







介绍
Dejavu可以通过听一次音频并对其进行指纹识别来记住音频。然后,通过播放歌曲并记录麦克风输入或从磁盘读取,Dejavu尝试将音频与数据库中保存的指纹进行匹配,以返回正在播放的歌曲。
注意:对于语音识别,Dejavu不是正确的工具!Dejavu擅长识别具有合理噪声量的精确信号。

工作原理
用Python实现的音频指纹识别和识别算法的工作原理:
音乐作为信号
对于快速傅立叶变换(FFT)的熟悉只是因为它是及时将多项式相乘的一种很酷的方法O(nlog(n))。幸运的是,它在进行信号处理(规范用法)方面要凉得多。
事实证明,音乐被数字编码为一长串数字。在未压缩的.wav文件中,这些数字很多-每个通道每秒44100。这意味着一首3分钟长的歌曲具有将近1600万个样本。
3分钟* 60秒*每秒44100个样本* 2个通道= 15,876,000个样本
声道是扬声器可以播放的单独采样序列。考虑拥有两个耳塞-这是“立体声”或两个通道的设置。单个通道称为“单声道”。如今,现代环绕声系统可以支持更多声道。但是,除非录制声音或使用相同数量的声道进行混合,否则多余的扬声器是多余的,并且某些扬声器将播放与其他扬声器相同的样本流。
采样
为什么每秒44100个样本?每秒选择44100个样本的神秘选择似乎相当随意,但这与Nyquist-Shannon采样定理有关。这是一个很长的数学方法,可以说在录制时我们可以精确捕获的最大频率存在理论上的限制。此最大频率取决于我们对信号采样的速度。
如果这没有意义,请考虑考虑以每秒精确一次(1 Hz)的速率旋转一整圈的风扇叶片。现在想象一下闭上眼睛,但是每秒短暂地睁开一次。如果风扇仍然恰好每1秒钟旋转一整圈,那么看来风扇叶片还没有移动!每次睁开眼睛,刀片恰好都在同一位置。但是有一个问题。实际上,据您所知,风扇叶片每秒可能旋转0、1、2、3、10、100或什至一百万次旋转,而您永远不会知道-它仍然会静止!因此,为了确保您正确地采样(或“看到”)更高的频率(或“旋转”),您需要更频繁地采样(或“睁开眼睛”)。
确切地说,在录制音频的情况下,公认的规则是我们不会错过22050 Hz以上的频率,因为人类甚至听不到20,000 Hz以上的频率。因此,根据奈奎斯特,我们必须采样两次:
每秒需要的样本数=最高频率* 2 = 22050 * 2 = 44100
MP3格式对此进行了压缩,以便1)节省硬盘驱动器上的空间,以及2)刺激发烧友,但是计算机上的纯.wav格式文件只是16位整数(带有小标题)的列表。
频谱图
