







其它章节内容请见机器学习之PyTorch和Scikit-Learn
在第4章 构建优秀的训练数据集 – 数据预处理中,我们学习了使用特征选择技术对数据集降维的不同方法。特征选择以外的另一种降维方法是特征提取。本章中我们会学习两种基本技术,可帮助我们通过将其变换为比原来更低维度的特征子空间总结出数据集中的信息内容。数据压缩是机器学习中非常重要的课题,它有助于我们存储和分析现代技术时代生产和收集的与日俱增的数据。
本章中我们会讲解如下内容:
- 用于无监督数据压缩的主成分分析
- 最大化类别分割性监督降维的线性判别分析
- 非线性降维技术的概览及用于数据可视化的t-分布随机近邻嵌入
通过主成分分析的无监督降维
类似于特征选择,我们可以使用不同的特征提取技术来减少数据集中的特征数量。特征选择与特征提取的不同之处在于使用特征选择算法时我们保留原始特征,如序列后向选择,我们使用特征提取变换或投射数据到新的特征空间上。
在进行降维时,特征提取可以理解为一种数据压缩技术,目标是保留大部分相关信息。实操时,特征提取不仅用于改善存储空间或学习算法的计算效率,还通过降低维数灾难来改善预测性能,在处理非正则化模型时尤其如此。
主成分分析中的主要步骤
本节中我们会讨论主成分分析(PCA),一种广泛用于不同领域的无监督线性变换技术,对特征提取和降维尤为突出。其它知名的PCA应用有股票市场交易中的探索性数据分析及信号去噪,以及生物信息领域的基因数据分析和基因表达水平。
PCA帮助我们根据特征间关联识别数据中的模式。总之,PCA旨在找到高维数据中的最大方差方向并将数据投射到新的子空间上,维数等于或小于原空间。新子空间的正交轴(主成分)可解释为限定新特征轴彼此正交时最大方差的方向,如图5.1所示:
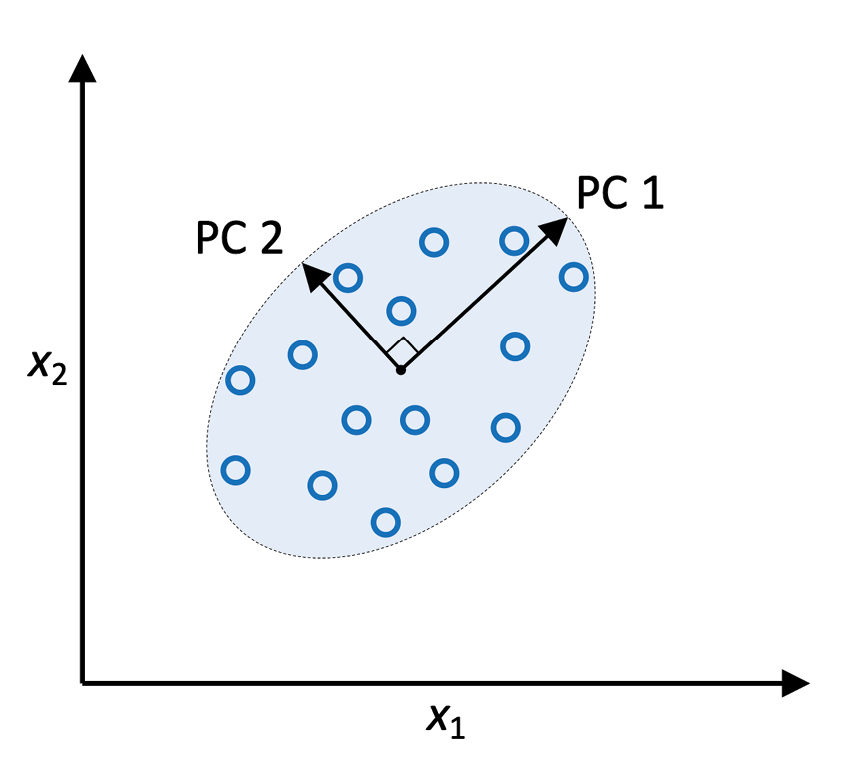
图5.1:使用PCA查找数据集中的最大方差方向
在图5.1中,x1和x2是原始特征轴,PC 1和PC 2是主成分。
如果使用PCA降维,我们会构建一个d×k维的变换矩阵W,可以将训练样本特征的向量x映射到一个新的k-维特征子空间,其维数少于原始的d-维特征空间。例如下面的流程。假设我们有一个特征向量x:

然后通过变换矩阵进行变换, W ∈ R d × k W\in \mathbb{R}^{d\times k} W∈Rd×k:
xW = z
产生输出向量:

将原始d-维数据转换到新的k-维子空间(通常k << d)上的结果是,第一个主成分会拥有最大的方差。后续的主成分在这些成分与其它主成分不相关(正交)时会具有最大方差,即例输入特征相关联,得到的主成分也互为正交(不相关)。注意PCA的方向对数据缩放超级敏感,如果特征使用不同量级度量而我们又希望为所有特征赋相同的重要性,那么应需要在做PCA之前标准化特征。
在更进一步学习用PCA算法实现降维前,我们先将该方法总结成简单的步骤:
- 标准化d-维数据集。
- 构建协方差矩阵。
- 将协方差分解为特征向量(eigenvectors)和特征值(eigenvalues)。
- 通过特征值降序排列相应的特征向量。
- 选取k最大特征值的k特征向量,其中k是新特征字空间的维数( k ≤ d k\le d k≤d)。
- 通过“头部”k特征向量构建投影矩阵W。
- 使用投影矩阵W变换d-维输入数据集X,获取一新的 k-维特征子空间。
