







上一章节介绍了通用的恢复场景,本章将举例说明恢复时可能遇到的问题,并解释特殊场景的恢复问题。
目录
8.1. 指定时间点恢复和指定备份集恢复的区别 ¶
指定时间点恢复和指定备份集恢复都可以将数据库恢复到同样的某个时刻,指定时间点恢复默认使用距离恢复点最近的备份集,因此二者使用的备份集可能不同。不同的备份集内的非表文件(比如kingbase.conf或sys_hba.conf等配置文件、日志文件)就会有差异,尤其是配置文件内参数的差异就会决定数据库恢复结束后的一些行为,比如最大连接数变了,某个IP段不允许访问数据库了。
8.2. 无法恢复到最新增量数据 ¶
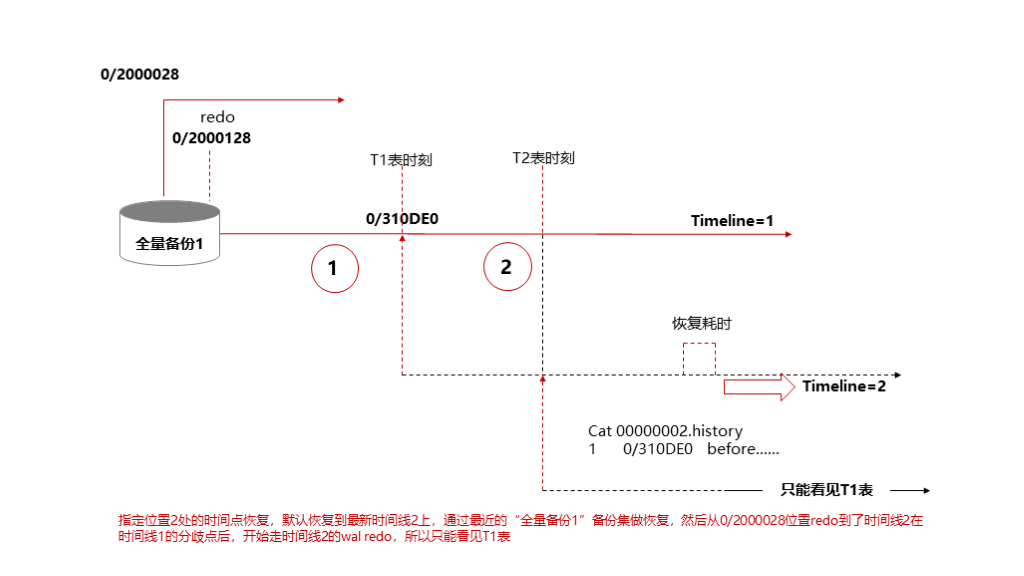
如下图所示,数据库在全量备份1之后创建了T1表, 位置1 为创建T1表之后的时刻,然后又创建了T2表, 位置2 为创建T2表之后的时刻,最后开始模拟恢复场景:
-
首先恢复到 位置1 ,并且执行了提升节点操作
