






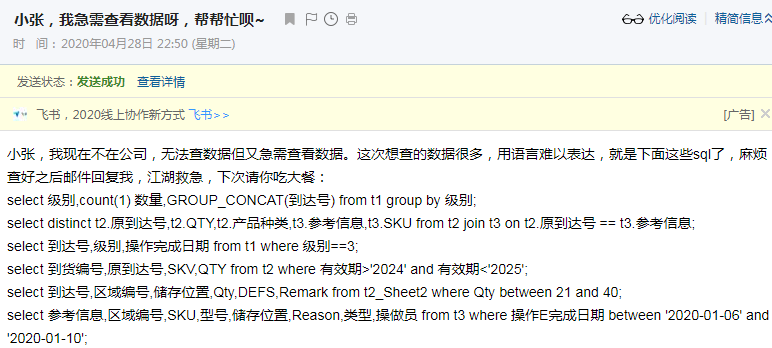
然后,我真的震惊了,本以为小张至少要查个20分钟的,结果10秒不到就回复我了:
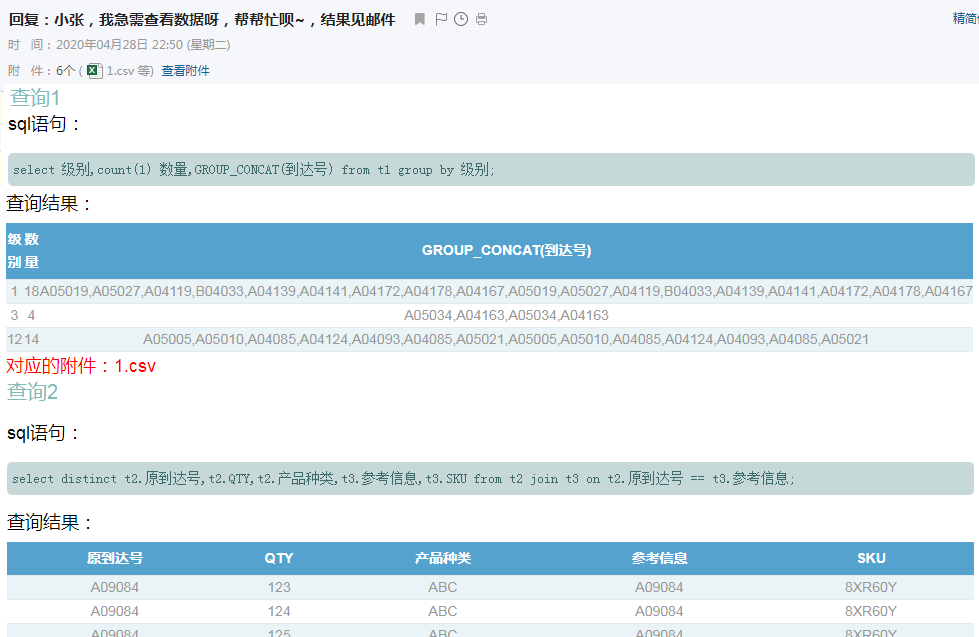
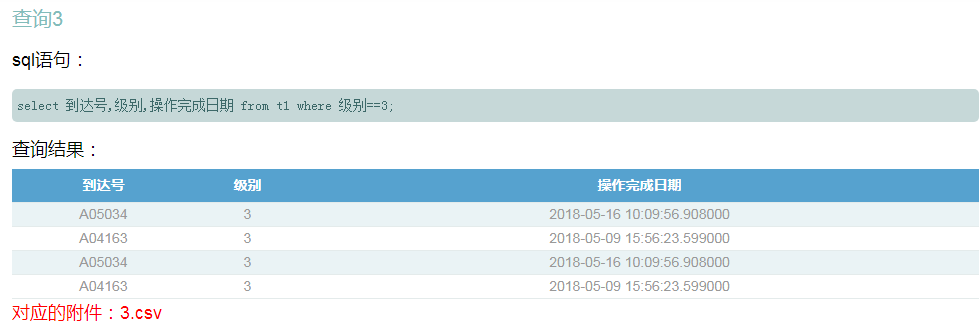

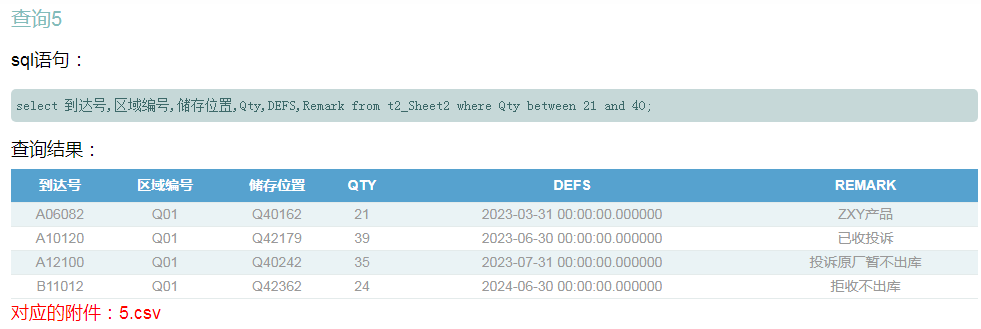
好奇心超强的我等回到公司,马上问小张,为什么能这么快?居然不告诉我。
但是好奇心超强的我,并不会因此放弃,在我努力研究了2天python后,哈哈哈,我自己也做了一套一模一样的系统,下面我会将这些技术毫无保留的告诉你。
其实原理很简单,就是把本地要被查询的excel表统统注册成sql表,启动一个收邮件的客户端,不停的扫描未读邮件,一旦发现有满足条件的未读邮件,就启动读取语句,并启动sql查询,然后再启动一个邮件发送端,把邮件回去回去即可。
废话不多说,看看实现代码吧。(第5版和第6版也开始启动中,欢迎持续关注噢)
第四版指定配置文件规则构建可进行sql查询的DAO层编写用于页面渲染的view层编写用于接收邮件的Controller编写发送邮件相关的工具类编写串通整个流程的Context启动对象
第四版
本系统前面已经开发了三个版本,这个版本参考MVC设计思想进行重构,以页面渲染方式回复邮件。
指定配置文件规则
config.py文件的内容如下:
# 白名单,只处理列表内的邮件地址发来的邮件
blacklist = ["aaa@qq.com", "bbb@163.com", "ccc@qq.com", "ddd@163.com"]
imapServer = "imap.163.com"
smtpServer = "smtp.163.com"
user = 'xxx@163.com'
password = 'xxx'
# 可配置为一个路径字符串,或者文件名列表
# 类型为字符串时,被认为是路径,将搜索该路径下的所有xlsx文件,类型为列表时,则只加载指定文件名
files = r"D:\PycharmProjects\jupyter\self_test\excel_query_system\exceldata" # 表示读取该路径下的所有xlsx文件
# files = ["exceldata/t1.xlsx", "exceldata/t1.xlsx", "exceldata/t1.xlsx"]
# 邮件标题正则匹配规则,满足条件的标题才处理
keys = "查|(sql)|(数据)"
# 邮件内每个结果显示的最大表格行数
max_table_line = 20
# 每个csv附近文件的最大行数
max_csv_line = 500
构建可进行sql查询的DAO层
加载所配置的excel表文件数据加载到内存,同时将其注册成为可以查询的sql表
把每个excel文件看到一个数据库,每个excel文件里的工作表看成一张数据库里的表,用_分割,表单对应sql里的表名就是excel文件名_sheetname。
如果只传excel的文件名作为表名,则查询这个excel文件的第一张表。
LoadExcelToSQL.py文件内容如下:
from pandasql import sqldf
import config, os
import pandas as pd
# 将excel全部加载到内存
def reloadExcelFile():
def handle(xlsx):
df = pd.read_excel(xlsx, 0)
name = file.rstrip(".xls").rstrip(".xlsx")
df_dict[name] = df
for i, sheetname in enumerate(xlsx.sheet_names):
if i == 0:
df_dict[f"{name}_{sheetname}"] = df
else:
df_dict[f"{name}_{sheetname}"] = pd.read_excel(xlsx, i)
print(f"加载{file}中的{sheetname}表单")
print("现在要将所配置的excel表文件数据加载到内存,可能耗时较长")
df_dict = {}
if isinstance(config.files, str):
for file in os.listdir(config.files):
if file.startswith("~") or not file.endswith(".xlsx"): continue
xlsx = pd.ExcelFile(os.path.join(config.files, file))
handle(xlsx)
elif isinstance(config.files, list):
for file in config.files:
xlsx = pd.ExcelFile(file)
handle(xlsx)
print("加载完毕")
tablelist = "、".join(df_dict.keys())
return lambda sql: sqldf(sql, df_dict), tablelist
编写用于页面渲染的view层
使用jinja2语法渲染html页面
创建一个html模板文件df.html,存放在htmlModule/templates文件夹中
内容如下(省略了CSS样式部分):
<div class="page">
<h1>excel sql查询系统</h1>
{% for i,sql,table in tables %}
<h3>查询{{ i }}</h3>
<p>sql语句:</p>
<code>
{{ sql }}
</code>
{{ table }}
{% endfor %}
<hr />
<h2>关于</h2>
<p>尊敬的<{{ user }}>您好,您位于本系统的白名单,主题中出现(查、sql或数据)关键字时会触发sql查询,
会检测每一条以select开头的sql语句,并查询后返回结果。</p>
<p>每个excel文件名+_+sheet表单名会被注册为sql表名,单excel文件名注册的表对应excel文件的第一个表单。</p>
<p>目前注册到系统中,可供查询的表有:</p>
<p>{{ tablelist }}</p>
<p>所有的表均支持标准sql语法查询。</p>
<h3>sql语法示例如下:</h3>
<code>
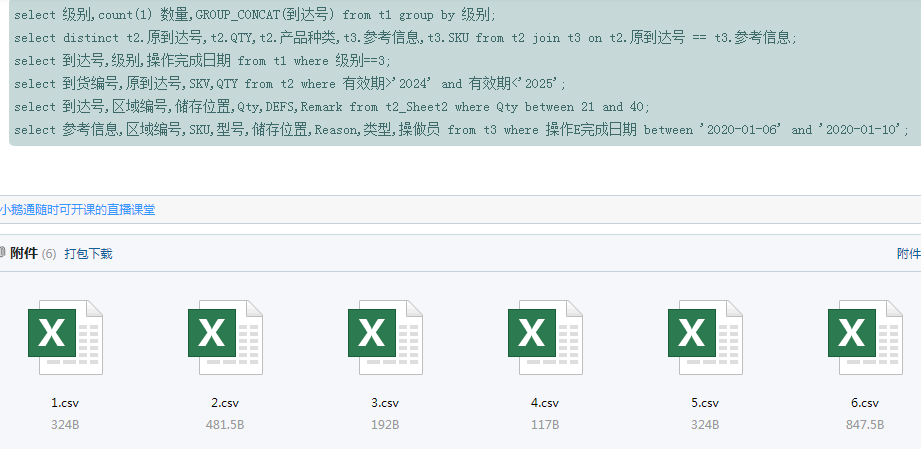
select 级别,count(1) 数量,GROUP_CONCAT(到达号) from t1 group by 级别;<br/>
select distinct t2.原到达号,t2.QTY,t2.产品种类,t3.参考信息,t3.SKU from t2 join t3 on t2.原到达号 == t3.参考信息;<br/>
select 到达号,级别,操作完成日期 from t1 where 级别==3;<br/>
select 到货编号,原到达号,SKV,QTY from t2 where 有效期>'2024' and 有效期<'2025';<br/>
select 到达号,区域编号,储存位置,Qty,DEFS,Remark from t2_Sheet2 where Qty between 21 and 40;<br/>
select 参考信息,区域编号,SKU,型号,储存位置,Reason,类型,操做员 from t3 where 操作E完成日期 between '2020-01-06' and '2020-01-10';
</code>
</div>
创建一个MailSQLResultView.py文件,内容如下:
import logging
import LoadExcelToSQL
from jinja2 import Environment, PackageLoader
import config
class MailSQLResultView:
def __init__(self):
pysqlDao, tablelist = LoadExcelToSQL.reloadExcelFile()
self.pysqlDao = pysqlDao
self.tablelist = tablelist
# 配置jinja2在本地文件系统的搜索路径
env = Environment(loader=PackageLoader('htmlModule'))
self.template = env.get_template('df.html')
def batch_sql_query(self, sqls) -> (list, list):
tables = []
csvs = []
for i, sql in enumerate(sqls):
print(i, sql)
try:
