







一、引言

在当今数字化浪潮中,数据呈爆炸式增长,如何高效地搜索、分析这些海量数据,已成为企业和开发者面临的关键挑战。ElasticSearch 作为一款强大的开源分布式搜索与分析引擎,宛如一把瑞士军刀,为各类应用场景提供了全方位、高性能的解决方案。
无论是电商巨头应对每秒数以万计的商品搜索请求,精准地向用户推荐心仪好物;还是互联网企业借助它实时剖析海量日志,迅速排查系统故障;亦或是社交媒体平台利用其强大功能,为用户提供个性化的内容推送,ElasticSearch 都展现出了无与伦比的优势。它凭借分布式架构,轻松处理大规模数据,实现快速索引与查询;其丰富的查询语法和强大的聚合功能,满足了从简单关键词搜索到复杂数据分析的多样需求。接下来,就让我们一同深入探索 ElasticSearch 的实战应用,解锁它在不同领域的无限潜力,开启高效数据处理的新篇章。
二、ElasticSearch 核心概念剖析
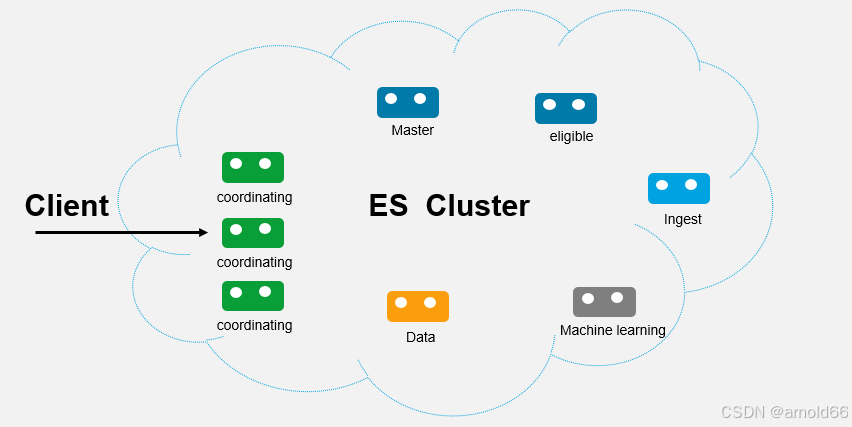
2.1 分布式架构
ElasticSearch 的分布式架构宛如一座精密构建的摩天大厦,奠定了其高效处理海量数据的基石。在这个架构体系中,集群是核心的组织形式,由多个节点协同作战,这些节点既可以是物理机,也能是虚拟机。每个节点各司其职,其中数据节点如同大厦的储物间,承担着数据的存储与检索重任;主节点则像是大厦的管理员,掌控着集群的状态、元数据,以及节点的加入与离开等关键事务。
而分片机制更是精妙绝伦,它将索引如同一本厚重的百科全书般拆分成一个个独立的 “小册子”—— 分片,这些分片能够分散存储在不同的数据节点上。比如,面对一个拥有数十亿条数据的电商商品索引,通过合理分片,可将其分割为数百个分片,均匀分布于集群各节点。查询时,多个节点便能并行发力,宛如多条并行的高速公路,让查询请求风驰电掣般得到处理,极大提升检索效率。同时,副本机制为数据安全保驾护航,每个分片都可有若干副本,如同为珍贵书籍制作备份,一旦某个节点 “罢工”,副本立刻顶上,确保数据持续可用,服务永不中断。 这种分布式架构使得 ElasticSearch 能够轻松突破单机性能瓶颈,随着数据量增长与查询负载攀升,只需从容添加新节点,即可实现无缝扩展,持续提供稳定且高效的搜索与分析服务。
2.2 索引、文档与字段
索引、文档与字段构成了 ElasticSearch 数据世界的基本骨架,它们紧密相连,又各自承担独特使命。索引宛如一座庞大的图书馆,是数据的汇聚之地,用于收纳具有相似特征或用途的文档集合,类比关系型数据库,它恰似其中的 “数据库” 概念。
文档则是图书馆中的一本本 “书籍”,作为存储在 ElasticSearch 中的基本数据单元,以 JSON 格式精心封装着各类信息,它承载着用户对数据操作的最细粒度内容,如同数据库里的一条记录。例如,在一个新闻资讯平台的索引下,每一篇新闻稿件就是一个独立文档,涵盖标题、作者、正文、发布时间等关键信息。
而字段就像是书中的章节段落,文档由一个或多个字段有机组合而成,每个字段都有其特定的数据类型,如文本型、数值型、日期型等。不同类型的字段为搜索与分析提供了多样化的 “入口”,文本型字段支持丰富的分词搜索,可依据关键词精准定位相关文档;日期型字段便于按时间维度筛选信息,迅速捞出特定时段内的数据。三者相辅相成,通过合理定义索引结构、精心组织文档内容与精准设置字段属性,就能为高效的数据检索与深度分析铺就坚实道路。