在下面的小节中,作为练习我们会使用Python逐步执行PCA。然后我们会学习如何使用scikit-learn更便利地执行PCA。
特征分解:将矩阵分解为特征向量和特征值
特征分解,将方阵分解为特征值和特征向量,是本节中所述的PCA处理的信心。
协方差矩阵是方阵的一种特例:它是一个对称矩阵,也就是矩阵与其转置相等,A = AT。
在分解这种对称矩阵时,特征值是实数(而非复数),特征向量彼此正交(垂直相交)。此外,特征值与特征向量成对出现。如果将协方差矩阵分解为特征向量和特征值,与最高特征值相关联的特征向量对数据集中最大方差的方向。这里的“方向”是数据集特征列的线性变换。
有关特征值和特征向量更深入的讨论不在本书范畴内,比较详尽的参考资料请见维基百科:https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors。
分步提取主成分
在本小节中,我们会处理PCA的前四个步骤:
- 标准化数据
- 构建协方差矩阵
- 获取协方差矩阵的特征值和特征向量
- 以特征值降序排列特征向量
首先我们会加载第4章 构建优秀的训练数据集 - 数据预处理中使用的葡萄酒数据集:
>>> import pandas as pd
>>> df_wine = pd.read_csv(
... 'https://archive.ics.uci.edu/ml/'
... 'machine-learning-databases/wine/wine.data',
... header=None
... )
获取葡萄酒数据集
可以在本书代码库中找到一份葡萄酒数据集(以及本书中使用的其它数据集)的拷贝,以防读者离线操作或是UCI服务器上https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data临时断网。比如我们从本地目录读者葡萄酒数据集,只需将如下行:
df = pd.read_csv( 'https://archive.ics.uci.edu/ml/' 'machine-learning-databases/wine/wine.data', header=None )替换为:
df = pd.read_csv( 'your/local/path/to/wine.data', header=None )
接下来我们会将葡萄酒数据分成训练集和测试集,分别占70%和30%,并将其标准化为单位方差:
>>> from sklearn.model_selection import train_test_split
>>> X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
>>> X_train, X_test, y_train, y_test = \
... train_test_split(X, y, test_size=0.3,
... stratify=y,
... random_state=0)
>>> # standardize the features
>>> from sklearn.preprocessing import StandardScaler
>>> sc = StandardScaler()
>>> X_train_std = sc.fit_transform(X_train)
>>> X_test_std = sc.transform(X_test)