# 每条查询语句最大查询500条数据
data = self.pysqlDao(sql).head(config.max_csv_line)
# 每条sql网页最多只展示前10条,完整的500条数据需下载csv附件
tables.append((i + 1, sql,
f"<p>查询结果:</p>{data.head(config.max_table_line).to_html(index=False, na_rep='', border='0')}<p>"
f"<font color='red'>对应的附件:{i + 1}.csv</font></p>"))
csvs.append((i + 1, data.to_csv(index=False, na_rep='')))
except Exception as e:
error = str(e)
logging.exception(error)
tables.append((i + 1, sql, f"<p>报错信息:</p><code><font color='red'>{error}</font></code>"))
return tables, csvs
def getHtmlView(self, user, tables):
return self.template.render(user=user, tables=tables, tablelist=self.tablelist)
编写用于接收邮件的Controller
用于接收邮件处理相关的工具类,MailReceiveHandleUtil.py内容如下:
import email
import imaplib
from email.header import decode_header
from email.utils import parseaddr
import config
def login_and_select_INBOX():
"登陆imap邮箱,并选择接收收件箱"
conn = imaplib.IMAP4(config.imapServer, 143)
conn.login(config.user, config.password)
# 选择收件箱:
conn.select("INBOX")
return conn
def fetchmsg(conn, i):
"抓取指定编号的邮件"
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
def decode_str(s):
"解码函数"
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def getinfo(msg):
"解析出邮件中的发件人,收件人和主题,"
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
def guess_charset(msg):
"用于分析邮件内容的编码"
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def parse_msg(msg, contentlist: list):
"递归解析邮件中的文本内容存储到contentlist中"
if msg.is_multipart():
parts = msg.get_payload()
for part in parts:
parse_msg(part, contentlist)
elif msg.get_content_type() == 'text/plain':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
if content:
contentlist.append(content)
def unescape(s):
"还原html转义字符"
s = s.replace("<", "<")
s = s.replace(">", ">")
s = s.replace("&", "&")
return s
ImapMailReceiveController.py文件内容如下:
from MailReceiveHandleUtil import *
class ImapMailController:
def __init__(self, context, receiveType='Recent'):
self.context = context
self.receiveType = receiveType
def startOnceReceive(self):
# 登陆邮箱
conn = login_and_select_INBOX()
# 获取所有未读邮件的序号
t, data = conn.search(None, self.receiveType)
msgList = data[0].split()
for i in msgList:
msg = fetchmsg(conn, i)
mailMeta = getinfo(msg)
contentList = []
parse_msg(msg, contentList)
mailContent = "".join(contentList)
mailContent = unescape(mailContent)
# 将解析出来的每一封邮件的元信息和邮件内容交给上下文context对象处理
self.context.processMail(mailMeta, mailContent)
conn.close()
conn.logout()
编写发送邮件相关的工具类
用于构建邮件内容的工具类,MailSendHandleUtil.py文件内容如下:
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
def buildMessageByString(s):
message = MIMEMultipart()
message.attach(MIMEText(s, 'html', 'utf-8'))
return message
def buildMessageByTables(page, csvs):
message = MIMEMultipart()
for i, csv in csvs:
att = MIMEText(csv, 'base64', 'utf-8')
att["Content-Type"] = 'application/octet-stream'
att["Content-Disposition"] = f'attachment; filename="{i}.csv"'
message.attach(att)
message.attach(MIMEText(page, 'html', 'utf-8'))
return message
将邮件发送出去的工具类,smtpMailSender.py文件内容如下:
import smtplib
from email.header import Header
from email.utils import formataddr
import config
def sendmail(message, mailMeta):
message['From'] = formataddr(["数据查询专员pysql", config.user]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
message['To'] = formataddr([mailMeta.get("name", mailMeta['From']), mailMeta['From']]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
message['Subject'] = Header(f"回复:{mailMeta['Subject']},结果见邮件", 'utf-8')
smtpObj = smtplib.SMTP(config.smtpServer, 25)
smtpObj.login(config.user, config.password)
smtpObj.sendmail(config.user, mailMeta['From'], message.as_string())
print("邮件发送成功")
smtpObj.close()
编写串通整个流程的Context启动对象
AppContext.py文件内容如下:
import re
import time
import LoadExcelToSQL
import config
from ImapMailReceiveController import ImapMailController
from MailSQLResultView import MailSQLResultView
from MailSendHandleUtil import *
from smtpMailSender import sendmail
