



在先前的第 11 讲中我们提到了一些工程优化技巧,例如缓存机制、多任务并行等。接下来我们分别进行实践。
1. 使用 K-V 缓存
本次实践使用简单的 k-v dict 模拟缓存机制,我们搭建一个从 RAG 系统启动至检索的过程,并设置 kv 字典用于保存检索过的 query 与节点集合,并测试有无缓存机制时系统的检索时间:
milvus_store_conf = {
'type': 'map',
'indices': {
'smart_embedding_index': {
'backend': 'milvus',
'kwargs': {
'uri': "dbs/test_cache.db",
'index_kwargs': {
'index_type': 'HNSW',
'metric_type': 'COSINE',
}
},
},
},
}
dataset_path = os.path.join(DOC_PATH, "test")
docs = lazyllm.Document(
dataset_path=dataset_path,
embed=embedding_model,
store_conf=milvus_store_conf
)
docs.create_node_group(name='sentence', parent="MediumChunk", transform=(lambda d: d.split('。')))
retriever1 = lazyllm.Retriever(docs, group_name="MediumChunk", topk=6, index='smart_embedding_index')
retriever2 = lazyllm.Retriever(docs, group_name="sentence", target="MediumChunk", topk=6, index='smart_embedding_index')
retriever1.start()
retriever2.start()
reranker = Reranker('ModuleReranker', model=rerank_model, topk=3)
# 设置固定query
query = "证券管理的基本规范?"
# 运行5次没有缓存机制的检索流程,并记录时间
time_no_cache = []
for i in range(5):
st = time.time()
nodes1 = retriever1(query=query)
nodes2 = retriever2(query=query)
rerank_nodes = reranker(nodes1 + nodes2, query)
et = time.time()
t = et - st
time_no_cache.append(t)
print(f"No cache 第 {i+1} 次查询耗时:{t}s")
# 定义dict[list],存储已检索的query和节点集合,实现简易的缓存机制
kv_cache = defaultdict(list)
for i in range(5):
st = time.time()
#如果query未在缓存中,则执行正常的检索流程,若query命中缓存,则直接取缓存中的节点集合
if query not in kv_cache:
nodes1 = retriever1(query=query)
nodes2 = retriever2(query=query)
rerank_nodes = reranker(nodes1 + nodes2, query)
# 检索完毕后,缓存query及检索节点
kv_cache[query] = rerank_nodes
else:
rerank_nodes = kv_cache[query]
et = time.time()
t = et - st
time_no_cache.append(t)
print(f"KV cache 第 {i+1} 次查询耗时:{t}s")
以上代码中主要实现了 RAG 系统中的启动和检索环节,对于检索环节,使用字典的形式实现了 kv cache 机制,检索开始时首先会检查当前查询的节点是否已经在缓存当中,如果存在,即为缓存命中,直接取缓存中的查询结果即可,反之则进行正常的检索流程,并在最后将检索结果存入缓存当中。程序运行后得到如下输出:
No cache 第 1 次查询耗时:1.3868563175201416s
No cache 第 2 次查询耗时:1.277320146560669s
No cache 第 3 次查询耗时:1.2744269371032715s
No cache 第 4 次查询耗时:1.3921117782592773s
No cache 第 5 次查询耗时:1.3207831382751465s
KV cache 第 1 次查询耗时:1.4092140197753906s
KV cache 第 2 次查询耗时:2.384185791015625e-07s
KV cache 第 3 次查询耗时:1.430511474609375e-06s
KV cache 第 4 次查询耗时:2.384185791015625e-07s
KV cache 第 5 次查询耗时:2.384185791015625e-07s
可以看到,当系统没有缓存查询结果时,每次查询的时间均在 1 点几秒,而使用缓存的情况下,除了第一次正常检索,其余检索均在瞬间完成,因此,合理设计缓存机制能够在高效的向量索引基础之上进一步提升系统检索性能。
🚨注意:实践的目的主要是为了展示缓存机制对于检索性能的提升,实际生产过程当中,通常会使用内存数据管理系统(如 Redis)实现相关功能。同时,需要考虑多种因素以建立完善的缓存机制。如:
-
文档更新是缓存清理
-
高热 query 的具体定义
-
相似 query 命中
-
...