通过以上代码完成自主预处理后,我们进入第2步:构建协方差矩阵。对称的d×d-维协方差矩阵,其中d是数据集中的维数,存储着不同特征间的成对协方差。例如,特征xj和xk之间对总体的协方差可通过如下等式计算:

这里的 μ j \mu_j μj和 μ k \mu_k μk分别是样本j和k的均值。注意如果我们标准化了数据集那么样本均值就是0。两个特征间的协方差为正值表示特征同时上升或下降,或负协方差则表示特征的方向相反。例如,三个特征的协方差矩阵可以写成如下这样(注意这里的 Σ \Sigma Σ是大写希腊字母,不要与加和符号相混淆):

协方差矩阵的特征向量表示主成分(最大方差的方向),而对应的特征值则定义它们的量级。就葡萄酒一例来说,我们获取了12个特征向量以及13×13-维协方差矩阵中的值。
下面到第3步,我们来获取协方差矩阵的特征对。如果读者学过线性代码,可能学过满足以下条件的特征向量v:

这里的
λ
\lambda
λ是一个标量:特征值。因手动计算特征向量和特征值枯燥且需要细心,我们会使用NumPy中的linalg.eig函数来得到葡萄酒协方差矩阵的特征对:
>>> import numpy as np
>>> cov_mat = np.cov(X_train_std.T)
>>> eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)
>>> print('\nEigenvalues \n', eigen_vals)
Eigenvalues
[ 4.84274532 2.41602459 1.54845825 0.96120438 0.84166161
0.6620634 0.51828472 0.34650377 0.3131368 0.10754642
0.21357215 0.15362835 0.1808613 ]
使用numpy.cov函数,我产计算了标准化的训练集的协方差矩阵。使用linalg.eig函数,我们执行了特征分解,这会产生一个包含13个特征值和对应的存储为13×13-维矩阵的特征向量(eigen_vecs)的向量(eigen_vals)。
NumPy中的特征分解
numpy.linalg.eig设计用于操作对称及非对称方阵。但在有些情况下会发现它返回的是复数特征值。相关的函数
numpy.linalg.eigh,是为分解共轭(Hermetian)矩阵而实现的,对于处理协方差矩阵这样的对称矩阵在数值上更为稳定,numpy.linalg.eigh一定会返回实数特征值。
总方差和可解释方差
因为我们希望通过将数据集压缩到新的特征子空间上实现降维,所以只选择了包含大部分信息(方差)的特征向量子集(主成分)。特征值定义了特征向量的量级,所以我们按降序对特征值排序,我们感兴趣的是相应特征值得到的k个最高特征向量。但在采集这k个信息最丰富的特征向量前,我们先绘制特征值的方差解释率。特征值 λ j \lambda_j λj的方差解释率,只需使用特征值 λ j \lambda_j λj比上特征值的加和:

通过NumPy的cumsum函数,我们可以计算出可解释方差的汇总,然后使用Matplotlib的step函数绘图:
>>> tot = sum(eigen_vals)
>>> var_exp = [(i / tot) for i in
... sorted(eigen_vals, reverse=True)]