class AppContext():
def __init__(self):
self.imapMailController = ImapMailController(self)
self.view = MailSQLResultView()
def checkInstruct(self, subject):
if subject == "reloadExcelFile":
pysqlDao, tablelist = LoadExcelToSQL.reloadExcelFile()
self.view.pysqlDao = pysqlDao
self.view.tablelist = tablelist
return "reload Excel File Successful"
return None
def processMail(self, mailMeta, mailContent):
print("收到邮件:", mailMeta, "内容:", mailContent[:20])
if mailMeta['From'] not in config.blacklist:
print(mailMeta['From'], "不在白名单,不作处理")
return
if mailMeta['Subject'].startswith("回复") or mailMeta['Subject'].startswith("Re"):
print("该邮件以回复或Re开头,不作处理")
return
instructResult = self.checkInstruct(mailMeta['Subject'])
if instructResult:
print(mailMeta['From'], "执行了", mailMeta['Subject'], "指令")
message = buildMessageByString(instructResult)
sendmail(message, mailMeta)
elif re.search(config.keys, mailMeta['Subject']):
print("触发查询关键字,开始处理")
sqls = [line for line in mailContent.splitlines() if line.startswith("select")]
print(sqls)
tables, csvs = self.view.batch_sql_query(sqls)
page = self.view.getHtmlView(mailMeta.get("name", mailMeta['From']), tables)
message = buildMessageByTables(page, csvs)
sendmail(message, mailMeta)
def start(self):
while 1:
self.imapMailController.startOnceReceive()
time.sleep(5)
app = AppContext()
app.start()
为了让读者大致理解邮件收取的操作,再次演示一下第一版的编写过程:
目录:
imap接收邮件测试编写持续接收未读邮件的程序编写数据处理逻辑回复邮件的程序第一版处理系统编写扩展需求白名单机制邮件文本内容解析可以进行多表处理的逻辑邮件构建器第二版系统完整代码编写
imap接收邮件测试
注意,你的邮箱必须开启IMAP和SMTP服务才能使用,如果使用qq或网易这类邮箱。代码中使用的密码是专用的授权码,而不是你的邮箱登陆密码:
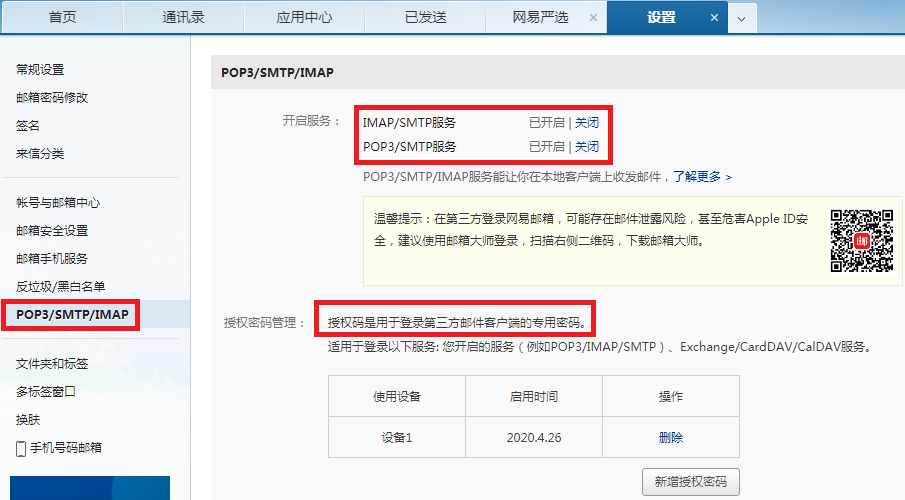
首先建立连接并登陆:
import imaplib
mailServer = "imap.163.com"
user = 'xxm@163.com'
password = 'xxx'
conn = imaplib.IMAP4(mailServer, 143)
conn.login(user, password)
('OK', [b'LOGIN completed'])
注意:
网易云的邮箱后面操作中可能会报:
imaplib.error: command SEARCH illegal in state AUTH, only allowed in states SELECTED
这是网易为了推自己的客户端,邮箱大师作怪。
解决方案:
使用字母邮箱,不要使用电话号码邮箱。
然后配置一下:
http://config.mail.163.com/settings/imap/index.jsp?uid=YOUR_EMAIL_NAME@163.com
例如你的邮箱地址是xxm@163.com,则地址为:
http://config.mail.163.com/settings/imap/index.jsp?uid=xxm@163.com
选择一个目录,收件箱默认名称是"INBOX",如果是自己新建的文件夹,名称一般会是"INBOX.新建文件夹",不同的邮箱表示方式不一样。
可以运行conn.list()查看所有的文件夹:
conn.list()
('OK',
[b'() "/" "INBOX"',
b'(\\Drafts) "/" "&g0l6P3ux-"',
b'(\\Sent) "/" "&XfJT0ZAB-"',
b'(\\Trash) "/" "&XfJSIJZk-"',
b'(\\Junk) "/" "&V4NXPpCuTvY-"',
b'() "/" "&dcVr0mWHTvZZOQ-"',
b'() "/" "&Xn9USpCuTvY-"',
b'() "/" "&i6KWBZCuTvY-"'])
选择收件箱:
conn.select("INBOX")
('OK', [b'8'])
然后搜索指定类型的邮件,第二个参数一般选项有:
"ALL": 所有邮件
"Recent": 未读邮件
"Seen": 已读邮件
"Answered": 已回复的邮件
"Flagged": 被标记为“紧急/特别注意”的邮件
"Deleted": 已删除邮件,但python无法看到
"Draft": 草稿箱内的邮件,但python无法看到
还可以填写:
conn.search(None, '(SUBJECT "Essh")')
表示找Essh邮件。也可以同时指定多个查询条件,例如(FROM xxxx SUBJECT "aaa")表示来自xxxx主题为aaa.
可参考:http://www.afterlogic.com/mailbee-net/docs/MailBee.ImapMail.Imap.Search_overload_1.html
search第一个参数是charset的意思,填None表示用默认ASCII:
t, data = conn.search(None, 'ALL')
msgList = data[0].split()
msgList
[b'1', b'2', b'3', b'4', b'5', b'6', b'7', b'8']
msgList返回了一个邮件序号,从1到N编号。一般情况下,编号越大距离现在越近。
现在以RFC822获取最近一封邮件的邮件格式,再用email.message_from_string转换为message对象:
import email, base64
def fetchmsg(i):
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
msg = fetchmsg(msgList[-1])
print(msg)
Received: from wowangzhouming$163.com ( [223.104.63.49] ) by
ajax-webmail-wmsvr124 (Coremail) ; Sun, 26 Apr 2020 23:14:27 +0800 (CST)
X-Originating-IP: [223.104.63.49]
Date: Sun, 26 Apr 2020 23:14:27 +0800 (CST)
From: =?GBK?B?0KHQocP3?= <wowangzhouming@163.com>
To: 15074804724@163.com
Subject: test
X-Priority: 3
X-Mailer: Coremail Webmail Server Version XT5.0.10 build 20190724(ac680a23)
Copyright (c) 2002-2020 www.mailtech.cn 163com
X-CM-CTRLDATA: qAC2E2Zvb3Rlcl9odG09MTA5OjU2
Content-Type: multipart/alternative;
boundary="----=_Part_134809_656158486.1587914067467"
MIME-Version: 1.0