2. 并行执行,多路召回效率提升
您可以发现,先前多路召回的场景中,检索器依次执行检索,这种流程其实是很低效的。考虑到检索器之间不存在耦合,因此,我们可以使用 LazyLLM 的 Flow 组件中的 parallel 实现检索器的并行多路召回。
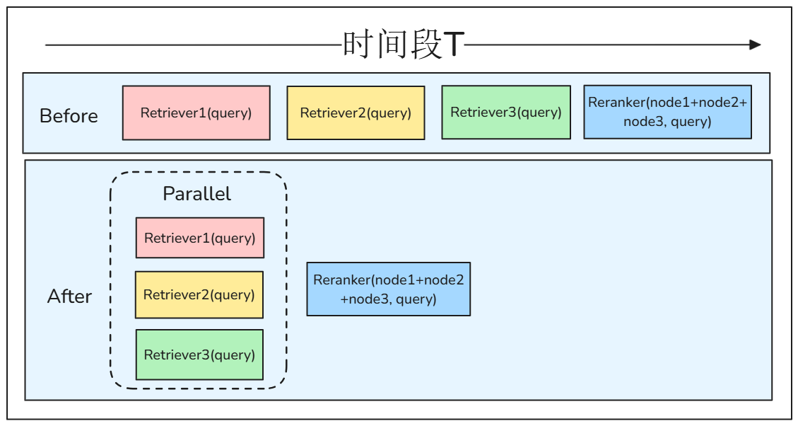
代码如下:
milvus_store_conf = {
'type': 'milvus',
'kwargs': {
'uri': "dbs/test_parallel.db",
'index_kwargs': {
'index_type': 'HNSW',
'metric_type': 'COSINE',
}
}
}
dataset_path = os.path.join(DOC_PATH, "test")
docs1 = lazyllm.Document(
dataset_path=dataset_path,
embed=embedding_model,
store_conf=milvus_store_conf
)
docs1.create_node_group(name='sentence', parent="MediumChunk", transform=(lambda d: d.split('。')))
retriever1 = lazyllm.Retriever(docs1, group_name="MediumChunk", topk=3)
retriever2 = lazyllm.Retriever(docs1, group_name="sentence", target="MediumChunk", topk=3)
retriever1.start()
retriever2.start()
with lazyllm.parallel().sum as prl:
prl.r1 = retriever1
prl.r2 = retriever2
query = "证券管理的基本规范?"
st = time.time()
retriever1(query=query)
retriever2(query=query)
et1 = time.time()
prl(query)
et2 = time.time()
print(f"顺序检索耗时:{et1-st}s")
print(f"并行检索耗时:{et2-et1}s")
执行以上代码获得输出:
顺序检索耗时:0.0436248779296875s
并行检索耗时:0.025980472564697266s
可以看出,使用并行检索可以有效节省检索时间,提升检索效率。最后,我们综合以上所有优化策略实现一个优化效率后的高性能 RAG 系统:
milvus_store_conf = {
'type': 'milvus',
'kwargs': {
'uri': "dbs/test_rag.db",
'index_kwargs': {
'index_type': 'HNSW',
'metric_type': 'COSINE',
}
}
}
dataset_path = os.path.join(DOC_PATH, "test")
# 定义kv缓存
kv_cache = defaultdict(list)
docs1 = lazyllm.Document(dataset_path=dataset_path, embed=embedding_model, store_conf=milvus_store_conf)
docs1.create_node_group(name='sentence', parent="MediumChunk", transform=(lambda d: d.split('。')))
prompt = '你是一个友好的 AI 问答助手,你需要根据给定的上下文和问题提供答案。\
根据以下资料回答问题:\
{context_str} \n '
with lazyllm.pipeline() as recall:
# 并行多路召回
with lazyllm.parallel().sum as recall.prl:
recall.prl.r1 = lazyllm.Retriever(docs1, group_name="MediumChunk", topk=6)
recall.prl.r2 = lazyllm.Retriever(docs1, group_name="sentence", target="MediumChunk", topk=6)
recall.reranker = lazyllm.Reranker(name='ModuleReranker',model=rerank_model, topk=3) | lazyllm.bind(query=recall.input)
recall.cache_save = (lambda nodes, query: (kv_cache.update({query: nodes}) or nodes)) | lazyllm.bind(query=recall.input)
with lazyllm.pipeline() as ppl:
# 缓存检查
ppl.cache_check = lazyllm.ifs(
cond=(lambda query: query in kv_cache),
tpath=(lambda query: kv_cache[query]),
fpath=recall
)
ppl.formatter = (
lambda nodes, query: dict(
context_str="\n".join(node.get_content() for node in nodes),
query=query)