>>> cum_var_exp = np.cumsum(var_exp)
>>> import matplotlib.pyplot as plt
>>> plt.bar(range(1,14), var_exp, align='center',
... label='Individual explained variance')
>>> plt.step(range(1,14), cum_var_exp, where='mid',
... label='Cumulative explained variance')
>>> plt.ylabel('Explained variance ratio')
>>> plt.xlabel('Principal component index')
>>> plt.legend(loc='best')
>>> plt.tight_layout()
>>> plt.show()
生成的图表明仅第一个主成分就占了方差的大约40%。
同时,我们可以看出前两个主成分合起来用解释了数据集中差不多60%的方差:
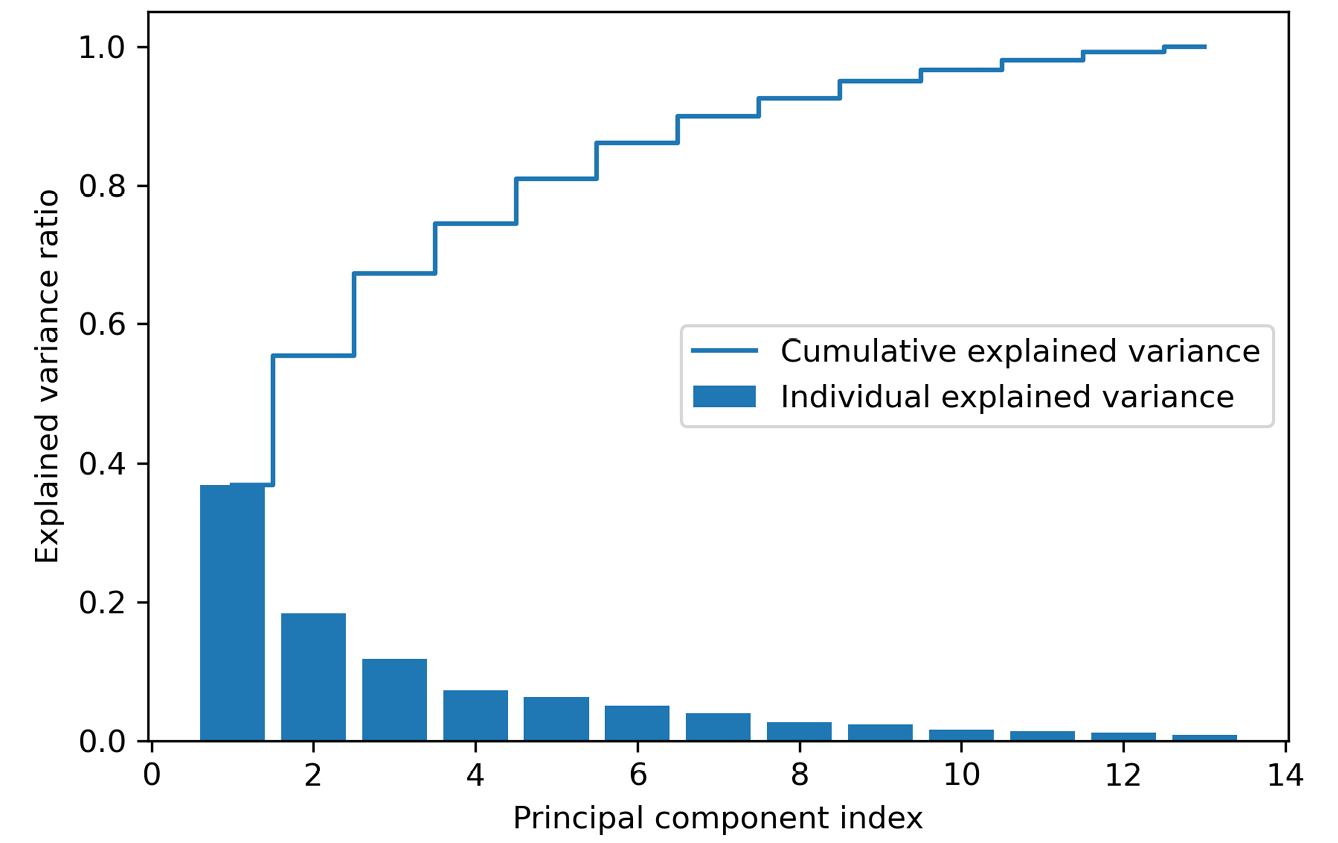
图5.2:通过主成分捕获的总方差比例
虽然可解释方差图让我们想起了第4章 构建优秀的训练数据集 - 数据预处理中随机森林的特征重要性值,但读者要记住PCA是一种无监督方法,表示它会忽略类标签的信息。而随机森林使用类成员信息来计算节点杂度,方差度量沿特征轴的扩展程度。
特征变换
我们已经成功将协方差矩阵分解为了特征对,下面继续将葡萄酒数据集变换为主成分轴的最后3个步骤。本节中将处理的剩余步骤为:
- 选取k最大特征值的k特征向量,其中k是新特征子空间的维数( k ≤ d k\le d k≤d)。
- 通过“头部”k个特征向量构建投影矩阵W。
- 使用投影矩阵W变换d-维输入数据集X,获取一个新的k-维特征子空间。
换句不那么技术的话来说,我们会按特征值降序排列特征对,通过选中的特征向量构建投影矩阵,并使用投影矩阵将数据变换到更低维的子空间上。
我们先通过特征值降序排列特征对:
>>> # Make a list of (eigenvalue, eigenvector) tuples
>>> eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i])
... for i in range(len(eigen_vals))]
>>> # Sort the (eigenvalue, eigenvector) tuples from high to low
>>> eigen_pairs.sort(key=lambda k: k[0], reverse=True)
接着采集对应最大的两个特征值的特征向量,囊括本数据集中差不多60%的方差。注意这里选择两个特征向量是便于绘图,因为我们在本节稍后会使用二维散点图来绘制数据。在实操中,主成分的数量根据计算效率和分类器表现进行权衡:
>>> w = np.hstack((eigen_pairs[0][1][:, np.newaxis],
... eigen_pairs[1][1][:, np.newaxis]))
>>> print('Matrix W:\n', w)
Matrix W:
[[-0.13724218 0.50303478]
[ 0.24724326 0.16487119]
[-0.02545159 0.24456476]