-
然后又尝试恢复到 位置2 ,发现看不见T2表
原因是在步骤二恢复时,没有添加 --target-timeline 参数指定要恢复到时间线1上,因此默认恢复到了最新时间线2上,所以看不到T2表。
8.3. 恢复后启动数据库报错 ¶
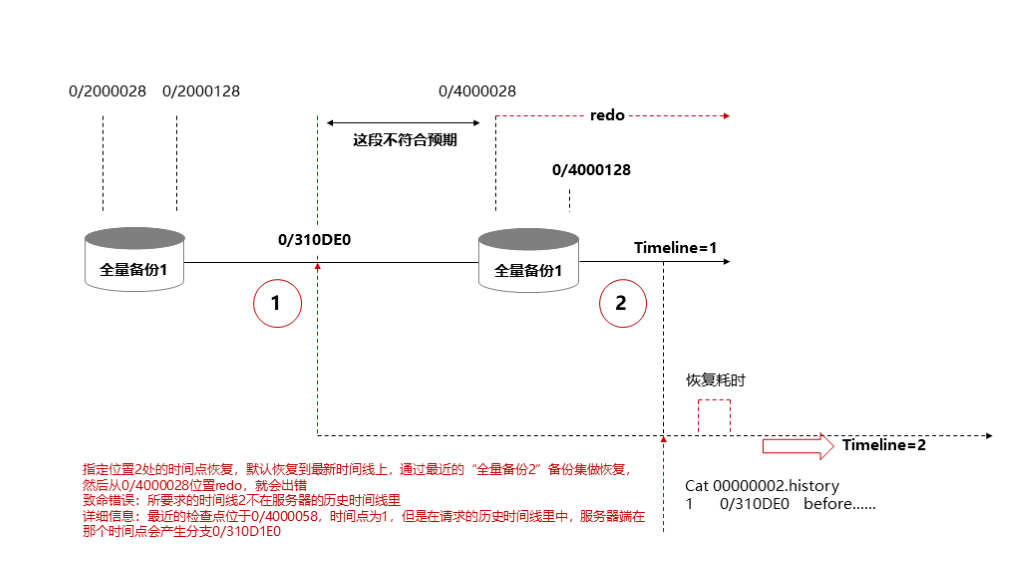
如下图所示,数据库在全量备份1之后又做了一次备份为全量备份2,然后开始模拟恢复场景:
-
首先恢复到 位置1 ,并且执行了提升节点操作
-
然后,通过时间点恢复尝试恢复到时间线1上的全量备份2之后的 位置2 ,启动数据库失败
原因是在步骤二的指定时间点恢复时没有指定时间线1,恢复过程是这样的:首先找到离 位置2 最近的备份集为 全量备份2 ,然后恢复备份集,启动数据库后开始从备份集开始的位置 0/4000028 重放WAL日志,默认又使用最新时间线2,发现时间线2在时间线1上的分歧点 0/310DE0 , 0/310DE0 到 0/4000028 这段的日志是不符合时间线2的预期的,因此数据库报错退出。