) | lazyllm.bind(query=ppl.input)
ppl.llm = llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extro_keys=['context_str']))
w = lazyllm.WebModule(ppl, port=23492, stream=True).start().wait()
使用 vLLM 框架启动量化模型服务
vLLM 是一个专门为大语言模型(LLM)推理优化的高效推理框架,旨在大幅提升大模型的推理速度,并降低显存占用。它采用了一系列优化技术,如高效的连续批处理(PagedAttention)和动态 KV 缓存管理,使其在 GPU 推理场景下相比传统方法更具优势。
1. 直接启动本地服务
LazyLLM 原生支持了 LightLLM、LMDeploy 和 vLLM 三种大模型推理加速框架和 Infinity 嵌入模型加速框架,用户在使用时仅需通过 TrainableModule.deploy_method 指定对应的框架即可。
from lazyllm import TrainableModule, deploy
llm = TrainableModule('model_name').deploy_method(deploy.vllm)
vLLM 支持多数大模型的推理服务,您可以先确认您想用的模型是否在 LazyLLM 支持的模型列表中。在这个列表中后面带有 AWQ、4bit 等标识的都是量化模型,您可以根据您的需求选择一个量化模型然后启动对话服务,例如:
from lazyllm import TrainableModule, deploy
llm = TrainableModule('Qwen2-72B-Instruct-AWQ').deploy_method(deploy.vllm).start()
print(llm("hello, who are you?"))
我们以 Qwen2-72B-Instruct 和它的 AWQ 量化版本为例,对比一下二者的大小及运行速度。运行 BF16 或 FP16 的 Qwen2-72B-Instruct 模型运行需要至少 144GB 显存(例如 2xA100-80G 或 5xV100-32G);运行 Int4 模型至少需要 48GB 显存(例如 1xA100-80G 或 2xV100-32G),是原来的 33%
(数据来源于 Qwen 官方魔塔社区:
https://modelscope.cn/models/qwen/Qwen-72B/)。
下面我们简单对比一下二者的运行速度,更严谨的情况下可以对比多次执行的差异
(完整代码见 GitHub 链接:
https://github.com/LazyAGI/Tutorial/blob/patch-4/rag/codes/chapter12/use_quantized_llm.py):
import time
from lazyllm import TrainableModule, deploy, launchers
start_time = time.time()
llm = TrainableModule('Qwen2-72B-Instruct').deploy_method(
deploy.Vllm).start()
end_time = time.time()
print("原始模型加载耗时:", end_time-start_time)
start_time = time.time()
llm_awq = TrainableModule('Qwen2-72B-Instruct-AWQ').deploy_method(deploy.Vllm).start()
end_time = time.time()
print("AWQ量化模型加载耗时:", end_time-start_time)
query = "生成一份1000字的人工智能发展相关报告"
start_time = time.time()
llm(query)
end_time = time.time()
print("原始模型耗时:", end_time-start_time)
start_time = time.time()
llm_awq(query)
end_time = time.time()
print("AWQ量化模型耗时:", end_time-start_time)
同样在 4 张 A800 卡加载和执行的速度如下所示:
-
原始模型加载耗时: 129.6051540374756
-
原始模型耗时: 13.104065895080566
-
AWQ 量化模型加载耗时: 86.4980857372284
-
AWQ 量化模型耗时: 8.81701111793518
LazyLLM 输出的日志信息中的 token/s 信息分别为:
-
INFO 03-12 19:52:50 metrics.py:341] Avg prompt throughput: 6.6 tokens/s, Avg generation throughput: 30.8 tokens/s
-
INFO 03-12 20:00:03 metrics.py:341] Avg prompt throughput: 6.6 tokens/s, Avg generation throughput: 41.2 tokens/s
AWQ 模型在单卡上的加载和执行耗时为:137 秒和 23 秒,也就是说,当有 4 张卡的时候,量化模型可以多处理 1.3-1.4 倍的请求。而当用户无法满足执行原模型的资源时,可以通过量化模型获得与原模型效果差异不大的生成效果(官方数据 [https://qwen.readthedocs.io/en/latest/getting_started/speed_benchmark.html] 称量化模型在 MMLU,CEval,IEval 上的评测平均值只差 0.9 个点)。