由于这些样本是某种信号,因此我们可以在歌曲样本中的一小段时间窗口内重复使用FFT来创建歌曲的声谱图。这是罗宾·锡克(Robin Thicke)的“模糊线”的前几秒钟的频谱图。
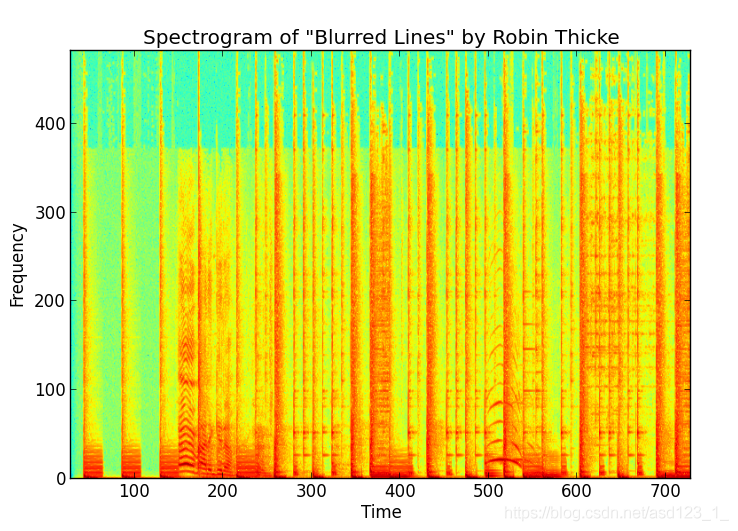
如您所见,它只是一个2D数组,其幅度是时间和频率的函数。FFT向我们显示了该特定频率下信号的强度(幅度),从而显示了一个列。如果使用FFT的滑动窗口执行足够的次数,则将它们放在一起并获得2D阵列频谱图。
重要的是要注意,频率和时间值是离散的,每个代表一个“ bin”,而幅度是实际值。颜色显示离散(时间,频率)坐标处振幅的实值(红色->较高,绿色->较低)。
作为一项思想实验,如果我们记录并创建单个音调的声谱图,我们会在音调的频率上得到一条水平的直线。这是因为频率在窗口之间没有变化。
那么,这如何帮助我们识别音频?好吧,我们想用这张声谱图来唯一地识别这首歌。问题是,如果您的手机中装有手机,并且尝试在收音机中识别这首歌,则会产生噪音-有人在后台讲话,另一辆汽车鸣喇叭,等等。我们必须找到可靠的声音从音频信号捕获独特“指纹”的方法。
寻峰
现在我们已经获得了音频信号的频谱图,我们可以从找到幅度的“峰值”开始。我们将一个峰定义为一个(时间,频率)对,它对应于在其周围的局部“邻域”中最大的振幅值。其周围的其他(时间,频率)对幅度较低,因此不太可能承受噪声。
寻找峰顶本身就是一个完整的问题。我最终将频谱图视为图像,并使用图像处理工具包和中的技术scipy来查找峰。高通滤波器(强调高振幅)和scipy局部最大值结构的组合可以解决问题。
提取了这些抗噪峰值后,我们便在歌曲中找到了感兴趣的点,从而将其识别出来。找到峰值后,我们就可以有效地“压缩”频谱图。振幅已达到其目的,不再需要。
让我们对它们进行绘图以查看其外观:
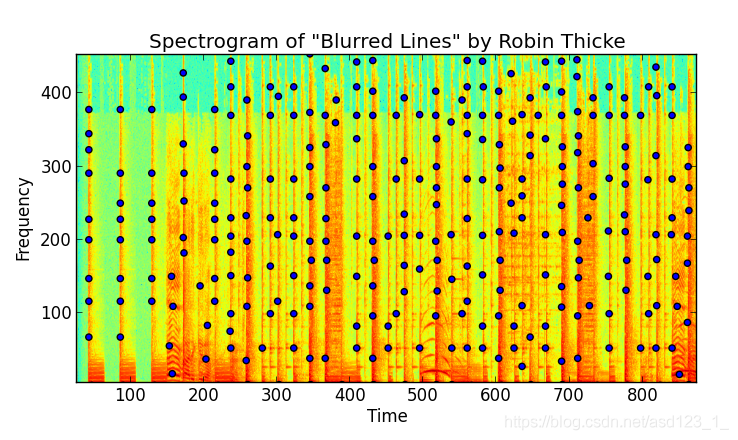
您会注意到其中有很多。实际上,每首歌曲成千上万。令人高兴的是,由于我们已经消除了振幅,因此只有时间和频率两件事,我们很方便地将它们制成离散的整数值。本质上,我们已经将它们分类。
我们有一个精神分裂症的情况:一方面,我们有一个系统将信号的峰值分成离散的(时间,频率)对,这给我们留出了一些余地来抵抗噪声。另一方面,由于我们已经离散化了,所以我们将峰的信息从无限减小为有限,这意味着在一首歌中发现的峰可能会(提示:将要!)发生碰撞,从而将这些对作为从其他歌曲中提取的峰发出。 。不同的歌曲可以而且很可能会发出相同的峰值!所以现在怎么办?
