







作者: 王智民
贡献者:
创建时间: 2013-8-8
稳定程度: 初稿
修改历史
| 版本 | 日期 | 修订人 | 说明 |
| 1.0 | 2013-8-8 | 王智民 | 初稿 |
目录
1 引言 1
1.1 编写目的 1
1.2 背景 1
2 框架分析 1
2.1 0层分解 1
2.2 1层分解 3
2.3 2层分解 4
2.3.1 Lib的核心组件 4
2.3.2 DPDK依赖于linux内核有哪些 4
2.3.3 DPDK如何做到用户空间直接访问网络IO 5
2.3.4 DPDK如何管理接口 6
2.3.5 DPDK如何与linux交互报文 7
2.3.6 DPDK如何支持Intel网卡的SR-IOV或VMDq模式 9
2.3.7 采用DPDK EAL的应用程序如何运行 10
2.3.8 DPDK如何管理报文及对jumbo frame的支持 12
2.3.9 DPDK的应用程序之间如何通信 14
2.3.10 DPDK提供的几种应用程序运行模式 15
2.3.11 DPDK如何支持multi-chips的 15
2.3.12 如何用DPDK开发数据通信产品 17
3 案例分析—6wind 21
3.1 网络设备框架 21
3.2 VIRTUAL FAST PATH 24
3.3 VNB 24
3.4 管理框架 24
4 总结 25
5 附录 26
5.1 本子系统用到的缩写词、定义和术语 26
5.2 参考资料 26
-
引言
-
编写目的
-
本文档结合手册和软件包分析了Intel DPDK的框架和一些关键问题的解决方案。
-
背景
Intel DPDK为一些采用Intel芯片的网络厂商和安全厂商提供了一个完整的开发环境,在业界引起了不小的轰动,同时多家安全厂商由于自身实力的限制,很欢迎这种免费或者代价不昂贵的解决方案,而Intel也很乐意做这样的事情。
有代表性的厂商比如WindRiver,前期以做vxWorks操作系统非常知名,后来被Intel收购后全面切向支持Intel的系列软件解决方案。
一方面Intel推出的Sandy Bridge芯片,CPU的IO方面做了一定的改进,号称大包可以做到5元组转发40G的处理能力,另外一方面,Intel借助WindRiver的软件解决能力,提出DPDK的数据处理解决方案,所以值得分析DPDK。
-
框架分析
-
0层分解
-
0层分解主要描述DPDK与其他外部的关系。
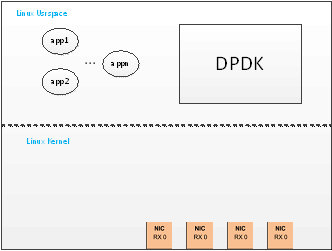
DPDK是Intel在linux用户空间提供的一套数据转发与处理的运行框架,其目的是提高运行在Intel的系列(从Atom到Xeon系列)的linux系统的数据报文吞吐能力。
DPDK类似一个小的操作系统,所以凡是操作系统涉及的内容在DPDK里面都应该需要提供相应的API接口和实现,主要有:
• Intel® DPDK loading and launching
• Support for multi-process and multi-thread execution types
• Core affinity/assignment procedures
• System memory allocation/de-allocation
• Atomic/lock operations
• Time reference
• PCI bus access
• Trace and debug functions
• CPU feature identification
• Interrupt handling
• Alarm operations
-
1层分解



-
2层分解
-
Lib的核心组件
-
DPDK提供的库基本上实现小型操作系统的相关功能。其核心组件如下:
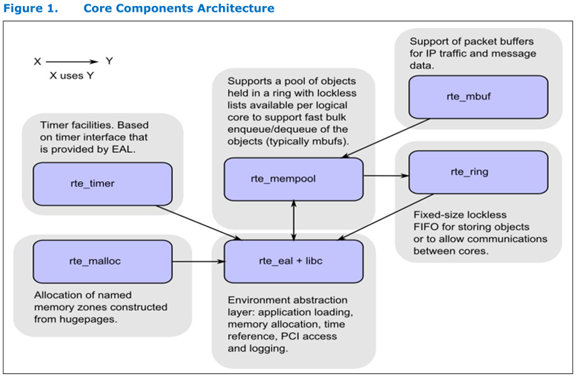
-
DPDK依赖于linux内核有哪些
DPDK目的是在linux用户空间打造出一套报文转发处理的框架,但是下面的一些资源不得不需要修改或依赖于linux内核:
-
用户空间访问网络接口驱动uio模块
需要linux内核加载uio.ko模块,同时需要加载DPDK生成的igb_uio.ko模块,使得DPDK可以在用户空间直接访问到网络接口IO。
-
大页面支持(DPDK支持huge page,所以需要连续的大内存支持)
Linux内核配置需要使能HUGETLBFS。同时PROC_PAGE_MONITOR特性也需要打开。
在linux启动的时候需要为DPDK预留部分hugepages,所以做如下的设置:
For 2 MB pages, just pass the hugepages option to the kernel. For example, to reserve 1024 pages of 2 MB, use:
hugepages=1024
For other hugepage sizes, for example 1G pages, the size must be specified explicitly and can also be optionally set as the default hugepage size for the system. For example, to reserve 4G of hugepage memory in the form of four 1G pages, the following options should be passed to the kernel:
default_hugepagesz=1G hugepagesz=1G hugepages=4
Note: The hugepage sizes that a CPU supports can be determined from the CPU flags.If "pse"exists, 2M hugepages are supported; if "pdpe1gb" exists, 1G hugepages are supported.