解决方式就是在步骤二指定时间点恢复时添加时间线1的设置。
8.4. 恢复后发现查询卡住 ¶
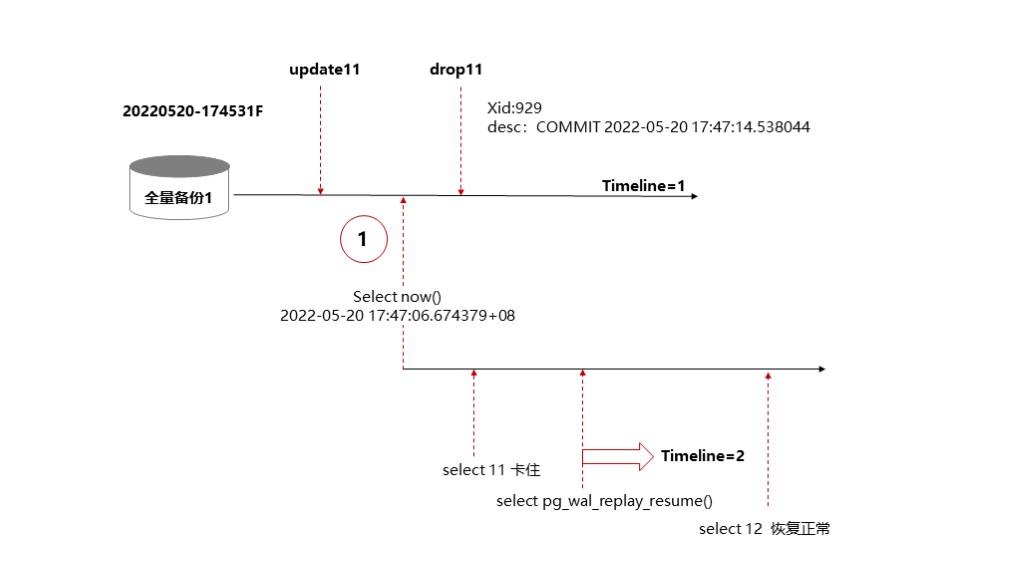
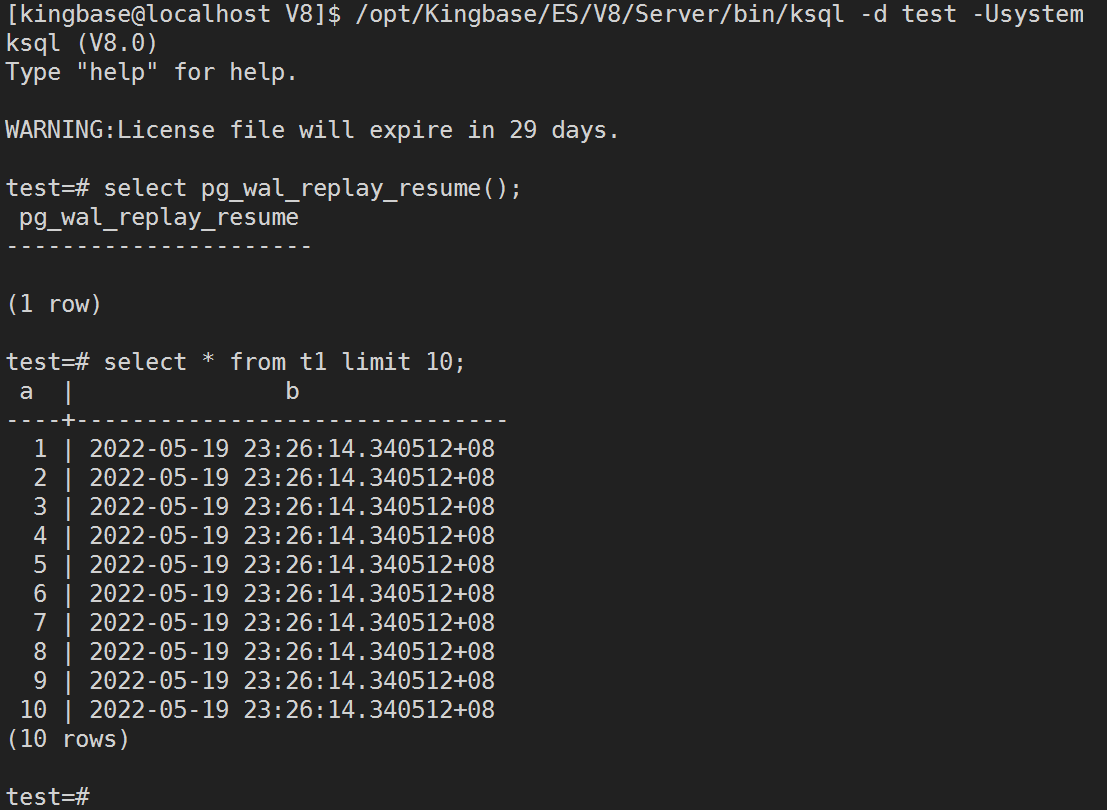
如下图所示,指定了删除表t1之前的时间点做恢复,恢复后启动数据库查询t1表数据卡住,ksql没有任何查询输出,但执行 sys_wal_replay_resume() 函数之后,就可以正常查询t1表了,数据也是正常的。
8.4.1. 原因 ¶
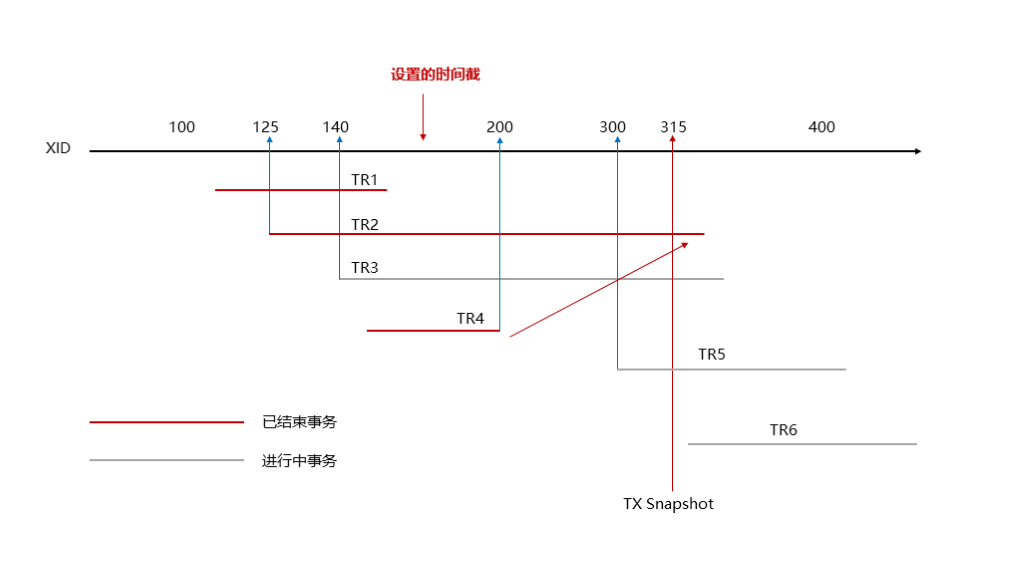
受限于KingbaseES PITR的机制,PITR选定的时间,一般都不是事务结束的时间,所以redo会继续往后走,将下一个事务的结束时间和设定的时间进行对比,如果设定时间小于,就停止了,就是目前数据库的状态:
