







您可以查看所有文章的索引:Caffe简明教程0:文章列表
如果你已经根据前面几篇文章成功地编译了Caffe,那么现在是时候训练你的第一个模型了。我准备借用Caffe官网的LeNet例子来写这篇文章,您也可以访问原始的文档:Training LeNet on MNIST with Caffe
Caffe在编译完成之后,在caffe根目录下有个
examples文件夹,里面包含了很多Caffe的例子,其中就有MNIST。
1 准备数据
这次实验使用的是MNIST数据集,相信做计算机视觉的朋友都知道,MNIST数据集是一个由Yann LeCun及其同事整理和开放出来的手写数字图片的数据集。我们将使用Caffe来训练一个能够识别手写数字的模型。
首先我们需要下载MNIST数据集,运行caffe提供下载数据集的shell脚本:
cd $CAFFE_ROOT # $CAFFE_ROOT是你caffe的根目录
./data/mnist/get_mnist.sh # 此脚本将下载MNIST数据集运行上面的脚本之后,目录$CAFFE_ROOT/data/mnist/下将出现以下四个文件:
- train-images-idx3-ubyte(训练样本)
- train-labels-idx1-ubyte(训练样本标签)
- t10k-images-idx3-ubyte(测试样本)
- t10k-labels-idx1-ubyte(测试样本标签)
接着,我们需要把上面的数据转换为Caffe需要的数据形式(lmdb数据库形式,不了解lmdb的话可以暂时放在这里,后面的文章会详细解释),运行Caffe提供的数据转换脚本,将MNIST数据集转换为Caffe所需的lmdb文件:
./examples/mnist/create_mnist.sh # 将MNIST数据集转换为Caffe所需的lmdb文件打开目录$CAFFE_ROOT/examples/mnist你会发现多了两个文件夹:mnist_test_lmdb和mnist_train_lmdb,这两个文件夹分别保存了MNIST的以lmdb形式存储的测试集和训练集。
Trouble shooting
如果报错wget或者gnuzip没有安装,那么使用命令
sudo apt-get install wget gzip安装它们。
wget用于从远程服务器获取文件,gzip用于解压缩文件。
2 LeNet: 用于MNIST数据集的分类模型
LeNet是一个由Yann LeCun及其同事于1998年发明的手写数字识别模型,论文地址http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf。LeNet是一个并不太复杂的模型,其示意图如下 所示:
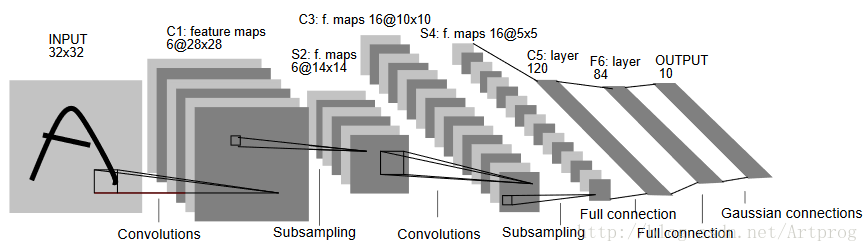
简单介绍一下LeNet的结构:
- 输入为32x32的灰度图片
- 接着是一个卷积层
- 接着是一个采样层(池化层)
- 又是一个卷积层
- 又是一个采样层(池化层)
- 最后有一个10维的softmax输出层(分别对应数字0-9)
Andrew的图可能更清晰一点:
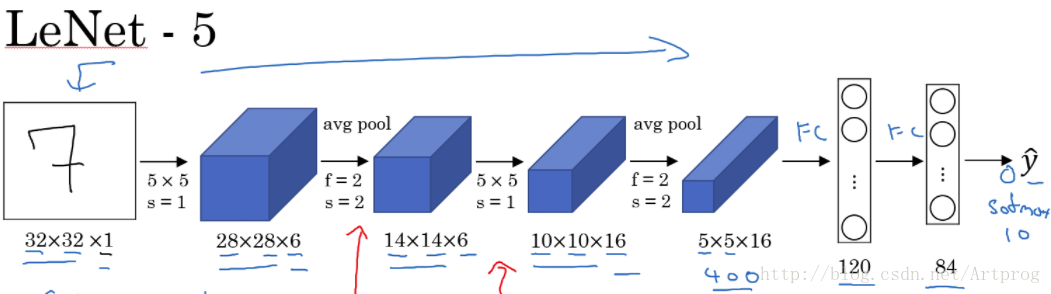
OK,了解了LeNet的结构之后,我们来看看如何在Caffe中定义这网络。
3 在Caffe中定义LeNet
在Caffe中定义一个网络的结构可能是入门者的大难题,但是,只要我们静下心仔细学习,你会发现在Caffe中定义一个网络其实是非常方便的,而且不需要我们写任何C++或者Python代码。