Note: For 64-bit applications, it is recommended to use 1 GB hugepages if the platform supports them.
Note: If using a large number of hugepages, for example, 500 or more, it is advisable toincrease the open files limit of the current login session to prevent errors when running Intel® DPDK applications. Increasing the limit can be done using the ulimit command, ulimit -Sn 2048 for example.
In the case of a dual-socket NUMA system, the number of hugepages reserved at boot time is generally divided equally between the two sockets (on the assumption that sufficient memory is present on both sockets).
-
HEPT时钟(不是必选,可以用RTC)
需要在BIOS设置。
-
DPDK如何做到用户空间直接访问网络IO
DPDK提供两种方式:一种是用户空间接管IO,另外一种方式是用户空间通过FIFO共享内存方式访问linux内核管理的IO。
先分析第一种方式。
通过igb_uio.ko内核模块来实现用户空间访问IO,同时igb_uio.ko依赖于linux本身的模块uio.ko。实现在igb_uio.c文件。
1)PCI网卡驱动接管
igbuio_pci_probe()
udev->info.handler = igbuio_pci_irqhandler;
udev->info.irqcontrol = igbuio_pci_irqcontrol;
udev->info.priv = udev;
udev->pdev = dev;
…
if (uio_register_device(&dev->dev, &udev->info))2)如何从PCI网卡收发报文
eth_igb_dev_init()
…
eth_dev->rx_pkt_burst = ð_igb_recv_pkts;
eth_dev->tx_pkt_burst = ð_igb_xmit_pkts;…
第二种方式:rte_kni.c
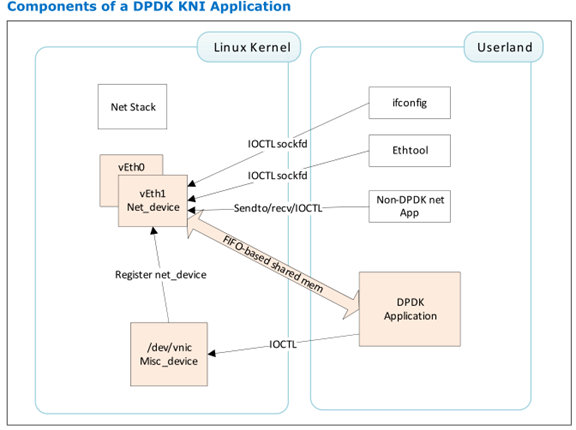
The Intel® DPDK Kernel NIC Interface (KNI) allows userspace applications access to the Linux* control plane.
The benefits of using the Intel® DPDK KNI are:
• Faster than existing Linux TUN/TAP interfaces (by eliminating system calls and
copy_to_user()/copy_from_user() operations.
• Allows management of Intel® DPDK ports using standard Linux net tools such as
ethtool, ifconfig and tcpdump.
• Allows an interface with the kernel network stack.
kni_net.c文件里面主要提供FIFO通信接口,用户空间如何通过FIFO发送和接收报文。
-
DPDK如何管理接口
DPDK提供两种方式:一种是用户空间接管IO,另外一种方式是用户空间通过FIFO共享内存方式访问linux内核管理的IO。
如果是第一种方式,那么相当于Linux内核无法感知到相关的IO接口(至少是DPDK接管了中断,比如接口链路状态的中断等),如果DPDK不接管IO的所有中断或处理,那么则接口IO一部分由Linux来管理,一部分由DPDK来管理。如果DPDK完全接管IO,那么则存在下面几个问题如何解决?
