






本篇代码的内容如下:
在上一篇的代码的基础上。1,修改了生成的图片名称中还包含绝对路径的问题
2.一键式,将每一个患者的一维信号记录,变成对应的,适合于图像分类任务的csv。
3.按照传统的划分方式,将数据集划分为训练集和测试集
filename = directory + '/' + change_name(filename_csv)+str(data_frame['sample_dot'][i]) + data_frame['labels'][i] + '.jpg'核心:
def draw_pictures(data_frame, raw_data,filename_csv):
#生成图片的存放地址
directory = '/data1/ar/data_process/ecg_data_demo'
labels = []
file_name = []
#第一个和最后两个样本不要
for i in range(1,len(data_frame['labels'])-1):
fig = plt.figure(frameon=True)
labels.append(data_frame['labels'][i])
#plt.plot(raw_data[2][data_frame['sample_dot'][i]-50:data_frame['sample_dot'][i]+150])
plt.plot(raw_data[2][data_frame['sample_dot'][i - 1] + 20:data_frame['sample_dot'][i + 1] - 20])
plt.xticks([]), plt.yticks([])
for spine in plt.gca().spines.values():
spine.set_visible(False)
filename = directory + '/' + change_name(filename_csv)+str(data_frame['sample_dot'][i]) + data_frame['labels'][i] + '.jpg'
fig.savefig(filename)
file_name.append(chage_name2(filename))
im_gray = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)
im_gray = cv2.resize(im_gray, (128, 128), interpolation=cv2.INTER_LANCZOS4)
cv2.imwrite(filename, im_gray)
plt.close()
dataset_frame = {'file_name': file_name, 'labels': labels}
dataset_frame = pd.DataFrame(dataset_frame)
#dataset_frame保存为csv文件
csv_filename = change_name(filename_csv)
#csv存放地址
csv_path = '/data1/ar/data_process/ecg_data_demo/csv'
csv_path = os.path.join(csv_path, csv_filename+'.csv')
dataset_frame.to_csv(csv_path, index=False)
print(f'DataFrame saved to {csv_path}')跑出来的结果如下:
48个病人记录的2D样本以及对应的标签全部在这里了。
在一般情况下,不是所有数据都是要被使用的,根据, 大多数人的做法,是把48个病例分成DS1,和DS2,其中,
DS1 = [101, 106, 108, 109, 112, 114, 115, 116, 118, 119, 122, 124, 201, 203, 205, 207, 208, 209, 215, 220, 223, 230] DS2 = [100, 103, 105, 111, 113, 117, 121, 123, 200, 202, 210, 212, 213, 214, 219, 221, 222, 228, 231, 232, 233, 234]
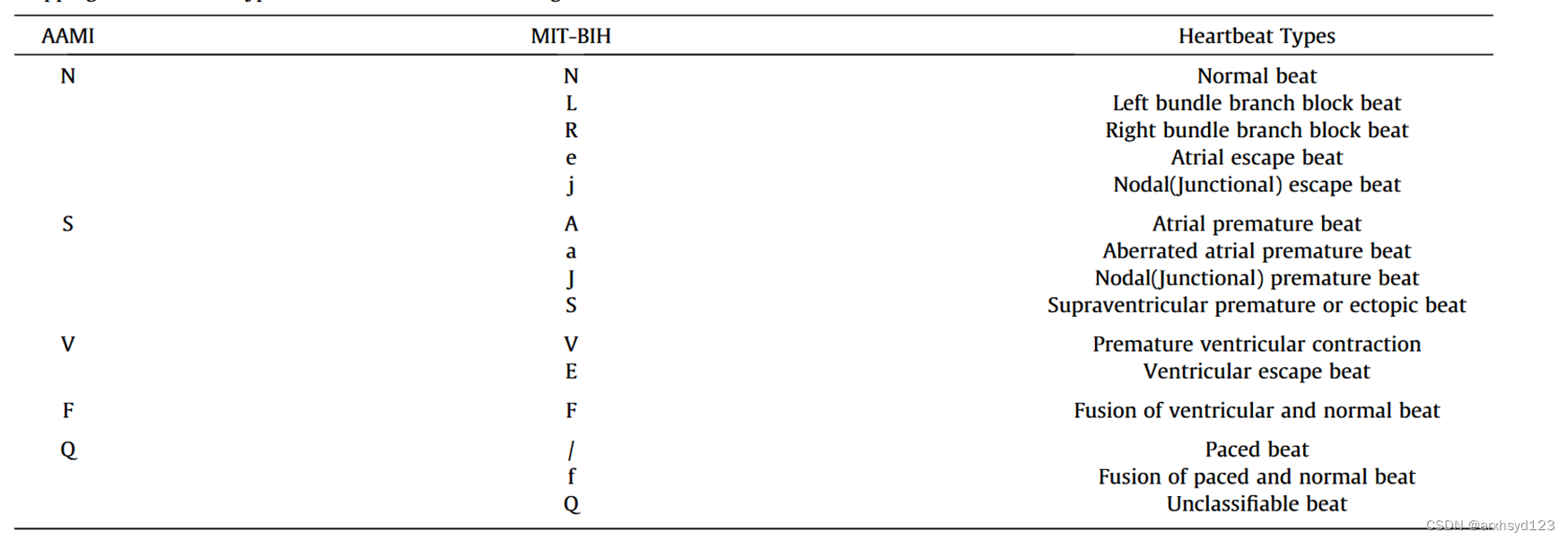
可以把一个作为训练集,一个作为测试集,而且label也被分成了5大类。
核心代码如下:
MITBIH_classes = ['N', 'L', 'R', 'e', 'j', 'A', 'a', 'J', 'S', 'V', 'E', 'F'] # , 'P', '/', 'f', 'u']
AAMI_classes = []
AAMI_classes.append(['N', 'L', 'R']) # N label-0
AAMI_classes.append(['A', 'a', 'J', 'S', 'e', 'j']) # SVEB label-1
AAMI_classes.append(['V', 'E']) # VEB label-2
AAMI_classes.append(['F']) # F label-3
# AAMI_classes.append(['P', '/', 'f', 'u']) # Q drop for data in datalist:
data_csv = pd.read_csv(os.path.join(root_dic,str(data)+'.csv'))
labels_list = data_csv['labels'].tolist()
file_name = data_csv['file_name'].tolist()
for i in range(len(labels_list)):
for j in range(len(AAMI_classes)):
if labels_list[i] in AAMI_classes[j]:
clean_list.append(j)
file_names.append(file_name[i])
break
dataset_frame = {'file_name': file_names, 'labels': clean_list}
test_dataset_frame = pd.DataFrame(dataset_frame)
#csv_path = '/data1/ar/data_process/DS1.csv'
csv_path = '/data1/ar/data_process/DS2.csv'
更加完善。更加易处理。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









