分区(partition)来提供一定程度的可用]性:即使有一部分节点失效或无法通讯,集群也可以处理命令请求.
2、搭建集群
1、创建6个配置文件端口号6379-6384
cluster-enabled yes 打开集群模式
cluster-config-file nodes-63xx.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间ms,集群自动进行主从切换
2、先改一份redis6379.conf
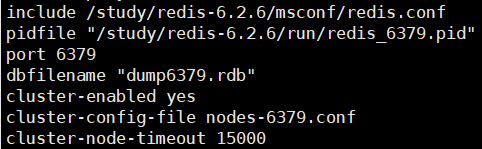
额外:在redis.conf中
- 关闭保护模式 protected-more no
- 开启外网访问 #bind:127.0.0.1
- 开启后台运行 daemonize yes
- 设置rdb文件目录 dir /study/redis-6.2.6/msconf
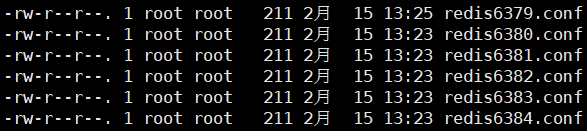
3、拷贝出其余redis63**.conf
4、更改文件内容 vi编辑器内
:%s/6379/63** 快速替换6379为63**
5、启动6个服务

6、6个节点合成集群 进入/study/redis-6.2.6/src
-replicas 1 采用最简单的方式配置集群,一主一从
../bin/redis-cli --cluster create --cluster-replicas 1 \
192.168.88.129:6379 \
192.168.88.129:6380 \
192.168.88.129:6381 \
192.168.88.129:6382 \
192.168.88.129:6383 \
192.168.88.129:6384
输入yes而不是y接受
7、集群连接(去中心化)
./redis-cli -c -p 63xx 去中心化连接客户端
-c 代表了可以自动重定向到相对应的槽位的master
./redis-cli --cluster check 192.168.88.129:6379 集群信息检查
cluster nodes 查看集群节点信息

3、集群概念
1、如何分配这六个节点?
- 一个集群至少有三个节点
- 选项 --cluster-replicas 1 表示为每个主节点创建一个从节点
- 分配原则尽量保证主数据库运行在不同IP地址,每个主库和从库不在同一个IP地址

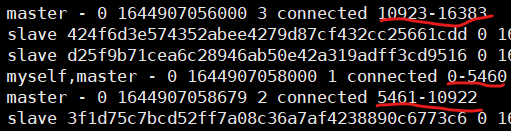
2、插槽slots
- 一个redis集群包含16384个插槽,数据库中的每个键都属于这16384个插槽中的其中一个
- 集群使用公式CRC16(key)%16384来计算键属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和
- 集群终端每个节点负责处理一部分插槽
3、在集群中录入值
1.自动切换到对应master

2.不在一个slot下的键值是不能直接使用mset,mget操作

解决:用{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去
mset name{user} jiali age{user} 21 用user计算插槽


3.常用命令
cluster keyslot <key> 计算key的插槽值
cluster countkeysinslot <slot> 返回slot槽中的键(需要在对应插槽范围内进行查询)
cluster getkeysinslot <slot> <count> 返回count个slot槽中的键
4.故障恢复
- 主机宕机后从机上位,旧主机启动后变为从机
- 如果某一点插槽的主从全部宕机,根据redis,conf
---- 且cluster-require-full-coverage yes,那么整个集群都挂掉
---- 且cluster-require-full-coverage no , 那么该插槽数据全部不能使用,也无法存储
4、Jedis操作集群
public class RedisCluster {
public static void main(String[] args) {
//创建对象
HostAndPort hostAndPort = new HostAndPort("192.168.88.129", 6379);
JedisCluster jedisCluster = new JedisCluster(hostAndPort);
jedisCluster.set("name", "laptoy");
System.out.println(jedisCluster.get("name"));
jedisCluster.close();
}
}
十四、缓存穿透、击穿、雪崩、分布式锁
缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。

1、缓存穿透
1、问题
key对应的数据源并不存在,每次针对此key的请求从缓存中获取不到,请求会压倒数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户请求,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。

2、解决
- 对空值缓存:如果一个查询返回为空,仍把空值缓存并设置短过期时间不超过五分钟
- 设置可访问的名单:使用bitmaps定义一个可以访问的名单,id作为bitmaps的偏移量,每次访问和bitmaps里面的id进行比较,如果id不在名单内,进行拦截,不允许访问
- 采用布隆过滤器:实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)
- 进行实时监控:当发现Redis的命中率开始急速降低,进行排查
2、缓存击穿(热点数据过期)
1、问题
某个热点key对应的数据存在,但在redis中过期,此时若有大量的并发请求进来,这些请求发现缓存过期一般都会从后台DB加载数据并设置缓存,这个时候大并发的请求会瞬间把DB压垮