-
开源的一些应用程序需要修改有关接口的处理,以适应DPDK的EAL
-
DPDK如何与Linux内核通信
-
DPDK如何与linux交互报文
-
DPDK提供了一种exception path的解决方案,即DPDK与Linux内核之间通过tun/tap逻辑接口来实现相互的报文发送与接收,业务设计者可以决定哪些报文需要从DPDK送到linux内核继续处理,或反之从linux内核的报文送到DPDK处理。
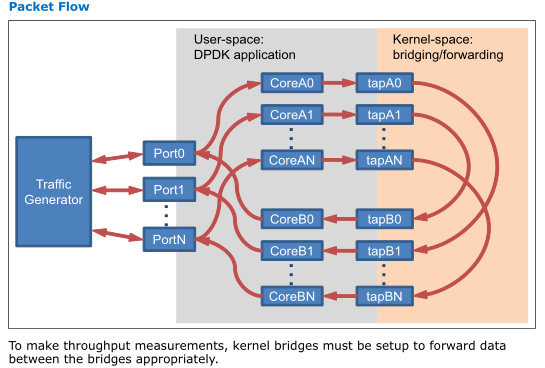
代码分析:
static __attribute__((noreturn)) int main_loop(__attribute__((unused)) void *arg)
{
…
rte_snprintf(tap_name, IFNAMSIZ, "tap_dpdk_%.2u", lcore_id);
tap_fd = tap_create(tap_name);
if (tap_fd < 0)
FATAL_ERROR("Could not create tap interface \"%s\" (%d)",
tap_name, tap_fd);
if ((1 << lcore_id) & input_cores_mask) {//可以设置哪些core从网口收上来的报文需要送到linux
PRINT_INFO("Lcore %u is reading from port %u and writing to %s",
lcore_id, (unsigned)port_ids[lcore_id], tap_name);
fflush(stdout);
for (;;) {
struct rte_mbuf *pkts_burst[PKT_BURST_SZ];
unsigned i;
const unsigned nb_rx =
rte_eth_rx_burst(port_ids[lcore_id], 0,
pkts_burst, PKT_BURST_SZ);
lcore_stats[lcore_id].rx += nb_rx;
for (i = 0; likely(i < nb_rx); i++) {
struct rte_mbuf *m = pkts_burst[i];
int ret = write(tap_fd,
rte_pktmbuf_mtod(m, void*),
rte_pktmbuf_data_len(m));
rte_pktmbuf_free(m);
if (unlikely(ret < 0))
lcore_stats[lcore_id].dropped++;
else
lcore_stats[lcore_id].tx++;
}
}
}
else if ((1 << lcore_id) & output_cores_mask) {//可以设置linux的报文送到哪些core上面去
PRINT_INFO("Lcore %u is reading from %s and writing to port %u",
lcore_id, tap_name, (unsigned)port_ids[lcore_id]);
fflush(stdout);
for (;;) {
int ret;
struct rte_mbuf *m = rte_pktmbuf_alloc(pktmbuf_pool);
if (m == NULL)
continue;
ret = read(tap_fd, m->pkt.data, MAX_PACKET_SZ);
lcore_stats[lcore_id].rx++;
if (unlikely(ret < 0)) {
FATAL_ERROR("Reading from %s interface failed",
tap_name);
}
m->pkt.nb_segs = 1;
m->pkt.next = NULL;
m->pkt.pkt_len = (uint16_t)ret;
m->pkt.data_len = (uint16_t)ret;
ret = rte_eth_tx_burst(port_ids[lcore_id], 0, &m, 1);
if (unlikely(ret < 1)) {
rte_pktmbuf_free(m);
lcore_stats[lcore_id].dropped++;
}
else {
lcore_stats[lcore_id].tx++;
}
}
}
else {
PRINT_INFO("Lcore %u has nothing to do", lcore_id);
for (;;)
;
}
}
-
DPDK如何支持Intel网卡的SR-IOV或VMDq模式
Supported Intel® Ethernet Controllers support the following modes of operation in a virtualized environment:
• SR-IOV mode: Involves direct assignment of part of the port resources to different guest operating systems using the PCI-SIG Single Root I/O Virtualization (SR IOV) standard, also known as "native mode" or "pass-through" mode.
• VMDq mode: Involves central management of the networking resources by an IO Virtual Machine (IOVM) or a Virtual Machine Monitor (VMM), also known as "software switch acceleration" mode. In this chapter, this mode is referred to as theNext Generation VMDq mode.
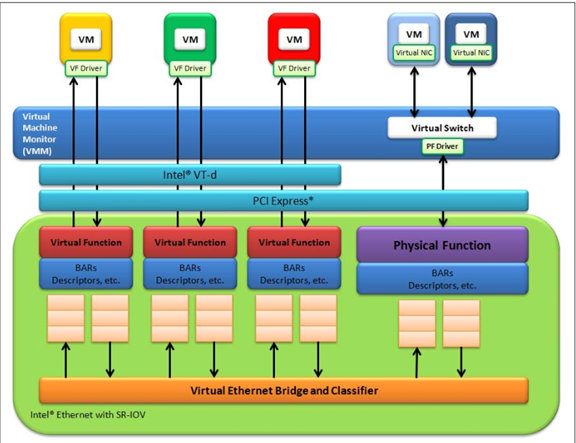
A Virtual Function has basic access to the queue resources and control structures of the queues assigned to it. For global resource access, a Virtual Function has to send a request to the Physical Function for that port, and the Physical Function operates on the global resources on behalf of the Virtual Function. For this out-of-band communication, an SR-IOV enabled NIC provides a memory buffer for each Virtual Function, which is called a "Mailbox".