Message-ID: <1e801115.962c.171b70dce0b.Coremail.wowangzhouming@163.com>
X-Coremail-Locale: zh_CN
X-CM-TRANSID: fMGowACHwPtTpaVe7cAjAA--.21747W
X-CM-SenderInfo: pzrzt05j2k03pplqwqqrwthudrp/1tbiSgMS-lPAK-bSWgARsy
X-Coremail-Antispam: 1U5529EdanIXcx71UUUUU7vcSsGvfC2KfnxnUU==
------=_Part_134809_656158486.1587914067467
Content-Type: text/plain; charset=GBK
Content-Transfer-Encoding: 7bit
no
------=_Part_134809_656158486.1587914067467
Content-Type: text/html; charset=GBK
Content-Transfer-Encoding: 7bit
<div style="line-height:1.7;color:#000000;font-size:14px;font-family:Arial"><p style="margin:0;">no</p></div><br><br><span title="neteasefooter"><p> </p></span>
------=_Part_134809_656158486.1587914067467--
经过一番努力已经获得了一堆看不懂的内容,现在访问我们需要的内容:
print(msg['subject'])
print(msg['from'])
print(msg['to'])
test
=?GBK?B?0KHQocP3?= <wowangzhouming@163.com>
15074804724@163.com
返回的东西仍需要解码,现在编写解码函数,并进行解码:
from email.header import decode_header
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
from email.utils import parseaddr
def getinfo(msg):
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
getinfo(msg)
{'name': '小小明',
'From': 'xxm@163.com',
'To': '15074804724@163.com',
'Subject': 'test'}
for i in msgList:
msg = fetchmsg(i)
result = getinfo(msg)
print(i, result)
b'1' {'name': '网易邮件中心', 'From': 'mail@service.netease.com', 'To': 'wowangzhouming@163.com', 'Subject': '网易邮箱,那些你知道和不知道的事'}
b'2' {'name': '网易帐号中心 ', 'From': 'passport@service.netease.com', 'To': 'm15074804724@163.com', 'Subject': '网易邮箱帐号异常登录提醒'}
b'3' {'name': '网易帐号中心 ', 'From': 'passport@service.netease.com', 'To': 'm15074804724@163.com', 'Subject': '网易邮箱帐号异常登录提醒'}
b'4' {'name': '微信团队', 'From': 'weixinteam@qq.com', 'To': '15074804724@163.com', 'Subject': '微信小程序长时间未使用将被冻结'}
编写持续接收未读邮件的程序
#!/usr/bin/env python
# coding: utf-8
import imaplib
import email, base64, time
from email.header import decode_header
from email.utils import parseaddr
# 建立连接并登陆:
def loginAndSelect():
mailServer = "imap.163.com"
user = 'xxm@163.com'
password = 'xxx'
conn = imaplib.IMAP4(mailServer, 143)
conn.login(user, password)
# 选择收件箱:
conn.select("INBOX")
return conn
# 抓取指定编号的邮件
def fetchmsg(conn, i):
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
# 解码函数
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 解析出邮件中的发件人,收件人和主题,
def getinfo(msg):
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
def main():
# login
while 1:
conn = loginAndSelect()
# 获取所有未读邮件的序号
t, data = conn.search(None, 'Recent')
msgList = data[0].split()
for i in msgList:
msg = fetchmsg(conn, i)
result = getinfo(msg)
print(i, result)
conn.close()
conn.logout()
# 每10秒检测一次
time.sleep(10)
main()
b'1' {'name': '网易邮件中心', 'From': 'mail@service.netease.com', 'To': 'wowangzhouming@163.com', 'Subject': '网易邮箱,那些你知道和不知道的事'}
b'2' {'name': '网易帐号中心 ', 'From': 'passport@service.netease.com', 'To': 'm15074804724@163.com', 'Subject': '网易邮箱帐号异常登录提醒'}
b'3' {'name': '网易帐号中心 ', 'From': 'passport@service.netease.com', 'To': 'm15074804724@163.com', 'Subject': '网易邮箱帐号异常登录提醒'}
b'4' {'name': '微信团队', 'From': 'weixinteam@qq.com', 'To': '15074804724@163.com', 'Subject': '微信小程序长时间未使用将被冻结'}
经测试,程序顺利运行成功。
编写数据处理逻辑
import pandas as pd
df = pd.read_excel(r"data.xlsx")
df.head()前面我写了使用SQL操作Pandas以及使用DataFrame的query函数过滤数据一文,其实我们依然可以里面这种类sql的语法,直接将字符串传入query方法。
单值查询:
df.query("操作等级==3")多值查询与逻辑运算:
df.query("序号 in (4,8) or 操作等级==3")范围查询:
df.query("实际开始日期>'2018-05-15' and 实际开始日期<'2018-05-16'")几乎sql语句的where过滤部分都支持。测试一下生成csv和html表格文本:
data = df.query("序号 in (4,8)")
data.to_csv(index=False)data.to_html(index=False)
回复邮件的程序
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import Header
# 第三方 SMTP 服务
from email.utils import formataddr
mail_host = "smtp.163.com" # 设置服务器
mail_user = 'xxm@163.com' # 用户名
mail_pass = 'xxx' # 口令
receiver = '604049322@qq.com' # 接收邮箱
mail_msg = """
<p>Python 邮件发送测试...</p>
<p><a href="http://blog.xiaoxiaoming.xyz">网站链接</a></p>
