







关于自动编号的知识可以参考《在 Open XML WordprocessingML 中使用编号列表》
链接:https://learn.microsoft.com/zh-cn/previous-versions/office/ee922775(v=office.14)
python-docx库并不能直接解析出Word文档的自动编号,因为原理较为复杂,但我们希望python能够读取自动编号对应的文本。
基本解析原理
为了测试验证,我们创建一个带有编号的文档进行测试,例如:
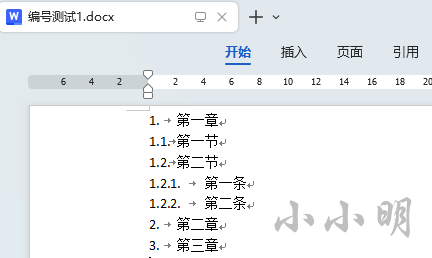
然后我们先看看主文档中,对应的xml存储:
from docx import Document
doc = Document(r"编号测试1.docx")
for paragraph in doc.paragraphs:
print(paragraph._element.xml)
break
结果:
<w:p ...>
<w:pPr>
<w:numPr>
<w:ilvl w:val="0"/>
<w:numId w:val="1"/>
</w:numPr>
<w:bidi w:val="0"/>
<w:ind w:left="0" w:leftChars="0" w:firstLine="0" w:firstLineChars="0"/>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:t>第一章</w:t>
</w:r>
</w:p>
在微软的文档中,说明了最重要的部分:
w:numPr 元素包含自动编号元素。w:ilvl 元素从零开始表示编号等级,w:numId 元素是编号部件的索引。
w:numId 为 0 值时 ,表示编号已经被删除段落不含列表项。
所以我们可以根据段落是否存在w:numPr并且w:numId的值不为0判断段落是否存在自动编号。
然后我们需要获取每个w:numId对应的自动编号状态,这个信息存储在zip压缩包的\word\numbering.xml文件中,可以参考微软文档的示例:
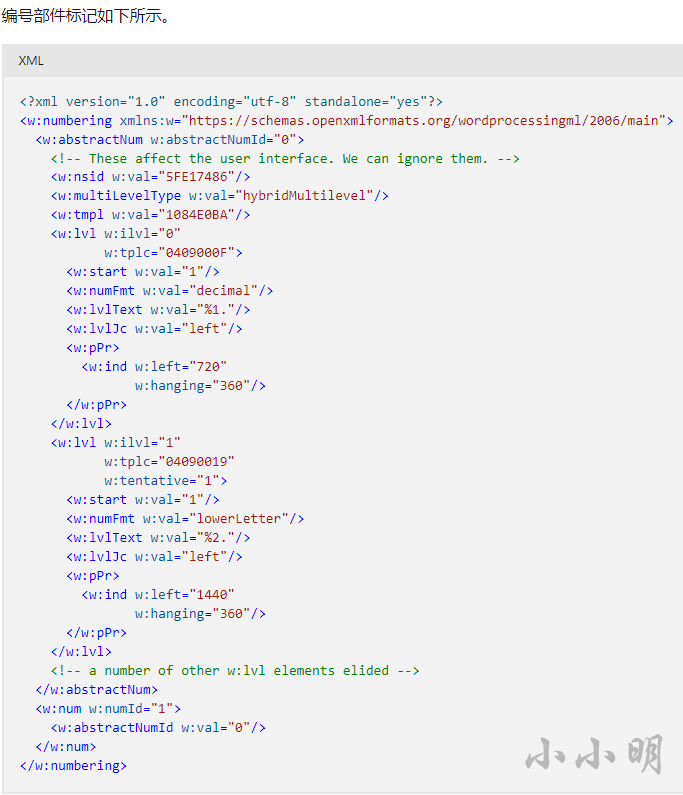
w:numbering同时包含w:num和w:abstractNum两种节点,其中w:num记录了 每个numId对应的abstractNumId,而w:abstractNum记录了每个abstractNumId对应的编号格式,包含了每个级别的编号样式信息。对于w:num,python-docx库已经帮我们解析好,可以直接读取,但w:abstractNum节点python-docx库却并未进行解析,只能我们自己进行xml解析。
可以通过如下代码获取每个numId对应的abstractNumId:
from docx import Document
doc = Document(r"编号测试1.docx")
numbering_part = doc.part.numbering_part._element
numId2abstractId = {
num.numId: num.abstractNumId.val for num in numbering_part.num_lst
}
接下来我们需要解析w:abstractNum节点,查阅python-docx库的源码可以知道,它使用lxml的etree进行xml解析。
初步解析代码为:
from docx.oxml.ns import qn
abstractNumId2style = {
}
for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):
abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))
for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):
ilvl = lvlTag.get(qn("w:ilvl"))
style = {
tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))
for tag in lvlTag.xpath("./*[@w:val]", namespaces=numbering_part.nsmap)}
abstractNumId2style[(int(abstractNumId), int(ilvl))] = style
print(abstractNumId2style)
注意:docx.oxml.ns的qn函数可以将w:转换为对应的命名空间名称,但对于xpath表达式却无法正确处理,所以对于xpath表达式使用namespaces传入对应的命名空间。
除了上面的解析方法以外,还可以事先将节点的所有命名空间清除后再解析,清除代码如下:
def remove_namespace(node): node_tag = node.tag if '}' in node_tag: node.tag = node_tag[node_tag.rfind("}") + 1:] for attr_key in list(node.attrib): if '}' in attr_key: new_attr_key = attr_key[attr_key.rfind("}") + 1:] node.attrib[new_attr_key] = node.attrib.pop(attr_key) for child in node: remove_namespace(child) return node这样可以递归消除目标节点所有子节点的命名空间。
可以每个类别每个级别的自动编号的属性信息:
{(0, 0): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}, (0, 1): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}, (0, 2): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}, (0, 3): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.', 'lvlJc': 'left'}, (0, 4): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.', 'lvlJc': 'left'}, (0, 5): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.', 'lvlJc': 'left'}, (0, 6): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.', 'lvlJc': 'left'}, (0, 7): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.%8.', 'lvlJc': 'left'}, (0, 8): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.%8.%9.', 'lvlJc': 'left'}}
