









CVPR2015:
Show and Tell: A Neural Image Caption Generator
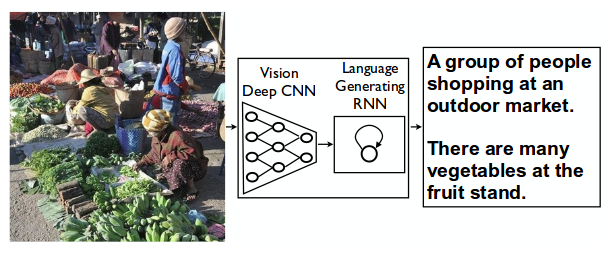
to use a CNN as an image “encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences.
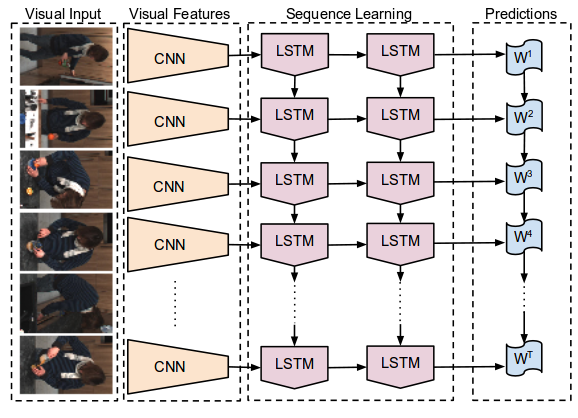
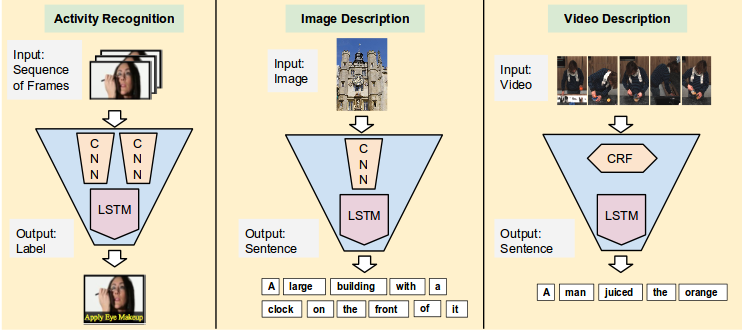
Long-term Recurrent Convolutional Networks
ICCV2015:
Deep Residual Learning for Image Recognition
Training Very Deep Networks
Two-Stream Convolutional Networks for Action Recognition in Videos
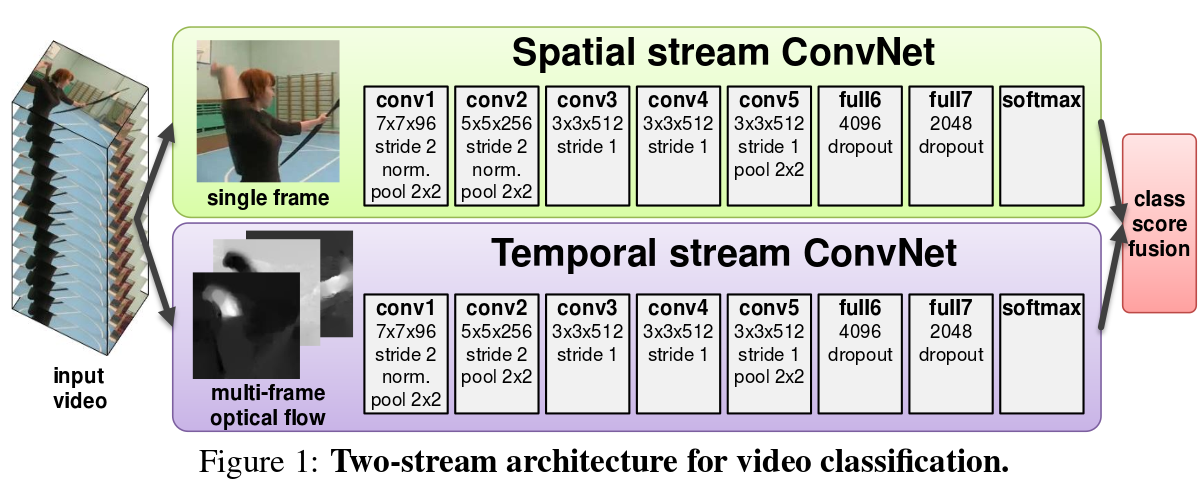
The spatial part, in the form of individual frame appearance, carries information about scenes and objects depicted in the video. The temporal part, in the form of motion across the frames, conveys the movement of the observer (the camera) and the objects.
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://zhangliliang.com/2014/09/13/paper-note-sppnet/
http://backnode.github.io/pages/2015/11/11/spp-net.html
http://blog.csdn.net/chenriwei2/article/details/38047119
传统的CNN限制了输入必须固定大小(比如AlexNet是224x224),所以在实际使用中往往需要对原图片进行crop或者warp的操作
crop:截取原图片的一个固定大小的patch
warp:将原图片的ROI缩放到一个固定大小的patch
无论是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中。
crop:物体可能会产生截断,尤其是长宽比大的图片。
warp:物体被拉伸,失去“原形”,尤其是长宽比大的图片
常规的DeepCNN要求输入图像尺寸固定是因为在全连接层中要求输入固定长度的特征向量,而全连接层之前的卷积pooling层并不严格要求输入图像的尺寸固定。卷积pooling层的输出尺寸比例基本和输入图像的尺寸比例一致,这些输出就是所谓的特征图(feature map)。
思路很直观,首先发现了,CNN的卷积层是可以处理任意尺度的输入的,只是在全连接层处有限制尺度——换句话说,如果找到一个方法,在全连接层之前将其输入限制到等长,那么就解决了这个问题。