<p>图片演示:</p>
"""
# 创建一个带附件的实例
message = MIMEMultipart()
message['From'] = formataddr(["^_^我是发件人小小明",
mail_user]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
message['To'] = formataddr(["这里写收件人", receiver]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
message['Subject'] = Header('反馈结果', 'utf-8')
# 邮件正文内容
message.attach(MIMEText(mail_msg, 'html', 'utf-8'))
att1 = MIMEText(mail_msg, 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename="test.txt"'
message.attach(att1)
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host, 25) # 25 为 SMTP 端口号
smtpObj.login(mail_user, mail_pass)
smtpObj.sendmail(mail_user, receiver, message.as_string())
print("邮件发送成功")
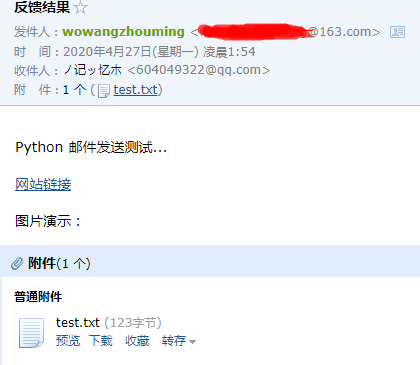
经测试发邮件的程序也顺利。
第一版完整的处理系统编写
#!/usr/bin/env python
# coding: utf-8
import imaplib
import email, base64, time
from email.header import decode_header
from email.utils import parseaddr
import pandas as pd
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import Header
# 第三方 SMTP 服务
from email.utils import formataddr
# 建立连接并登陆:
def loginAndSelect():
imapServer = "imap.163.com"
user = 'xxx@163.com'
password = 'xxx'
conn = imaplib.IMAP4(imapServer, 143)
conn.login(user, password)
# 选择收件箱:
conn.select("INBOX")
return conn
# 抓取指定编号的邮件
def fetchmsg(conn, i):
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
# 解码函数
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 解析出邮件中的发件人,收件人和主题,
def getinfo(msg):
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
def main():
df = pd.read_excel(r"data.xlsx")
# login
while 1:
conn = loginAndSelect()
# 获取所有未读邮件的序号
t, data = conn.search(None, 'Recent')
msgList = data[0].split()
for i in msgList:
msg = fetchmsg(conn, i)
result = getinfo(msg)
print(i, result['name'], result['From'], result['Subject'])
smtpServer = "smtp.qq.com"
user = "604049322@qq.com"
password = 'xxx'
# 创建一个带附件的实例
message = MIMEMultipart()
message['From'] = formataddr(["数据回复员", user]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
message['To'] = formataddr([result['name'], result['From']]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
message['Subject'] = Header(f"查询{result['Subject']}的结果", 'utf-8')
try:
# 执行查询,最大返回1000条数据
data = df.query(result['Subject']).head(1000)
# 邮件正文内容
message.attach(MIMEText(data.to_html(index=False), 'html', 'utf-8'))
# 附件内容
att1 = MIMEText(data.to_csv(index=False), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename="result.csv"'
message.attach(att1)
except Exception as e:
mes = f"""查询语法错误,错误信息:{e}
请将要查询的内容按照如下规则作为邮件标题,语法示例:
查询操作等级等于3的数据:操作等级==3
查询序号为4或8的数据:序号 in (4,8)
查询某个数据段的数据:实际开始日期>'2018-05-15' and 实际开始日期<'2018-05-16'
"""
# 邮件正文内容
message.attach(MIMEText(mes, 'plain', 'utf-8'))
smtpObj = smtplib.SMTP_SSL(smtpServer, 465)
smtpObj.login(user, password)
smtpObj.sendmail(user, result['From'], message.as_string())
print("邮件发送成功")
smtpObj.close()
conn.close()
conn.logout()
# 每10秒检测一次
time.sleep(10)
main()
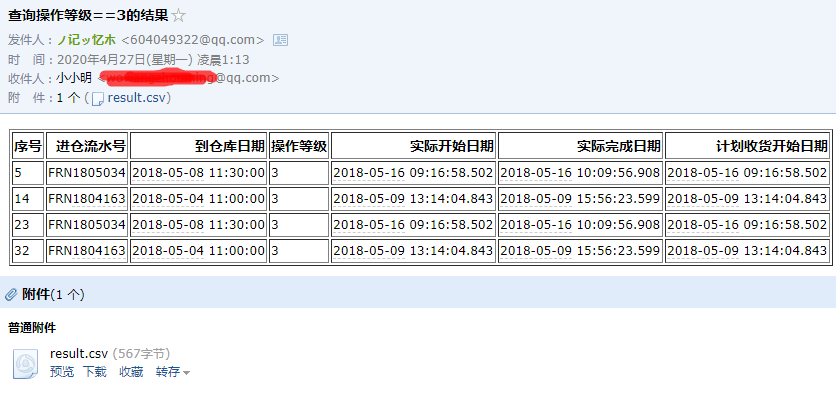
b'17' ノ记ッ忆ホ wowangzhouming@qq.com Re:查询操作等级==3的结果
邮件发送成功
经测试,程序可以持续保证运行,每10秒检测一下是否存在新邮件,有则进行处理。
发送邮件:
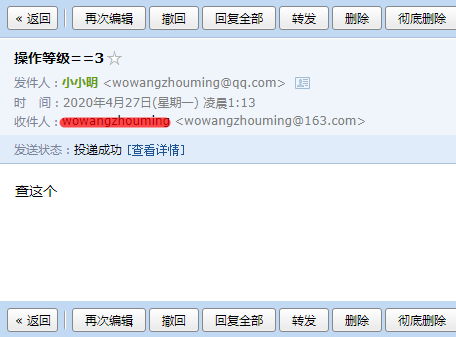
返回结果:
扩展需求
白名单机制邮件文本内容解析可以进行多表处理的逻辑邮件构建器第二版系统完整代码编写
现在将增加白名单机制,并支持一个邮件即可进行多个查询,以前只解释邮件主题,现在将进行复杂的邮件内容解析
白名单机制
白名单机制表示只对指定收件人列表的邮件进行应答,这个白名单,我们保存到一个py文件中作为配置文件,方便后期修改。
干脆发件和收件的邮箱也写到一个配置文件中,创建一个config.py文件,内容如下:
blacklist = ["aaaa@qq.com", "bbbb@163.com", "ccccc@163.com"]
imapServer = "imap.163.com"
imapuser = 'aaaa@163.com'
imappassword = 'xxxx'
smtpServer = "smtp.qq.com"
smtpuser = "bbb@qq.com"
smtppassword = 'xxxx'
访问方式:
import config
config.blacklist
['604049322@qq.com', 'wowangzhouming@163.com', 'wowangzhouming@qq.com']只需要增加如下代码即可实现白名单机制:
if result['From'] not in config.blacklist:
continue
邮件文本内容解析
为了实现能处理邮件中的文本内容,不止是主题,编写了两个解析函数:
# 用于分析邮件内容的编码
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
# 递归解析邮件中的文本内容存储到contentlist中
def parse_msg(msg, contentlist: list):