-
这时候会有1个或多个事务处于未提交状态,这些未提交事务可能持有锁(例如drop table 持有排他锁,本示例中查询卡住就是因为拿不到t1的共享锁),此时执行
sys_wal_replay_resume()函数将这些事务回滚就可以了,对恢复无影响 -
如果刚好卡在下一条事务是 drop database这种无法回滚的DDL操作,就会出现DDL语句被直接执行(kingbase不支持事务内执行drop database的操作,无法回滚,比如下一小节提到的问题)
8.4.2. 解决方法 ¶
-
尝试更改指定时间点恢复的目标时刻,让恢复后的状态不卡在特殊SQL未提交前的状态。
-
改为指定事务ID恢复,事务ID是唯一标志,不会往下继续查时间大小,比如本示例改为xid=928。
8.4.3. 复现和定位问题步骤 ¶
首先,创建测试表t1灌入一些数据,执行全量备份,随便更新一条t1表的数据,查询当前时间为 2022-05-20 17:47:06.674379+08 ,删掉t1表。
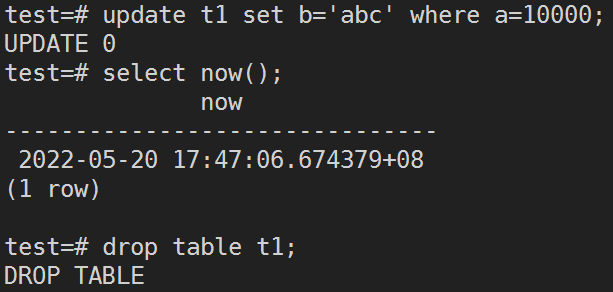

然后,停止数据库,重命名data目录,使用上一步中获得的时间执行指定时间点恢复。
/opt/Kingbase/ES/V8/Server/bin/sys_rman --config /home/kingbase/kbbr_repo/sys_rman.conf --stanza=kingbase restore --type=time --target='2022-05-20 17:47:06.674379+08'


再然后,启动数据库,查询t1表数据,发现卡住。
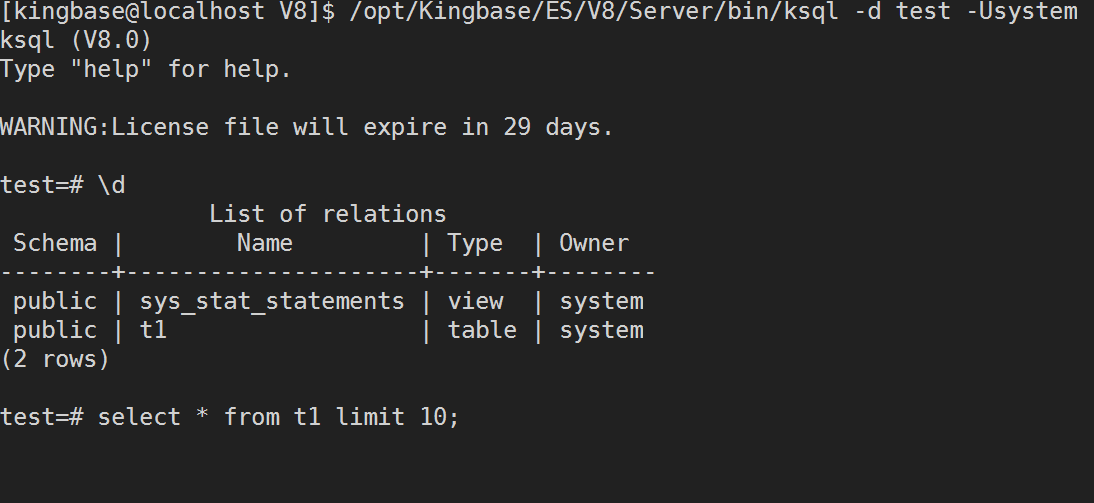
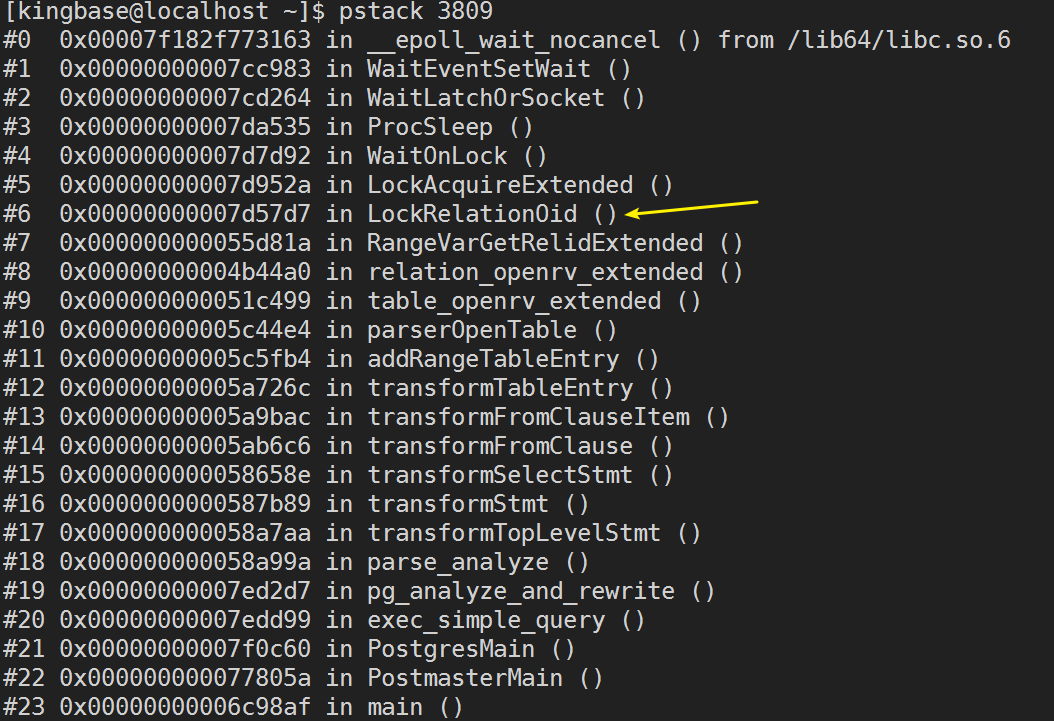
然后,获取查询语句对应的KingbaseES后台进程ID为 3809 ,使用pstack命令获取该进程的调用栈,发现是在等待锁。