2、解决
- 预先设置热点数据,加大热门数据key的时长
- 实时调整key的过期时间
- 使用锁
在缓存失效的时候,先使用缓存工具的某些带成功操作返回值的操作(setnx key不存在时设置)
当操作返回成功时,在进行load db操作,并回设缓存,最后删除该key
当操作失败返回,证明又线程在load db,当前线程睡眠一段时间再重试get缓存方法

3、缓存雪崩
1、描述
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。

2、解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 构建多级缓存架构:nginx缓存+redis缓存+其他缓存
- 使用锁或者队列
- 设置过期标志自动更新缓存
4、分布式锁
set <key> <value> nx ex <time> 上锁并设置过期时间
del <key> 释放锁
@GetMapping("/testLock")
public void testLock() {
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
if (lock) {
Object value = redisTemplate.opsForValue().get("num");
if (!StringUtils.isEmpty(value)) {
int num = Integer.parseInt(value + "");
redisTemplate.opsForValue().set("num", ++num);
//释放锁
String lockValue = (String) redisTemplate.opsForValue().get("lock");
//解决锁误删,只能释放自己的锁
if(uuid.equals(lockValue)){
redisTemplate.delete("lock");
}
}
} else {
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以上还需进行lua脚本改进原子性
if(uuid.equals(lockValue)){
redisTemplate.delete("lock");
}
//又可能判断uuid相等后卡住了导致锁自动释放后删除其他锁
1、满足以下要求
- 互斥性。在任一时刻,只要一个客户端能持有锁
- 不会发生死锁------------------------------设置过期时间
- 加锁和解锁必须是同一个客户端------设置随机uuid
- 加锁和解锁必须具有原子性-------------Lua脚本
十五、Redis6新特性
1、ACL
在redis6以前,无法进行用户权限管理,只有一个auth密码验证的功能,如果验证码通过那么就是root权限,如果我们想要禁用一些redis指令,只能使用rename将原指令名字修改,这样做很不方便。而在redis6中引入了ACL模块,可以定制不同用户的权限,包括:
- 用户名和密码。
- 可以执行的指令。
- 可以操作的key。
root密码登入的用户名为default,查看ACL列表的指令为:ACL LIST。
127.0.0.1:6379> acl list
# 格式为:user 用户名 on 密码(如果没有密码那么为nopass) 可以执行的指令 可以操作的key
1) "user default on #06f2fc19c20fc7aae5e74974e7ea85fab4093055564939ebf2102d9ed3d13afc ~* +@all"
2) "user bigkai on #565c9a0d69440194596f8bf3cf3c5b1f904245f5c539a72a5a4f9baddd933dce ~* +@all -set"
ACL规则:下面是有效ACL规则的列表。某些规则只是用于激活或删除标志,或对用户ACL执行给定更改的单个单词。其他规则是字符前缀,它们与命令或类别名称、键模式等连接在一起。
1、启动和禁用用户:
on:激活某用户账号。off:禁用某用户账号。注意,已验证的连接仍然可以工作。如果默认用户被标记为off,则新连接将在未进行身份验证的情况下启动,并要求用户使用AUTH选项发送AUTH或HELLO,以便以某种方式进行身份验证。
2、权限的添加删除:

3、可操作键的添加或删除:
~<pattern>:添加可作为用户可操作的键的模式。例如~*允许所有的键。
acl cat 查看所有指令分类
acl setuser cat 查看某个分类下的指令
# acl setuser 用户名 on 密码(可多个) 权限 键模式
acl setuser testuser on >testuser1 >testuser2 >testuser3 +@all ~*
acl setuser testuser off 禁用用户
acl users 查看所有用户
acl list 展现用户权限列表
acl whoami 查看当前用户
acl deluser test 删除当前用户
2、多线程I/O
- CPU成为redis瓶颈的情况并不常见,可能性更高的是内存和网络的约束。
- 从redis4开始会将多线程技术用于数据清理、模块方法调用。
然后现在为了解决网络IO的问题,redis使用了多进程,对网络事件进行电梯,分发给工作线程处理,处理完之后再交给主线程进行执行操作,执行之后交给工作线程回写响应数据


















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