[ 0.20694508 -0.11352904]
[-0.15436582 0.28974518]
[-0.39376952 0.05080104]
[-0.41735106 -0.02287338]
[ 0.30572896 0.09048885]
[-0.30668347 0.00835233]
[ 0.07554066 0.54977581]
[-0.32613263 -0.20716433]
[-0.36861022 -0.24902536]
[-0.29669651 0.38022942]]
执行以上代码,我们通过最高的两个特征向量创建了一个13×2维的投影矩阵W。
镜像投影
根据所使用的NumPy和LAPACK的版本,可能会获得符号相反的矩阵W。这并不是什么问题,如果v是矩阵 Σ \Sigma Σ的特征向量:
这里的v是特征向量,–v也是一个特征向量,可在下面看到。使用基础代数,可以在等式两边都乘上一个标量 α \alpha α:
因矩阵乘法对标量具有结合律,可重新排列如下:
现在可以看到在 α = 1 \alpha=1 α=1和 α = − 1 \alpha=-1 α=−1时 α v \alpha v αv是相同特征值 λ \lambda λ的特征向量。因此v和–v 都是特征向量



使用投影矩阵,我们可以将示例x(表现为13-维的行向量)变换到PCA子空间(主成分1和2)上获取 x′,这时它是一个包含两个新特征的二维示例向量:
x′ = xW
>>> X_train_std[0].dot(w)
array([ 2.38299011, 0.45458499])
类似地,我们可以通过计算矩阵点乘把整个124×13-维训练集变换成两个主成分:
X′ = XW
>>> X_train_pca = X_train_std.dot(w)
最后,我们来可视化变换后的葡萄酒训练集,现在以一个二维散点图存储着一个124×2-维矩阵:
>>> colors = ['r', 'b', 'g']
>>> markers = ['o', 's', '^']
>>> for l, c, m in zip(np.unique(y_train), colors, markers):
... plt.scatter(X_train_pca[y_train==l, 0],
... X_train_pca[y_train==l, 1],
... c=c, label=f'Class {l}', marker=m)
>>> plt.xlabel('PC 1')
>>> plt.ylabel('PC 2')
>>> plt.legend(loc='lower left')
>>> plt.tight_layout()
>>> plt.show()
由图5.3可以看出,数据沿第一个主成分(x轴)要比第二个主成分(y轴)散得更开,这与前面小节中创建的可解释方差率图是一致的。但我们能看出一个线性分类器很可能可以很好地进行分类:
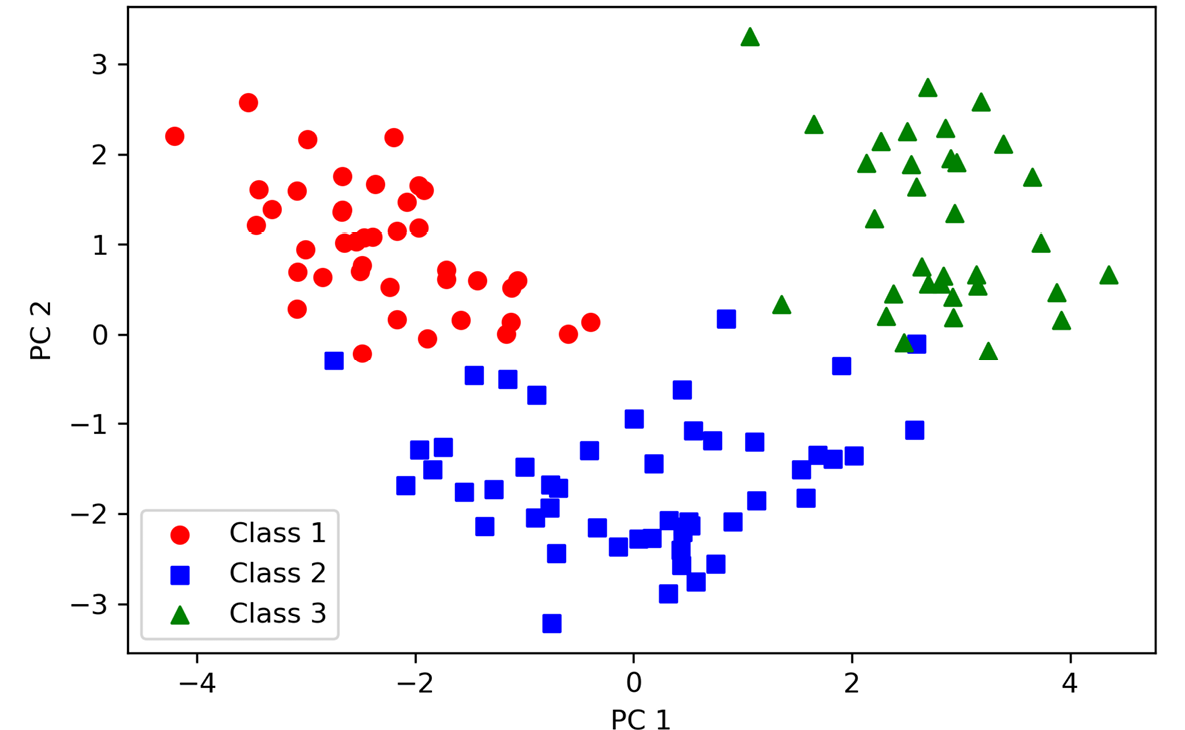
图5.3:通过PCA将葡萄酒数据记录投射到2D特征空间
虽然我们编码类标签信息的目的是绘制上面的散点图,但要谨记PCA是一种不使用任何类标签信息的无监督技术。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