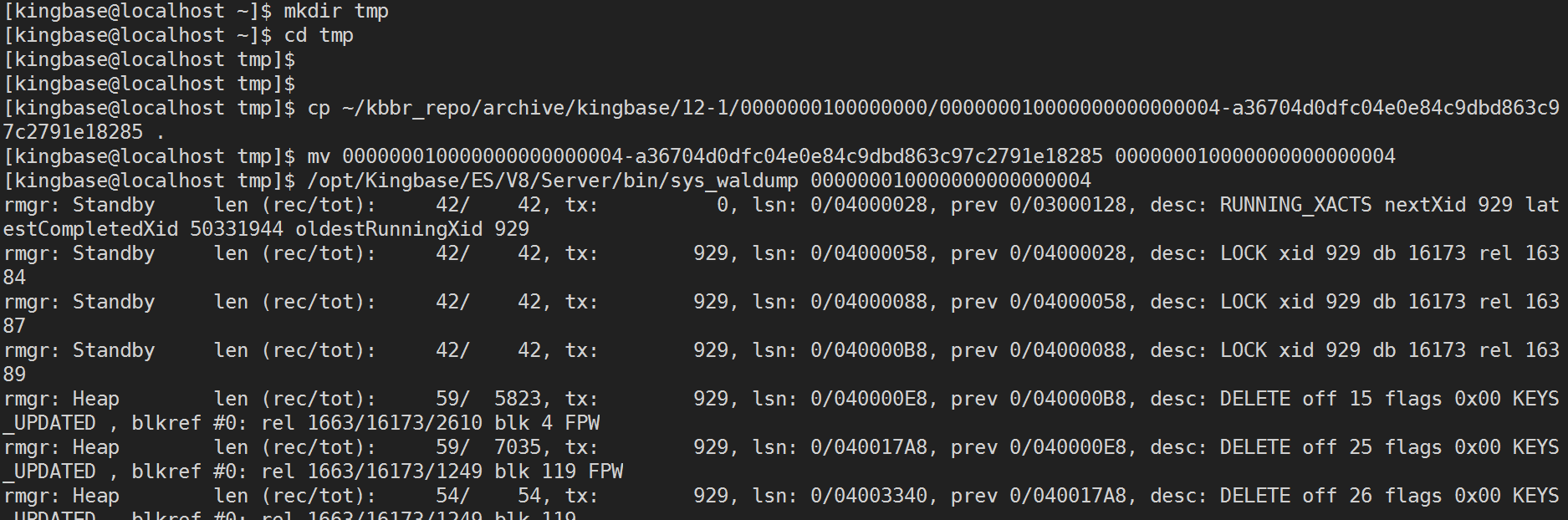
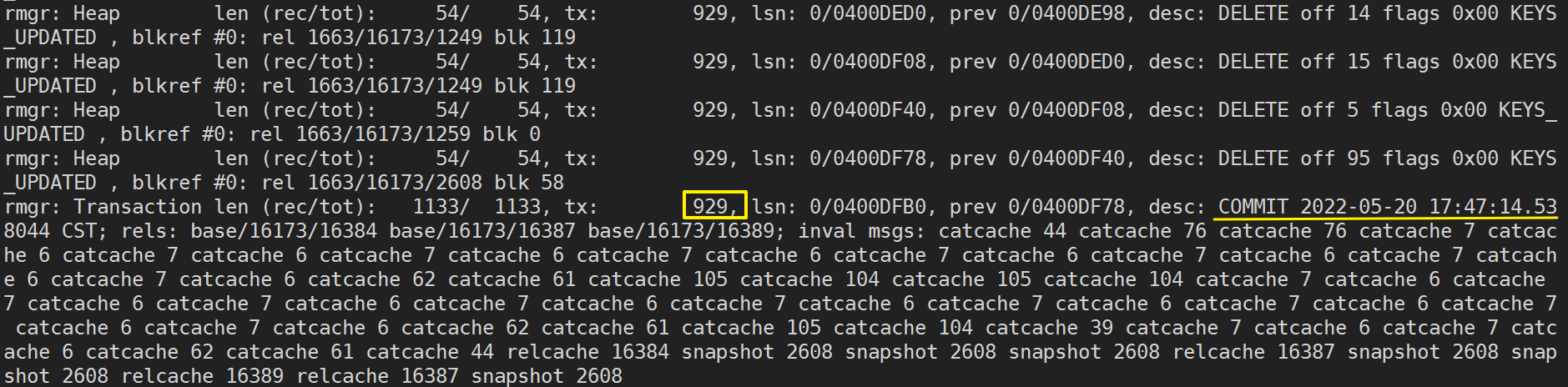
其次,查看数据库日志,发现恢复停在 929 事务(结束时间为 2022-05-20 17:47:14.538044+08 )提交之前,最后使用了 000000010000000000000004 做的恢复。
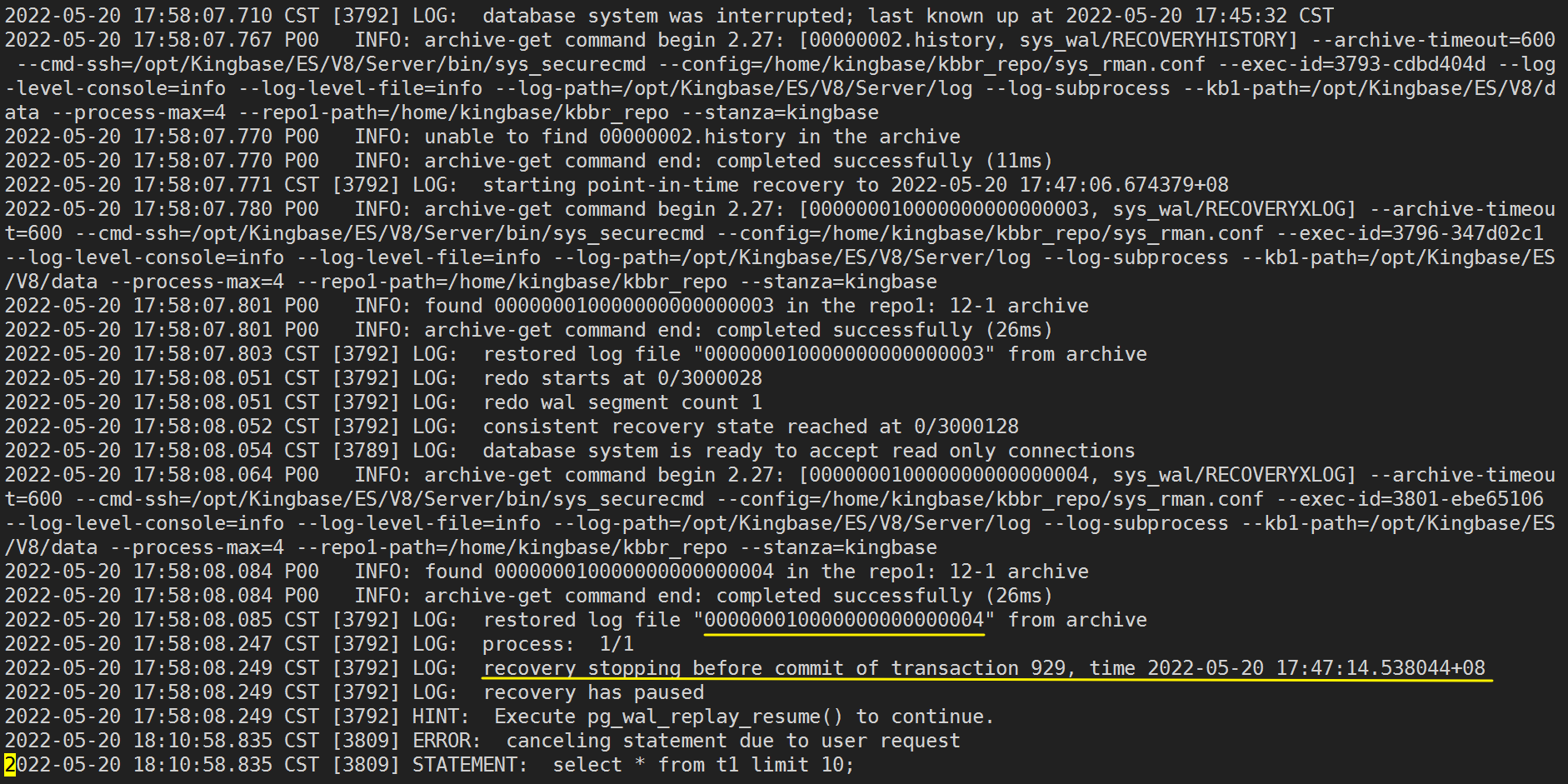
然后从sys_rman归档目录中拿到数据库恢复的最后一个wal日志文件 000000010000000000000004 ,并使用sys_waldump输出该文件记录的wal record,发现了事务ID为 929 的事务是DROP表操作(已经做了排他锁表操作,因此查表时无法拿到该表的共享锁)。
最后,执行 sys_wal_replay_resume() 函数, 929 事务回滚,排他锁释放,查询t1表正常了。
8.5. 恢复后发现database被删除 ¶
将上一节中的drop table操作改为drop database后,指定drop database操作之前的时刻做恢复,会发现该database异常,无法正常切换到该database做任何操作。因为drop database这种操作无法回滚,所以该database异常,具体复现和分析步骤不再赘述,可参考上一小节自行做验证。
8.6. 集群备库如何恢复 ¶
恢复好主库,主库启动后查询数据符合预期,执行 sys_wal_replay_resume() 提升节点,清空 kingbase.auto.conf 内的PITR参数设定,再通过 repmgr 重做备机,具体可参考《KingbaseES集群使用手册》。

















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