# 对与多块还需递归调用
if msg.is_multipart():
parts = msg.get_payload()
for part in parts:
parse_msg(part, contentlist)
elif msg.get_content_type() == 'text/plain':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
if content:
contentlist.append(content)
测试邮件解析功能:
#!/usr/bin/env python
# coding: utf-8
import email
import imaplib
from email.header import decode_header
from email.utils import parseaddr
# 第三方 SMTP 服务
import config
# 建立连接并登陆:
def loginAndSelect():
conn = imaplib.IMAP4(config.imapServer, 143)
conn.login(config.imapuser, config.imappassword)
# 选择收件箱:
conn.select("INBOX")
return conn
# 抓取指定编号的邮件
def fetchmsg(conn, i):
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
# 解码函数
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 解析出邮件中的发件人,收件人和主题,
def getinfo(msg):
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
# 用于分析邮件内容的编码
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
# 递归解析邮件中的文本内容存储到contentlist中
def parse_msg(msg, contentlist: list):
# 对与多块还需递归调用
if msg.is_multipart():
parts = msg.get_payload()
for part in parts:
parse_msg(part, contentlist)
elif msg.get_content_type() == 'text/plain':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
if content:
contentlist.append(content)
conn = loginAndSelect()
# 获取所有未读邮件的序号
t, data = conn.search(None, 'ALL')
msgList = data[0].split()
for i in msgList:
msg = fetchmsg(conn, i)
result = getinfo(msg)
print(result.get('name', ''), result['From'], result['To'], result['Subject'])
contentList = []
parse_msg(msg, contentList)
content = "".join(contentList)
print(content)
conn.close()
网易帐号中心 passport@service.netease.com m15074804724@163.com 网易邮箱帐号异常登录提醒
拉勾网 lagou@mail.lagoujobs.com 15074804724@163.com [拉勾牛人在线]下一个CTO会不会是你?(AD)
拉勾网 lagou@mail.lagoujobs.com 15074804724@163.com 【直播招人】游戏大佬亲身示范,如何3小时稳准狠拿到Offer,预约!和大佬交个朋友>>>(AD)
拉勾网 lagou@mail.lagoujobs.com 15074804724@163.com 游戏行业的技术人,如何选择适合发展领域,拿到满意offer?速戳约大佬>>>(AD)
拉勾网 lagou@mail.lagoujobs.com 15074804724@163.com 拉勾教育1周年|你的学习、跳槽、升职加薪,我们包了(AD)
拉勾教育 lagou@mail.lagoujobs.com 15074804724@163.com 大数据从业者的高薪「潜规则」(AD)
小小明 wowangzhouming@163.com 15074804724@163.com test
no
wowangzhouming wowangzhouming@qq.com wowangzhouming@163.com query 重新给我查
t1::序号 in (4,8)
t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'
t2:Sheet2:Qty == 15
('OK', [b'CLOSE completed'])
经测试邮件中的文本内容均可正常获取。
可以进行多表处理的逻辑
前面的代码只能读取一个文件,而且文件名写死,现在改成可以配置的。
前面的config.py文件再加上:
# excel文件标示所对应的文件路径
filenames = {"t1": "t1.xlsx", "t2": "t2.xlsx", "t3": "t3.xlsx"}
# excel文件标示所对应的sheet名列表(整数索引或表单名称)
sheetnames = {"t1": ["Sheet1"], "t2": ["Sheet1", "Sheet2"], "t3": ["Sheet1"]}
import pandas as pd
import config
# 将excel全部加载到内存
df_dict = {}
for file, filepath in config.filenames.items():
xlsx = pd.ExcelFile(filepath)
for sheet in config.sheetnames[file]:
df = pd.read_excel(xlsx, sheet)
dfs = df_dict.setdefault(file, {})
dfs[sheet] = df
# 对应文件中sheet不存在则随机返回一张sheet
def findDataFream(file, sheet=None):
if file not in df_dict:
return None
dfs = df_dict[file]
if sheet not in dfs:
return list(dfs.values())[0]
return dfs[sheet]
df = findDataFream("t2")
df.head()解决html转义字符的问题:
def unescape(s):
s = s.replace("<", "<")
s = s.replace(">", ">")
s = s.replace("&", "&")
return s
unescape("t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'")
"t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'"
将用户编写的查询规则结构化:
def createQueryDF(content):
content = unescape(content)
se = pd.Series(content.splitlines())
querysdf = se.str.extract(r'(?P<file>.*):(?P<sheet>.*):(?P<query>.*)')
querysdf.dropna(subset=['file', 'query'], inplace=True)
return querysdf
querysdf = createQueryDF(content)
querysdf将用户编写的查询规则结构化(详细可见Pandas之子串匹配与提取(Series.str中的extract/extractall/contains/match)):
def createQueryDF(content):
content = unescape(content)
se = pd.Series(content.splitlines())
querysdf = se.str.extract(r'(?P<file>.*):(?P<sheet>.*):(?P<query>.*)')
querysdf.dropna(subset=['file', 'query'], inplace=True)