文章利用了空间金字塔池化(spatial pyramidpooling(SPP))层来去除网络固定大小的限制,也就是说,将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,它的输出然后再送到第一个全连接层。也就是说在卷积层和全连接层之前,我们导入了一个新的层,它可以接受不同大小的输入但是产生相同大小的输出;这样就可以避免在网络的输入口处就要求它们大小相同,也就实现了文章所说的可以接受任意输入尺度;
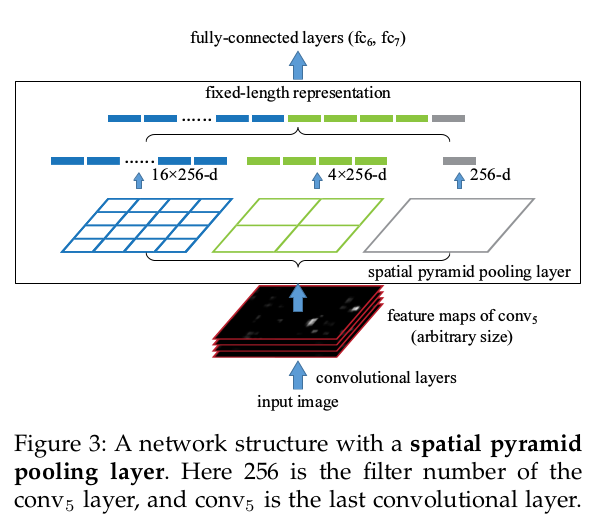
如果原图输入是224x224,对于conv5出来后的输出,是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。
如果像上图那样将reponse map分成4x4 2x2 1x1三张子图,做max pooling后,出来的特征就是固定长度的(16+4+1)x256那么多的维度了。
如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256
直觉地说,可以理解成将原来固定大小为(3x3)窗口的pool5改成了自适应窗口大小,窗口的大小和reponse map成比例,保证了经过pooling后出来的feature的长度是一致的
//TO BE CONTINUED














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