2. 通过 OnlineChatModule 访问 vLLM API
vLLM 发布的 API 接口和 OpenAI 是一致的,因此我们可以通过 lazyllm.OnlineChatModule 实现接口访问。这种方式的优势是大模型服务与 RAG 系统解耦,重启系统时无需重新启动模型服务,节省模型加载的耗时。
对于 Qwen2-72B-Instruct 模型,直接使用 vLLM 的启动方式为在命令行输入:
vllm serve /path/to/your/model \
--quantization awg_marlin \
--served-model-name qwen2 \
--host 0.0.0.0 \
--port 25120 \
--trust-remote-code
如果您的 vLLM 版本低于 0.5.3,则通过如下命令:
python -m vllm.entrypoints.openai.api_server
--model /path/to/your/model
--served-model-name qwen2 \
--host 0.0.0.0 \
--port 25120
然后我们在 LazyLLM 中访问:
from lazyllm import OnlineChatModule
# 需要抛出环境变量 LAZYLLM_OPENAI_API_KEY 指定服务接口为 openai 模式
# export LAZYLLM_OPENAI_API_KEY=sk...
llm = OnlineChatModule(model="qwen2", base_url="http://127.0.0.1:25120/v1/")
print(llm('hello'))
输出
Hello! How can I assist you today?
这种方式可以有效减少调试过程中频繁重启系统带来的时间消耗,在正式系统重启时也可以和持久化存储一起减少系统的启动时间。如果您想使用自己的 token 进行验证,可以在启动 vLLM 服务时通过传入 --api-key <your-api-key> ,然后在访问时通过设置环境变量 LAZYLLM_OPENAI_API_KEY 完成校验。
此外,如果您自定有了服务接口,您也可以通过继承实现 OnlineChatModuleBase 实现自己的在线对话接口:
import lazyllm
from lazyllm.module import OnlineChatModuleBase
from lazyllm.module.onlineChatModule.fileHandler import FileHandlerBase
class CustomChatModule(OnlineChatModuleBase):
def __init__(self,
base_url: str = "<new platform base url>",
model: str = "<new platform model name>",
system_prompt: str = "<new platform system prompt>",
stream: bool = True,
return_trace: bool = False):
super().__init__(model_type="new_class_name",
api_key=lazyllm.config['new_platform_api_key'],
base_url=base_url,
system_prompt=system_prompt,
stream=stream,
return_trace=return_trace)
3. 基于向量数据库和 vLLM 服务的 RAG 系统
将本篇教程中的所有策略(基于向量数据库的持久化存储和高速向量搜索,vLLM 启动量化推理模型)应用至进阶 1 介绍的多路召回 RAG ,则得到如下代码,在同等条件下,相比于前面的版本启动时间显著减少,响应时间有一定的缩短。
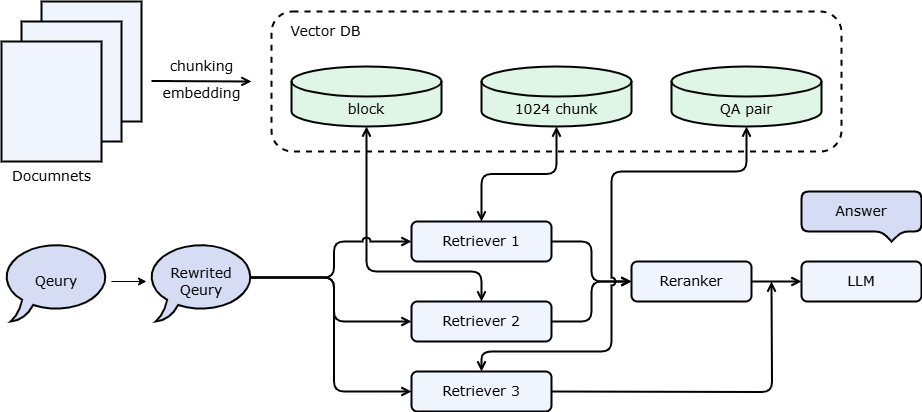
我们在进阶 1 中提到了使用 QA 对的用法并推荐在学习向量数据库后进行调试,这是因为 QA 对提取需要耗费较长的时间和较多的 token,如果每次重启系统都执行一次则会浪费大量时间和 token,但如果使用了持久化存储策略,则可以每次重启系统时的等待时间,结合文档管理接口,您还可以对大模型提取的 QA 对进行调整和删除。
import lazyllm
from lazyllm import bind
# 使用 Milvus 存储后端
chroma_store_conf = {
'type': 'chroma',
'kwargs': {
'dir': 'qa_pair_chromadb',
},
'indices': {
'smart_embedding_index': {
'backend': 'milvus',
'kwargs': {
'uri': "qa_pair/test.db",
'index_kwargs': {
'index_type': 'HNSW',
'metric_type': 'COSINE',
}
},
},
},
}
rewriter_prompt = "你是一个查询重写助手,负责给用户查询进行模板切换。\
注意,你不需要进行回答,只需要对问题进行重写,使更容易进行检索\
下面是一个简单的例子:\
输入:RAG是啥?\
输出:RAG的定义是什么?"