-
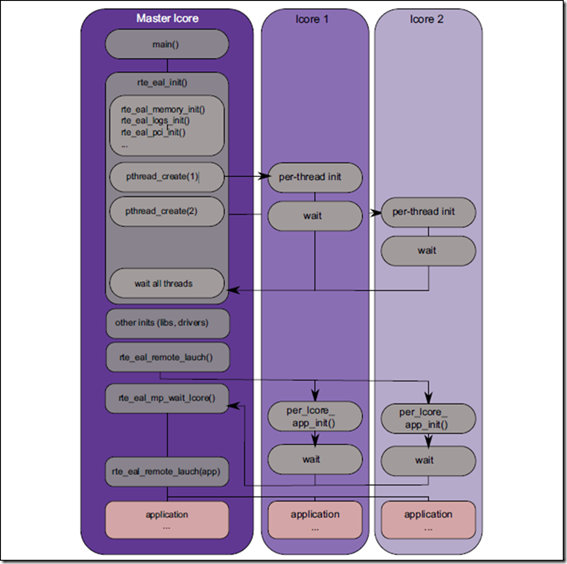
采用DPDK EAL的应用程序如何运行
Note:The UIO drivers and hugepages must be setup prior to running an application.
The application is linked with the Intel® DPDK target environment's Environmental Abstraction Layer (EAL) library, which provides some options that are generic to every Intel® DPDK application. The following is the list of options that can be given to the EAL:
./rte-app -c COREMASK -n NUM [-b ] [--socket-mem=MB,...]
[-m MB] [-r NUM] [-v] [--file-prefix] [--proc-type ]
The EAL options are as follows:
• -c COREMASK: An hexadecimal bitmask of the cores to run on
• -n NUM: Number of memory channels
• -b : blacklisting of ports; prevent EAL from using
specified PCI device (multiple -b options are allowed)
• --socket-mem: Memory to allocate on specific sockets
• -m MB: Memory to allocate
• -r NUM: Number of memory ranks
• -v: Display version information on startup
• --huge-dir: The directory where hugetlbfs is mounted
• --file-prefix: The prefix text used for hugepage filenames
• --proc-type: The type of process instance
The -c and the -n options are mandatory; the others are optional.
Copy the Intel® DPDK application binary to your target, then run the application as follows:
user@target:~$ ./helloworld -c f -n 4
Note: The --proc-type and --file-prefix EAL options are used for running multiple Intel® DPDK processes.
上面的helloworld程序如何运行在多个cpu上呢?下面是helloworld的main函数:
int MAIN(int argc, char **argv)
{
int ret;
unsigned lcore_id;
ret = rte_eal_init(argc, argv); //解析rte_eal程序传入的相关参数,比如运行的cpu,内存等
if (ret < 0)
rte_panic("Cannot init EAL\n");
//这里的slave core由rte_eal程序的-p参数决定的
RTE_LCORE_FOREACH_SLAVE(lcore_id) {
rte_eal_remote_launch(lcore_hello, NULL, lcore_id);
}
lcore_hello(NULL);
rte_eal_mp_wait_lcore();
return 0;
}
-
DPDK如何管理报文及对jumbo frame的支持
由于DPDK支持巨型帧,没有采用linux的skb管理方式,而是采用BSD的mbuf(但是没有找到足够的理由说采用mbuf要比skb的方式优越在哪里)。
下面是EAL的mbuf管理结构:
struct rte_mbuf {
struct rte_mempool *pool;
void *buf_addr;
phys_addr_t buf_physaddr;
uint16_t buf_len;
#ifdef RTE_MBUF_SCATTER_GATHER
union {