return querysdf
querysdf = createQueryDF(content)
querysdf
| file | sheet | query | |
|---|---|---|---|
| 0 | t1 | 序号 in (4,8) | |
| 1 | t1 | 实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16' | |
| 2 | t2 | Sheet2 | Qty == 15 |
邮件构建器
将开头的示例文本也写入的配置文件中:
config.py添加如下内容:
sample = f"""最新查询语法示例:
t1::序号 in (4,8)
t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'
t2:Sheet2:Qty == 15
每行表示一个查询规则,每个规则分为三段:文件名、表单名和查询语句,用:分割
一个excel文件中只有一个表单名时,表单名称可以省略。
序号 in (4,8)表示查询序号为4或8的数据,等价写法是 序号==4 or 序号==8
实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'表示查询日期为2018-05-15这一天的
Qty == 15表示查询Qty等于15的数据
"""
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# 查询并构建邮件内容
def buildMessage(querysdf=None):
message = MIMEMultipart()
if querysdf is None:
message.attach(MIMEText(config.sample, 'html', 'utf-8'))
return message
result = []
for i, row in querysdf.iterrows():
querystr = ":".join(row.values.tolist())
df = findDataFream(row.file, row.sheet)
if df is None:
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p><font color='red'>《{row.file}.xlsx》文件不存在</font><hr />")
continue
print(f"查询:{querystr}", "被查询的表列名为:", df.columns.values)
try:
# 每条查询语句最大查询100条数据
data = df.query(row.query).head(100)
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p>")
result.append(data.to_html(index=False))
result.append("<hr />")
# 附件内容
att = MIMEText(data.to_csv(index=False), 'base64', 'utf-8')
att["Content-Type"] = 'application/octet-stream'
att["Content-Disposition"] = f'attachment; filename="{i}.csv"'
message.attach(att)
except Exception as e:
logging.exception(e)
mes = str(e)
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p><p>语法错误:<font color='red'>{mes}</font></p><hr />")
# 邮件正文内容
message.attach(MIMEText(config.sample + "<br />".join(result), 'html', 'utf-8'))
return message
buildMessage(querysdf)
查询:t1::序号 in (4,8) 被查询的表列名为: ['序号' '进仓流水号' '到仓库日期' '操作等级' '实际开始日期' '实际完成日期' '计划收货开始日期']
查询:t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16' 被查询的表列名为: ['序号' '进仓流水号' '到仓库日期' '操作等级' '实际开始日期' '实际完成日期' '计划收货开始日期']
查询:t2:Sheet2:Qty == 15 被查询的表列名为: ['报关日期' '返工完成' '反馈日期' 'PostingDate' 'Reference' 'Plant' 'Material' 'Batch'
'StorageType' 'StorageBin' 'Qty' 'Salesunit' 'SLED/BBD' 'Remark' '实际库位'
'Reason' 'Responser' '类型' '小组' '灭菌/非灭菌' '重建RPR' '返工编号']
<email.mime.multipart.MIMEMultipart at 0xecffa58>
第二版系统完整代码编写
文件config.py内容如下,根据自身情况修改配置文件即可:
blacklist = ["aaaa@qq.com", "bbbb@163.com", "ccccc@163.com"]
imapServer = "imap.163.com"
imapuser = 'aaaa@163.com'
imappassword = 'xxxx'
smtpServer = "smtp.qq.com"
smtpuser = "bbb@qq.com"
smtppassword = 'xxxx'
# excel文件标示所对应的文件路径
filenames = {"t1": "t1.xlsx", "t2": "t2.xlsx", "t3": "t3.xlsx"}
# excel文件标示所对应的sheet名列表(整数索引或表单名称)
sheetnames = {"t1": [0], "t2": [0, "Sheet2"], "t3": ["Sheet1"]}
sample = f"""要查询数据,要求邮件主题必须以query开头,邮件内容为纯文本的查询语句。
最新查询语法示例:<pre>
t1::序号 in (4,8)
t1::实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'
t2:Sheet2:Qty == 15
每行表示一个查询规则,每个规则分为三段:文件名、表单名和查询语句,用:分割
一个excel文件中只有一个表单名时,表单名称可以省略。
序号 in (4,8)表示查询序号为4或8的数据,等价写法是 序号==4 or 序号==8
实际开始日期>='2018-05-15' and 实际开始日期<'2018-05-16'表示查询日期为2018-05-15这一天的
Qty == 15表示查询Qty等于15的数据<pre/>
<hr />
"""
app.py完整代码:
#!/usr/bin/env python
# coding: utf-8
import email
import imaplib
import logging
import smtplib
import time
from email.header import Header
from email.header import decode_header
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.utils import formataddr
from email.utils import parseaddr
import pandas as pd
import config
# 建立连接并登陆:
def login_and_select_INBOX():
conn = imaplib.IMAP4(config.imapServer, 143)
conn.login(config.imapuser, config.imappassword)
# 选择收件箱:
conn.select("INBOX")
return conn
# 抓取指定编号的邮件
def fetchmsg(conn, i):
t, data = conn.fetch(i, '(RFC822)')
msg = email.message_from_string(data[0][1].decode("utf-8"))
msg.get_payload(decode=True)
return msg