rag_prompt = 'You will play the role of an AI Q&A assistant and complete a dialogue task.'\
' In this task, you need to provide your answer based on the given context and question.'
# 定义嵌入模型和重排序模型
# online_embedding = lazyllm.OnlineEmbeddingModule()
embedding_model = lazyllm.TrainableModule("bge-large-zh-v1.5").start()
# 如果您要使用在线重排模型
# 目前LazyLLM仅支持 qwen和glm 在线重排模型,请指定相应的 API key。
# online_rerank = lazyllm.OnlineEmbeddingModule(type="rerank")
# 本地重排序模型
offline_rerank = lazyllm.TrainableModule('bge-reranker-large').start()
llm = lazyllm.OnlineChatModule(base_url="http://127.0.0.1:36858/v1")
qa_parser = lazyllm.LLMParser(llm, language="zh", task_type="qa")
docs = lazyllm.Document("/path/to/your/document", embed=embedding_model, store_conf=chroma_store_conf)
docs.create_node_group(name='block', transform=(lambda d: d.split('\n')))
docs.create_node_group(name='qapair', transform=qa_parser)
def retrieve_and_rerank():
with lazyllm.pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
# CoarseChunk是LazyLLM默认提供的大小为1024的分块名
ppl.prl.retriever1 = lazyllm.Retriever(doc=docs, group_name="CoarseChunk", index="smart_embedding_index", topk=3)
ppl.prl.retriever2 = lazyllm.Retriever(doc=docs, group_name="block", similarity="bm25_chinese", topk=3)
ppl.reranker = lazyllm.Reranker("ModuleReranker",
model=offline_rerank,
topk=3) | bind(query=ppl.input)
return ppl
with lazyllm.pipeline() as ppl:
# llm.share 表示复用一个大模型,如果这里设置为promptrag_prompt则会覆盖rewrite_prompt
ppl.query_rewriter = llm.share(lazyllm.ChatPrompter(instruction=rewriter_prompt))
with lazyllm.parallel().sum as ppl.prl:
ppl.prl.retrieve_rerank = retrieve_and_rerank()
ppl.prl.qa_retrieve = lazyllm.Retriever(doc=docs, group_name="qapair", index="smart_embedding_index", topk=3)
ppl.formatter = (
lambda nodes, query: dict(
context_str='\n'.join([node.get_content() for node in nodes]),
query=query)
) | bind(query=ppl.input)
ppl.llm = llm.share(lazyllm.ChatPrompter(instruction=rag_prompt, extra_keys=['context_str']))
lazyllm.WebModule(ppl, port=23491, stream=True).start().wait()
基于本节教程内容关于 LazyLLM 如何使用向量数据库实现持久化存储和高速向量检索的相关内容,可以有效减少 RAG 系统在重启和执行阶段的计算耗时,在某些特定节点组的角度还可以节省大量 token 费用。其次,通过灵活使用 vLLM 框架,可以得到更快的推理速度,通过使用量化模型,可以在保留相似的生成效果的条件下,压低硬件要求,节省硬件成本,也可以减少模型启动时的模型加载时间。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