rte_atomic16_t refcnt_atomic;
uint16_t refcnt;
};
#else
uint16_t refcnt_reserved;
#endif
uint8_t type;
uint8_t reserved;
uint16_t ol_flags;
union {
struct rte_ctrlmbuf ctrl; //控制消息mbuf结构
struct rte_pktmbuf pkt; //数据报文mbuf结构
};
} __rte_cache_aligned;
struct rte_pktmbuf {
struct rte_mbuf *next;
void* data;
uint16_t data_len;
uint8_t nb_segs;
uint8_t in_port;
uint32_t pkt_len;
union rte_vlan_macip vlan_macip;
union {
uint32_t rss;
struct {
uint16_t hash;
uint16_t id;
} fdir;
} hash;
};从上面的描述报文的mbuf结构来看,要比skb简单得做。Mbuf要支持jumbo frame,从代码上来看,似乎对管理报文的机构并没有特殊的要求(这也是skb可以支持jumbo frame的理由),但是对内存分配,包括mbuf结构和data的内存分配提出要求,所以要求linux必须支持huge page。对huge page的管理主要体现在mem的管理上。
-
DPDK的应用程序之间如何通信
在RMI的系列芯片中,有一个非常关键的设计,那就是FMN(Fast Message Network),所有芯片内部的器件包括IO、CPU、Mem都挂在FMN上,他们之间通信是通过所谓的FMN消息来通信,FMN是一个环状结构,实际上就是一个通信消息的Buffer ring。
Buffer ring在linux里面已经支持,2.6.28内核已经支持,后来又改进,支持了lockless buffer ring的设计。
在DPDK里面提供一个buffer ring的库,即rte_ring库,至于运行在EAL上的"应用程序"、"接口驱动"等之间如何通信,可以使用rte_ring库提供的接口去设计和实现。
Ring Buffer也叫Circular Buffer,是一种缓冲区数据结构,一般用于生产者-消费者模式的程序中,一个或多个生产者不停产生数据,同时一个或多个消费者使用数据,数据使用完这块缓冲区就可以释放了。
在通信程序中,经常使用环形缓冲区作为数据结构来存放通信中发送和接收的数据。环形缓冲区是一个先进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
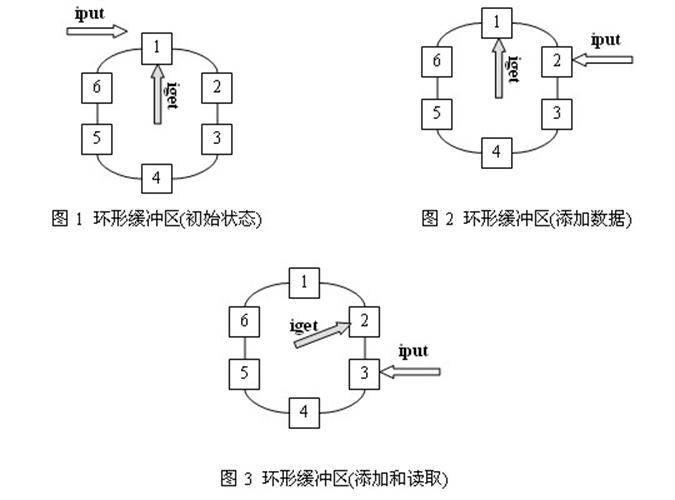
环形缓冲区的实现原理
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的缓冲区。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。在通常情况下,环形缓冲区的读用户仅仅会影响读指针,而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,那么不需要添加互斥保护机制就可以保证数据的正确性。如果有多个读写用户访问环形缓冲区,那么必须添加互斥保护机制来确保多个用户互斥访问环形缓冲区。
图1、图2和图3是一个环形缓冲区的运行示意图。图1是环形缓冲区的初始状态,可以看到读指针和写指针都指向第一个缓冲区处;图2是向环形缓冲区中添加了一个数据后的情况,可以看到写指针已经移动到数据块2的位置,而读指针没有移动;图3是环形缓冲区进行了读取和添加后的状态,可以看到环形缓冲区中已经添加了两个数据,已经读取了一个数据。
-
DPDK提供的几种应用程序运行模式
从DPDK提供的框架来看,一个应用程序可以通过参数设定运行在哪些core上,多个应用程序同时可以运行在同一个DPDK环境下。
多个应用程序,
-
可以是相同的应用程序(即完成相同的事务,比如处理数据报文),也可以是不同的应用程序;
-
应用程序之间可以通信,也可以不通信;它们之间通信采用共享内存和队列
-
多个应用程序之间可以是主从关系,也可以是并行关系
-
多个应用程序可以运行在相同的多个core上,也可以在不同的多个core上,比如一个应用程序运行在0和1号core上,第二个应用程序运行在0和1号,第三个应用程序运行在1和3号core上
-
DPDK如何支持multi-chips的
DPDK支持multi-cores基本的框架和思路与V5目前基本上是一致的,但是DPDK还支持多芯片NUMA的模式,又是如何做到的呢?