2.3 分词器原理
分词器在 ElasticSearch 的文本处理流程中扮演着 “语言魔法师” 的关键角色,是实现精准搜索的核心枢纽。当文本数据涌入 ElasticSearch 时,分词器就如同一位技艺高超的裁缝,按照既定规则将文本裁剪成一个个有意义的词条,这些词条便是后续构建倒排索引与搜索匹配的基石。
以 IK 分词器为例,它是中文搜索场景下的得力助手,内置了智能与细粒度两种强大模式。智能模式下,IK 分词器宛如一位聪慧的学者,会依据内在复杂算法,从众多可能的分词路径中择出最合理的结果,巧妙消除歧义。例如面对 “苹果手机很受欢迎” 这句话,它能精准拆分为 “苹果手机”“很”“受欢迎”,而非简单粗暴地割裂词汇,确保搜索 “苹果手机” 时能直击目标文档。
细粒度模式则像一位严谨的考古学家,不遗漏任何细微线索,将文本拆解至最细,包含所有潜在的切分可能,为一些需要深度挖掘文本关联的场景提供支持。分词器的工作流程精细而复杂,先由字符过滤器对原始文本进行 “梳妆打扮”,去除 HTML 标签、特殊字符等杂质;接着分词器闪亮登场,按预设算法切割文本;最后词项过滤器再对词条精心打磨,进行大小写转换、停用词剔除、词干提取等操作,让词条以最完美的姿态进入索引与搜索流程,为用户开启精准、高效的文本搜索之门。
三、实战场景深度解析
3.1 电商搜索应用
3.1.1 海量商品数据索引构建
在电商领域,商品数据如浩瀚星辰,构建合理索引是实现高效搜索的关键第一步。以常见的电商平台为例,商品信息涵盖标题、描述、价格、品牌、分类、库存等诸多维度。设计索引时,需审慎抉择字段,像标题、描述这类承载丰富文本信息的字段,应选用 text 类型,以便后续进行全文搜索与精准分词;而品牌、分类等字段,其值相对固定且用于精准筛选,设定为 keyword 类型更为妥当,可大幅提升过滤效率。
例如,创建 “products” 索引时,利用 Elasticsearch 的 Mapping 机制,精准定义各字段类型:
PUT /products
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"description": {
"type": "text",
"analyzer": "ik_smart"
},
"price": {
"type": "double"
},
"brand": {
"type": "keyword"
},
"category": {
"type": "keyword"
},
"stock": {
"type": "integer"
}
}
}
}在此示例中,为 “title” 与 “description” 字段指定 IK 分词器的智能模式(ik_smart),能依据中文语义合理分词,确保搜索 “华为手机” 时,精准匹配相关商品。合理的索引构建宛如为商品信息搭建起一座井然有序的图书馆,让后续搜索查询得以在这座知识宝库中快速寻得所需。
3.1.2 复杂搜索功能实现
电商搜索绝非简单的关键词匹配,用户期望的是全方位、精准且便捷的搜索体验,这就要求实现多样复杂的搜索功能。
多条件搜索方面,借助 Elasticsearch 的 bool 查询,可完美融合多个条件。比如,用户期望查找 “品牌为苹果、价格在 5000 - 8000 元之间的手机”,相应的查询语句如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