在Caffe中,定义网络的结构需要用的到Google的Protocol Buffer。我们现在可以先不急着去深入了解Protocol Buffer,我们只需要知道,Protocal Buffer就是一种用来描述数据结构的简单的语言(类似XML,但是比XML强大得多)。
幸运的是,Caffe的MNIST例子中已经有写好了的LeNet网络结构,这个网络结构的定义在这里:
$CAFFE_ROOT/examples/mnist/lenet_train_test.prototxt。
现在你可以打开它查看一下,看看里面的内容是什么,是不是很像C语言里面的结构(struct)呀?看看自己能否看出来这些内容的含义。
注意:Protocol Buffer文件一般都是以.prototxt结尾的文本文件。
现在,我们复制lenet_train_test.prototxt中的内容,打开网址:http://ethereon.github.io/netscope/#/editor,粘帖进去,然后按shift+enter,看看这个网络到底是什么样的。
看不出来没关系,下面会仔细讲解这个文件的内容。另外,虽然这里有个现成的LeNet结构定义文件,但是光看它的内容是不能掌握Caffe的,你还是应该亲自动手,在目录$CAFFE_ROOT/examples/mnist下创建一个空白的文件,并命名为my_lenet.prototext。下面我们就在my_lenet.prototext中亲自定义一个LeNet。
3.1 给你的网络取个好听的名字
第一步,当然得给网络取个好听的名字,对吧?
用你喜欢的编辑器打开你刚刚创建的文件:$CAFFE_ROOT/examples/mnist/my_lenet.prototext。现在,该文件是空的,我们在第一行写上:
name: "LeNet"那么取名这个事情就完成了。
3.2 网络当然要有输入数据才能训练
名字取好之后,在新的一行,我们来定义数据的输入层,层(layer)这个概念在Caffe中是非常重要的,现在我们使用关键字layer来定义网络的一个层,这里我们定义数据输入层。在文件$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接着添加如下内容:
layer {
name: "mnist" // 网络层的名字
type: "Data" // 网络层的类型,这里Data指的是数据层,后面你还会看到其他类型的层
top: "data" // top属性指明本层的数据将输出到何处,这里数据将保存到data中
top: "label" // 数据的标签将保存在label中
include { // 此属性用于确定在哪个过程中使用本层
phase: TRAIN // 只在训练的过程中使用本层
}
transform_param { // 这个是网络层的数据转换属性,在Caffe的网络层中传输数据时,可以对数据进行处理
scale: 0.00390625 // 用于修改数据范围,就是所有输入的数据都乘以这个值,0.00390625=1/256
// 因为灰度图是0~255,乘以scale,那么所有的数据都在0~1之间,方便处理。
}
data_param { // 这个用于定义数据的一些属性
source: "examples/mnist/mnist_train_lmdb" // 保存训练集的文件夹
backend: LMDB // 后端使用的是LMDB来保存数据,在文章开头讲过Caffe的数据集形式
batch_size:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