首先需要搞清楚几个概念:
CMP、SMP、NUMA、MPP
SMP=CPUs+总线+Mems,CPU之间以同等地位访问共享内存
NUMA=Node+总线+Node,Node=CPUs+总线+Mems
MPP=NUMA或SMP+IO网络+NUMA或SMP
所以NUMA各个node之间除了能够访问本地内存外,还可以访问其他node的远程内存
MPP类似于当前的机框交换机,各个单板之间实际就是MPP的方式,只能访问本地内存,各个节点之间无法访问内存
从NUMA的架构来看,似乎CPU在访问内存的时候是有优先级的,先访问本地内存,再访问远程内存,但是从DPDK的内存管理来看,似乎在系统初始化的时候将所有节点的内存按照节点统一管理,按照NUMA的思路,在内存分配的时候,应该是先从Node本地内存分配,如果本地内存不足,再从其他Node上的内存分配,或者显式地指定从其他Node的内存分配,代码实现分析:
void *rte_malloc(const char *type, size_t size, unsigned align)
{
return rte_malloc_socket(type, size, align, SOCKET_ID_ANY);
}
void *
rte_malloc_socket(const char *type, size_t size, unsigned align, int socket)
{
…
if (socket == SOCKET_ID_ANY) //socket id就是node id
socket = malloc_get_numa_socket();
…
return malloc_heap_alloc(&mcfg->malloc_heaps[socket], type,
size, align == 0 ? 1 : align);
}
void *malloc_heap_alloc(struct malloc_heap *heap,
const char *type __attribute__((unused)), size_t size, unsigned align)
{
…
if (elem == NULL){//如果没有内存,则添加,关键是看如何添加的
if ((malloc_heap_add_memzone(heap, size, align)) == 0)
elem = find_suitable_element(heap, size, align, &prev);
}
…
}
malloc_heap_add_memzone()-àrte_memzone_reserve()àrte_memzone_reserve_aligned()àmemzone_reserve_aligned_thread_unsafe()
static const struct rte_memzone *
memzone_reserve_aligned_thread_unsafe(const char *name, uint64_t len,
int socket_id, unsigned flags, unsigned align)
{
…
for (i = 0; i < RTE_MAX_MEMSEG; i++) {
…
if (socket_id != SOCKET_ID_ANY &&
socket_id != free_memseg[i].socket_id)//如果不允许从其他socket上远程分配内存,则
continue;
}
…
struct rte_memzone *mz = &mcfg->memzone[mcfg->memzone_idx++];
rte_snprintf(mz->name, sizeof(mz->name), "%s", name);
mz->phys_addr = memseg_physaddr;
mz->addr = memseg_addr;
mz->len = requested_len;
mz->hugepage_sz = free_memseg[memseg_idx].hugepage_sz;
mz->socket_id = free_memseg[memseg_idx].socket_id;//可以看到socket id可能不是本地的了
}
}
-
如何用DPDK开发数据通信产品
数据通信产品的核心有两点:
-
设备的管理
-
数据报文的高效处理
按照类NP的软件框架,一般数据通信开发平台分为控制平面和数据平面,控制平面负责整个系统的配置和管理,数据平面专门处理业务报文。那么在DPDK上如何设计呢?
控制平面可以认为是一个应用程序,数据平面由多个应用程序组成。
数据平面至少有下面几个应用程序:
-
报文接收与发送应用程序,用于从网口接收报文,将报文通过网口发送出去
-
报文分发应用程序,用于将从网口收上来的报文按照一定的策略分发到数据处理应用程序(这个不是必须的,如果在初始化的时候已经确定哪些应用程序从网口的哪些队列中接收和发送报文,则这个工作则没有必要)
-
数据处理应用程序,用于处理接收上来的报文。
数据处理应用程序可以运行在多个core上,同时还可以以对称方式运行多个数据应用程序。可以想见,这样做的复杂度很高,同一个数据处理应用程序需要解决多个core的资源竞争问题,还需要考虑多个数据应用程序之间的资源竞争,同一个报文上来后,先是报文分发应用程序将报文分发给某个数据应用程序,数据应用程序接收到这个报文后还需要将此报文分发给某个具体的core去处理,涉及两次分发策略,显然这种处理比较复杂,那么简单的处理方式是什么呢?一个数据处理应用程序只是绑定运行在一个core上面,有多少个core处理报文,则运行多少个数据处理应用程序,这样则相对比较简单。
下面是一个简单的模型:
The second example of Intel® DPDK multi-process support demonstrates how a set of processes can run in parallel, with each process performing the same set of packet-processing operations. (Since each process is identical in functionality to the others, we refer to this as symmetric multi-processing, to differentiate it from asymmetric multi-processing - such as a client-server mode of operation seen in the next example, where different processes perform different tasks, yet co-operate to form a packet-processing system.) The following diagram shows the data-flow through the application, using two processes.

For example, to run a set of four symmetric_mp instances, running on lcores 1-4, all performing level-2 forwarding of packets between ports 0 and 1, the following commands can be used (assuming run as root):
# ./build/symmetric_mp -c 2 -n 4 --proc-type=auto -- -p 3 --num-procs=4 --proc-id=0
# ./build/symmetric_mp -c 4 -n 4 --proc-type=auto -- -p 3 --num-procs=4 --proc-id=1
# ./build/symmetric_mp -c 8 -n 4 --proc-type=auto -- -p 3 --num-procs=4 --proc-id=2
# ./build/symmetric_mp -c 10 -n 4 --proc-type=auto -- -p 3 --num-procs=4 --proc-id=3
For the symmetric multi-process example, since all processes work in the same manner, once the hugepage shared memory and the network ports are initialized, it is not necessary to restart all processes if the primary instance dies. Instead, that process can be restarted as a secondary, by explicitly setting the proc-type to secondary on the command line. (All subsequent instances launched will also need this explicitly specified, as auto-detection will detect no primary processes running and therefore attempt to re-initialize shared memory.)