当然我们只测试了最基本的数值型自动编号,有些自动编号对应的节点没有直接的w:numFmt节点,解析代码还需针对性调整。
微软的文档中提到,对多级列表的某一级列表进行特殊设定时,w:num内会出现w:lvlOverride节点,但本人使用wps反复测试过后并没有出现。估计这种格式的xml只会在老版的office中出现,而且我们也不会故意在多级列表的某一级进行特殊设定,所以我们不考虑这种情况。
还需要考虑 w:suff 元素控制的列表后缀,即列表项与段落之间的空白内容,有可能为制表符和空格,也可以什么都没有。处理代码为:
{
"space": " ", "nothing": ""}.get(style.get("suff"), "\t")
多级编号处理
首先尝试读取每个段落对应的自动编号样式:
for paragraph in doc.paragraphs:
numpr = paragraph._element.pPr.numPr
if numpr is not None and numpr.numId.val != 0:
numId = numpr.numId.val
ilvl = numpr.ilvl.val
abstractId = numId2abstractId[numId]
style = abstractNumId2style[(abstractId, ilvl)]
print(style)
print(paragraph.text)
结果:
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第一章
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}
第一节
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}
第二节
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}
第一条
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}
第二条
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第二章
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第三章
我们需要一个计数器来记录每个样式出现的次数,从而生成其对应的编号。
cache = {
}
for paragraph in doc.paragraphs:
numpr = paragraph._element.pPr.numPr
lvlText = ""
if numpr is not None and numpr.numId.val != 0:
numId = numpr.numId.val
ilvl = numpr.ilvl.val
abstractId = numId2abstractId[numId]
style = abstractNumId2style[(abstractId, ilvl)]
if (abstractId, ilvl) in cache:
cache[(abstractId, ilvl)] += 1
else:
cache[(abstractId, ilvl)] = int(style["start"])
lvlText = style.get("lvlText")
for i in range(0, ilvl + 1):
lvlText = lvlText.replace(f'%{
i + 1}', str(cache[(abstractId, i)]))
suff_text = {
"space": " ", "nothing": ""}.get(style.get("suff"), "\t")
lvlText += suff_text
print(lvlText + paragraph.text)
结果:
1. 第一章
1.1. 第一节
1.2. 第二节
1.2.1. 第一条
1.2.2. 第二条
2. 第二章
3. 第三章
各种其他类型的编号生成
为了尽量多的支持更多类型的编号,我创建了如下测试文件:

我们没有必要获取对应的圆圈数字,圆圈就获取对应的整数。
除了三种日文编号,上面的示例几乎包含所有的编号类型。需要注意三位数以上的数字格式,其xml有些特殊,例如:
<w:lvl>
<w:start w:val="1"/>
<mc:AlternateContent>
<mc:Choice Requires="w14">
<w:numFmt w:val="custom" w:format="001, 002, 003, ..."/>
</mc:Choice>
<mc:Fallback>
<w:numFmt w:val="decimal"/>
</mc:Fallback>
</mc:AlternateContent>
<w:suff w:val="space"/>
<w:lvlText w:val="%1"/>
<w:lvlJc w:val="left"/>
<w:pPr>
<w:tabs>
<w:tab w:val="left" w:pos="0"/>
</w:tabs>
</w:pPr>
<w:rPr>
<w:rFonts w:hint="default"/>
</w:rPr>
</w:lvl>
基于此,解析格式的代码也作出如下调整:
abstractNumId2style = {
}
for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):
abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))
for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):
ilvl = lvlTag.get(qn("w:ilvl"))
style = {
tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))
for tag in lvlTag.xpath("./*[@w:val]", namespaces=numbering_part.nsmap)}
if "numFmt" not in style:
numFmtVal = lvlTag 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3339
3339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











