







Cache和内存技术
1. Cache一致性
多核处理器同时访问同一段cacheline时,会出现写回冲突的情况,操作系统解决这个问题会消耗一部分性能,DPDK采用了两个技术来解决这个问题:
- 对于共享的数据,每个核都定义自己的备份lcore[RTE_MAX_LCORE],这样多核处理事务时只处理自己的部分,lcore[idx]
- 利用单网卡有着多队列的能力,当多核处理同一个网卡的数据包时,进行分队列处理,例如核1使用队列1、2,核2使用队列3,4
2. 巨页技术
内存管理单元(MMU)完成从虚拟内存地址到物理内存地址的转换。内存管理单元进行地址转换需要的信息保存在一个叫页表(Page Table)的数据结构里面,页表查找是一种极其耗时的操作。DPDK则利用巨页技术,首先页表增大到1GB,这样会大大减少cache miss,其次所有的内存都是从巨页里分配,实现对内存池(Mempool)的管理,并预先分配好同样大小的mbuf,供每一个数据分组使用。
3. DDIO
传统方式,当一个网络报文送到服务器的网卡时,网卡通过外部总线(比如PCI总线)把数据和报文描述符送到内存。接着,CPU从内存读取数据到Cache进而到寄存器。进行处理之后,再写回到Cache,并最终送到内存中
DPDK使用了DDIO技术使外部网卡和CPU通过LLC Cache直接交换数据,绕过了内存这个相对慢速的部件。
4. NUMA
NUMA是起源于AMD Opteron的微架构,同时被英特尔Nehalem架构采用。在这个架构中,处理器和本地内存之间拥有更小的延迟和更大的带宽,而整个内存仍然可作为一个整体,任何处理器都能够访问,只不过跨处理器的内存访问的速度相对较慢一点。
DPDK做了一些优化以适应NUMA系统,使其运行速度更快:
- per-core memory,每个核都有属于自己的内存,即对于经常访问的数据结构,每个核都有自己的备份
- 如果有一个PCI设备在node0上,就用node0上的核来处理该设备,处理该设备用到的数据结构和数据缓冲区都从node0上分配,即本地设备本地处理
无锁环形队列
环形队列一般符合生产者-消费者模型,用于报文收发的缓存区或者是线程收发消息的队列,DPDK提供了一种无锁的环形队列,大家知道加锁操作十分耗费性能,下图是横向多种锁机制的比较,其中第一个是无锁:

DPDK的无锁环形队列的优缺点:

DPDK无锁队列的实现方法,我以单生产者-单消费者进行举例:
单生产入队总共分三步:
- 生产者通过Cas原子锁将ring队列中的prod_head复制到自己的线程变量中,然后将prod_next置为pro_head的下一个位置。
- 接着将obj4对象拷贝到prod_head指向的地方,然后用线程变量的prod_next去更新ring状态的prod_head。
- 最后修改ring状态的prod_tail指向prod_head。


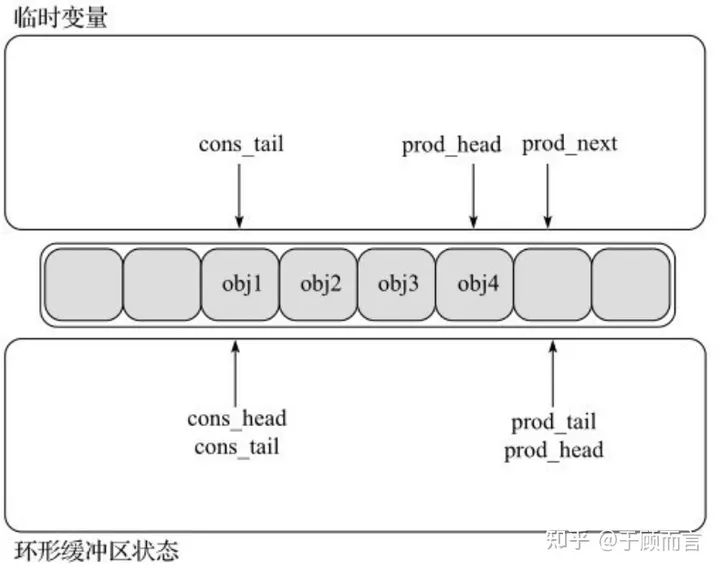
单消费者入场消费总共分三步,和生产者类似不赘述了:



多线程绑核技术
DPDK的线程基于pthread接口创建,属于抢占式线程模型,受内核调度支配。DPDK通过在多核设备上创建多个线程,每个线程绑定到单独的核上,减少线程调度的开销,以提高性能。DPDK的线程可以作为控制线程,也可以作为数据线程。在DPDK的一些示例中,控制线程一般绑定到MASTER核上,接受用户配置,并传递配置参数给数据线程等;数据线程分布在不同核上处理数据包
其次DPDK充分利用指令的并发,比如说rte_memcpy,虽然功能只是简单的内存拷贝功能,但是它的实现使用了平台所支持的最大宽度的Load和Store指令(Sandy Bridge为128bit, Haswell为256bit)。此外,由于非对齐的存取操作往往需要花费更多的时钟周期,rte_memcpy优先保证Store指令存储的地址对齐,利用处理器每个时钟周期可以执行两条Load这个超标量特性来弥补一部分非对齐Load所带来的性能损失


网卡性能优化技术
DPDK采用了轮询或者轮询混杂中断的模式来进行收包和发包,此前传统的方法都是系统内核态的网卡驱动程序基于异步中断处理模式,我们都知道中断是十分耗性能的。
DPDK纯轮询模式是指收发包完全不使用中断处理的高吞吐率的方式。DPDK所有的收发包有关的中断在物理端口初始化的时候都会关闭,具体轮询步骤如下:
- DPDK的轮询驱动程序负责初始化好每一个收包描述符,其中就包含把包缓冲内存块的物理地址填充到收包描述符对应的位置,以及把对应的收包成功标志复位
- 驱动程序修改相应的队列管理寄存器来通知网卡硬件队列里面的哪些位置的描述符是可以有硬件把收到的包填充进来的
- 网卡硬件会把收到的包一一填充到对应的收包描述符表示的缓冲内存块里面,同时把必要的信息填充到收包描述符里面,其中最重要的就是标记好收包成功标志
- DPDK都会有一个对应的软件线程负责轮询里面的收包描述符的收包成功的标志。一旦发现某一个收包描述符的收包成功标志被硬件置位了,就意味着有一个包已经进入到网卡,这时候驱动程序会解析相应的收包描述符,提取各种有用的信息
硬件卸载技术
硬件的能力提升迅速,在一块小小的网卡上,处理器能够提供的性能已经远远超出了简单的数据包接收转发的需求,这在技术上提供了将许多原先软件实现的功能下移由网卡硬件直接完成的可能。
DPDK支持的网卡种类已经非常多,以下是dpdk的软件接口:

















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