下面是从代码框架上看上面的模型是如何实现的:
Int main(int argc, char **argv)
{
…
signal(SIGINT, print_stats);
signal(SIGTERM, print_stats);
ret = rte_eal_init(argc, argv);
…
proc_type = rte_eal_process_type();
if (rte_pmd_init_all() < 0)
rte_exit(EXIT_FAILURE, "Cannot init pmd\n");
if (rte_eal_pci_probe() < 0)
rte_exit(EXIT_FAILURE, "Cannot probe PCI\n");
if (rte_eth_dev_count() == 0)
rte_exit(EXIT_FAILURE, "No Ethernet ports - bye\n");
smp_parse_args(argc, argv);
mp = (proc_type == RTE_PROC_SECONDARY) ?
rte_mempool_lookup(_SMP_MBUF_POOL) :
rte_mempool_create(_SMP_MBUF_POOL, NB_MBUFS, MBUF_SIZE,
MBUF_CACHE_SIZE, sizeof(struct rte_pktmbuf_pool_private),
rte_pktmbuf_pool_init, NULL,
rte_pktmbuf_init, NULL,
SOCKET0, 0);
…
for(i = 0; i < num_ports; i++){
if(proc_type == RTE_PROC_PRIMARY)
if (smp_port_init(ports[i], mp, (uint16_t)num_procs) < 0)
rte_exit(EXIT_FAILURE, "Error initialising ports\n");
}
if (proc_type == RTE_PROC_PRIMARY)
check_all_ports_link_status((uint8_t)num_ports, (~0x0));
assign_ports_to_cores();
…
rte_eal_mp_remote_launch(lcore_main, NULL, CALL_MASTER);
return 0;
}
static int lcore_main(void *arg __rte_unused)
{
…
for (;;) {
struct rte_mbuf *buf[PKT_BURST];
for (p = start_port; p < end_port; p++) {
const uint8_t src = ports[p];
const uint8_t dst = ports[p ^ 1];
const uint16_t rx_c = rte_eth_rx_burst(src, q_id, buf, PKT_BURST);
if (rx_c == 0)
continue;
pstats[src].rx += rx_c;
const uint16_t tx_c = rte_eth_tx_burst(dst, q_id, buf, rx_c);
pstats[dst].tx += tx_c;
if (tx_c != rx_c) {
pstats[dst].drop += (rx_c - tx_c);
for (i = tx_c; i < rx_c; i++)
rte_pktmbuf_free(buf[i]);
}
}
}
}注意:从前面的分析来看,应用程序有两种运行方式,一种是一个数据处理应用程序运行在多个core上面,另外一种是一个core上绑定运行一个数据应用程序(都相同),那么到底采用哪种方式呢?第二种在系统鲁棒性方面应该比较第一种好,因为即使运行在某个core上应用程序异常了,可以重新启动这个应用程序,只要共享内存没有破坏,是不会影响其他core上的应用程序继续运行的。但是这只是一种理想状况,对于安全设备来说,会话表要想设计成每个数据应用程序独享的方式不是不可以,那么则意味着有两个一个前提条件:流量必须按照5元组分流到各个数据应用程序上面去。则数据分发应用程序是必不可少的。
-
案例分析—6wind
6wind提供的系统分为两套系统,一套是在Intel的DPDK还未出来之前设计的一套系统,另外一套是在Intel的DPDK基础上将之前开发的系统。但是核心的数据平面部分基本是一样的思路。
下面分析6wind在数据平面的解决方案,并同当前ISOS V5框架做对比分析。
-
网络设备框架