# 解码函数
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 解析出邮件中的发件人,收件人和主题,
def getinfo(msg):
result = {}
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header == 'Subject':
value = decode_str(value)
else:
hdr, value = parseaddr(value)
name = decode_str(hdr)
if name: result['name'] = name
result[header] = value
return result
# 用于分析邮件内容的编码
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
# 递归解析邮件中的文本内容存储到contentlist中
def parse_msg(msg, contentlist: list):
# 对与多块还需递归调用
if msg.is_multipart():
parts = msg.get_payload()
for part in parts:
parse_msg(part, contentlist)
elif msg.get_content_type() == 'text/plain':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
if content:
contentlist.append(content)
# 将excel全部加载到内存
df_dict = {}
for file, filepath in config.filenames.items():
xlsx = pd.ExcelFile(filepath)
for sheet in config.sheetnames[file]:
df = pd.read_excel(xlsx, sheet)
dfs = df_dict.setdefault(file, {})
dfs[sheet] = df
# 对应文件中sheet不存在则随机返回一张sheet
def findDataFream(file, sheet=None):
if file not in df_dict:
return None
df = df_dict[file]
if sheet not in df:
return list(df.values())[0]
return df[sheet]
# 解决html转义字符的问题:
def unescape(s):
s = s.replace("<", "<")
s = s.replace(">", ">")
s = s.replace("&", "&")
return s
def createQueryDF(content):
content = unescape(content)
se = pd.Series(content.splitlines())
querysdf = se.str.extract(r'(?P<file>.*):(?P<sheet>.*):(?P<query>.*)')
querysdf.dropna(subset=['file', 'query'], inplace=True)
return querysdf
# 查询并构建邮件内容
def buildMessage(querysdf=None):
message = MIMEMultipart()
if querysdf is None:
message.attach(MIMEText(config.sample, 'html', 'utf-8'))
return message
result = []
for i, row in querysdf.iterrows():
querystr = ":".join(row.values.tolist())
df = findDataFream(row.file, row.sheet)
if df is None:
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p><font color='red'>《{row.file}.xlsx》文件不存在</font><hr />")
continue
print(f"查询:{querystr}", "被查询的表列名为:", df.columns.values)
try:
# 每条查询语句最大查询100条数据
data = df.query(row.query).head(100)
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p>")
result.append(data.to_html(index=False))
result.append("<hr />")
# 附件内容
att = MIMEText(data.to_csv(index=False), 'base64', 'utf-8')
att["Content-Type"] = 'application/octet-stream'
att["Content-Disposition"] = f'attachment; filename="{i}.csv"'
message.attach(att)
except Exception as e:
logging.exception(e)
mes = str(e)
result.append(f"<p>查询编号:{i},{querystr},查询结果:</p><p>语法错误:<font color='red'>{mes}</font></p><hr />")
# 邮件正文内容
message.attach(MIMEText(config.sample + "<br />".join(result), 'html', 'utf-8'))
return message
def main():
while 1:
# login
conn = login_and_select_INBOX()
# 获取所有未读邮件的序号
t, data = conn.search(None, 'Recent')
msgList = data[0].split()
for i in msgList:
msg = fetchmsg(conn, i)
result = getinfo(msg)
print(result.get('name', ''), result['From'], result['To'], result['Subject'])
if result['From'] not in config.blacklist: continue
if not result['Subject'].startswith("query"): continue
contentList = []
parse_msg(msg, contentList)
content = "".join(contentList)
if len(content) == 0:
continue
querysdf = createQueryDF(content)
if len(querysdf) == 0: continue
message = buildMessage(querysdf)
smtpObj = smtplib.SMTP_SSL(config.smtpServer, 465)
smtpObj.login(config.smtpuser, config.smtppassword)
message['From'] = formataddr(["数据回复员", config.smtpuser]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
message['To'] = formataddr([result.get('name', ''), result['From']]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
message['Subject'] = Header(f"回复:尊敬的<{result.get('name', '')}>您发送的<{result['Subject']}>结果见邮件", 'utf-8')
smtpObj.sendmail(config.smtpuser, result['From'], message.as_string())
print("邮件发送成功")
smtpObj.close()
conn.close()
conn.logout()
# 每1秒检测一次
time.sleep(1)
main()- END -

你也「在看」吗?????



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