目前流行的网络设备开发平台框架如下:
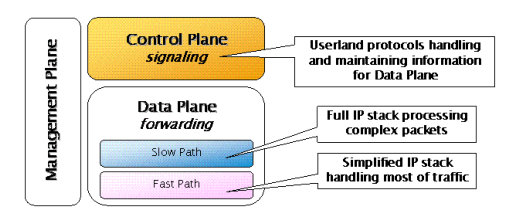
V5平台基本上也是这样的框架,暂时称之为"类NP"框架,实际上是NP推动了这个软件框架走向合理化和成熟化。
6wind基于这样的理念,提出了下面三种框架:
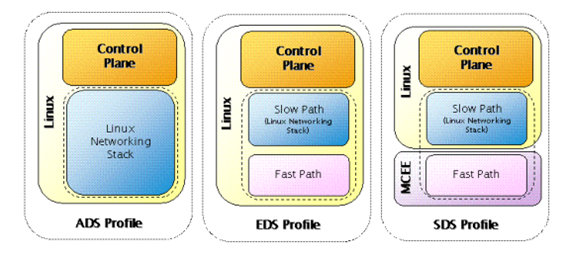
V5有点类似于SDS模式,但是又与之不同,V5的Slow Path有两个,一个是在数据平面,一个是在控制平面(linux)内核的协议栈。从下图可以看出6wind的Fast Path与Slow Path之间交换都是通过共享内存(在其他地方也提到其他接口,比如FPN、FPS、FPC API,但是估计本质上仍然是共享内存)的方式:
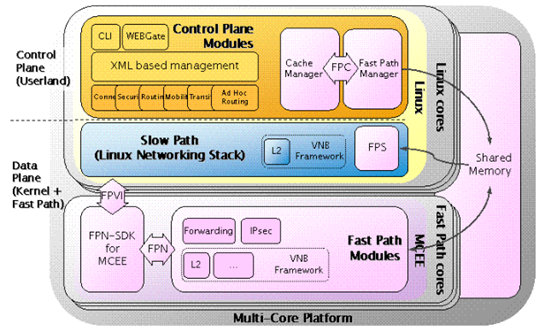
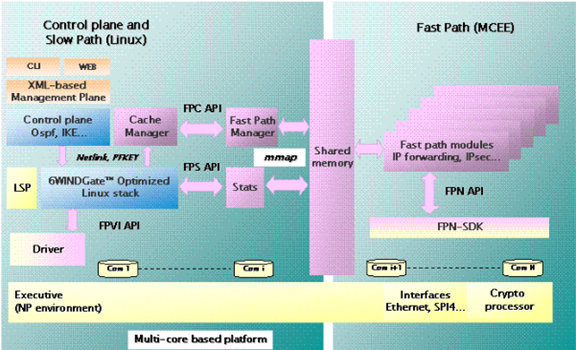
V5系统,数据平面与控制平面linux之间通信,大部分是消息通信,有小部分是共享内存(低256M:全局变量、共享内存)。
如果纯粹采用共享内存,对于分布式机框设备的适应能力需要做很多的工作,下面是6wind提出的机框分布式的解决方案:
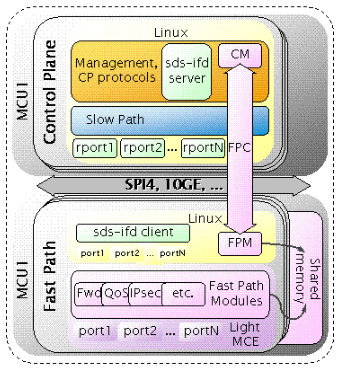
上面的解决方案存在什么问题?主控板与业务板之间通信都是通过控制平面Linux来进行,那么业务板上,控制平面linux又通过共享内存方式与数据平面的FastPath通信,效率上会比较大的折扣,为什么不能通过网口直接与数据平面通信呢?包括报文。
-
VIRTUAL FAST PATH
6wind提供所谓的虚拟FastPath,估计这个框架才是基于Intel DPDK,将之前内核部分的Fast Path移植到DPDK上(在用户态以应用程序的方式运行)。
-
VNB
6wind在资料中反复提到VNB(Virtual Network Blocks),似乎主要作用是以插件方式集成到Linux的协议栈或FastPath中去,主要进行的工作:
•Protocol encapsulation
•Feature performance optimization by separation of Kernel/Fast Path packet processing from Control Plane
•Assembly of several protocols in order to provide global solutions
•Driver integration
-
管理框架
6wind的管理框架可能是系统的最大亮点(其他不敢苟同)。
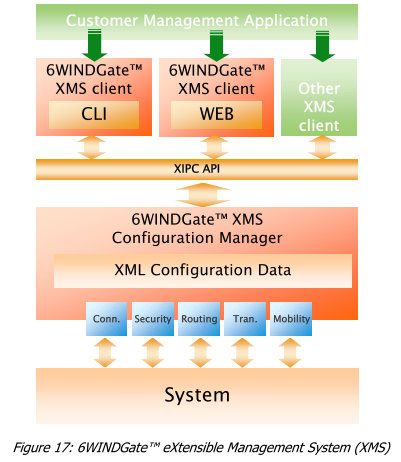
-
总结
通过DPDK和6wind的解决方案分析,可以得到下面的一些结论:
-
DPDK提供了一个很好的开发平台,解决了基础的框架结构、内存管理、进程通信、接口管理、资源竞争等关键要素
-
基于DPDK的数据报文处理,比如Slow Path和Fast Path需要各厂商结合业务情况做开发,但是据说商业版的DPDK提供了完善的数据报文处理
-
DPDK并非Intel首创,实际上在前期NP、Multicore的实践经验的提出了框架,而且从前面分析看出DPDK的框架没有超出当年RMI、Cavium提出的解决框架,RMI提出的数据平面是在内核空间实现,Cavium的框架是在用户空间实现,由于Intel受到一些厂商用Cavium芯片较多的影响,采用了用户空间的解决方案。目前看来用户空间的解决方案在可调试性、可移植性方面要比内核空间的解决方案好得多
-
6wind的多核解决方案,在模块化方面考虑较多,但估计性能方面会受到比较大的影响,据测试6wind提供的解决方案相对于其他厂商,新建能力差得很多,基本上是3000和3万的差距,但不得不认可6wind的灵活模块化解决方案
-
附录
-
本子系统用到的缩写词、定义和术语
-
DPDK:Data Plane Development Kit
NUMA:Non-Uniform Memory Access
-
参考资料
-
软件包 IntelDPDK.L.1.3.1_7
-
《intel-dpdk-getting-started-guide.pdf》
-
《intel-dpdk-programmers-guide.pdf》
-
《intel-dpdk-sample-applications-user-guide.pdf》
-
《6Wind Architecture Overview.pdf》
-
Intel官方网站

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