指纹哈希
因此,我们可能会有类似的高峰。没问题,让我们将峰合并为指纹!我们将使用哈希函数来完成此操作。
甲散列函数需要一个整数输入,并返回另一个整数作为输出。这样做的好处是,一个好的哈希函数不仅会在每次输入相同时返回相同的输出整数,而且很少会有不同的输入具有相同的输出。
通过查看频谱图峰值并将峰值频率及其之间的时间差结合起来,我们可以创建一个散列,表示这首歌的唯一指纹。
hash(frequencies of peaks, time difference between peaks) = fingerprint hash value
有许多不同的方法可以执行此操作,Shazam有自己的方法,SoundHound还有其他方法,依此类推。您可以细读我的资料来看看我是怎么做的,但要点是,通过考虑多个峰而不是单个峰,可以创建具有更多熵的指纹,从而包含更多信息。因此它们是歌曲的更强大的标识符,因为它们的冲突较少。
您可以通过以下放大的可视化频谱图来可视化发生的情况:
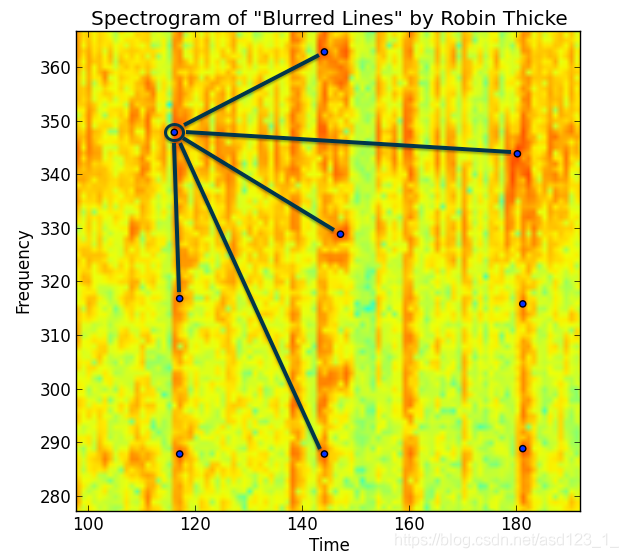
Shazam白皮书将这些峰值组比作一种用于识别歌曲的峰值“星座”。实际上,它们使用峰对以及两者之间的时间增量。您可以想象出许多不同的方式来对点和指纹进行分组。一方面,指纹中的峰越多,意味着越稀有的指纹会更强烈地识别歌曲。但是,更多的峰值也意味着面对噪声时的鲁棒性较差。
学习一首歌
现在我们可以开始了解这种系统的工作原理。音频指纹系统有两个任务:
-
通过指纹学习新歌曲
-
通过在学习的歌曲数据库中搜索来识别未知歌曲
为此,我们将利用到目前为止的知识以及MySQL来实现数据库功能。我们的数据库架构将包含两个表:
-
指纹
-
歌曲
指纹表
指纹表将具有以下字段:
CREATE TABLE fingerprints ( hash binary(10) not null, song_id mediumint unsigned not null, offset int unsigned not null, INDEX(hash), UNIQUE(song_id, offset, hash));
首先,请注意,我们不仅具有哈希和歌曲ID,而且具有偏移量。这对应于来自哈希的频谱图的时间窗口。当我们需要过滤匹配的哈希值时,这将起作用。只有“对齐”的散列将来自我们要识别的真实信号(有关更多信息,请参见下面的“指纹对齐”部分)。
其次,我们INDEX有充分的理由对哈希表进行了处理。所有查询都需要对此进行匹配,因此我们需要在那里进行快速检索。
接下来,UNIQUE索引只是确保我们没有重复项。无需因重复放置而浪费空间或不适当地调整音频重量。
如果您不明白为什么要使用一个binary(10)字段作为哈希值,那么原因是我们将拥有很多这些哈希值,并且必须减少空间。以下是每首歌曲的指纹数量图表:
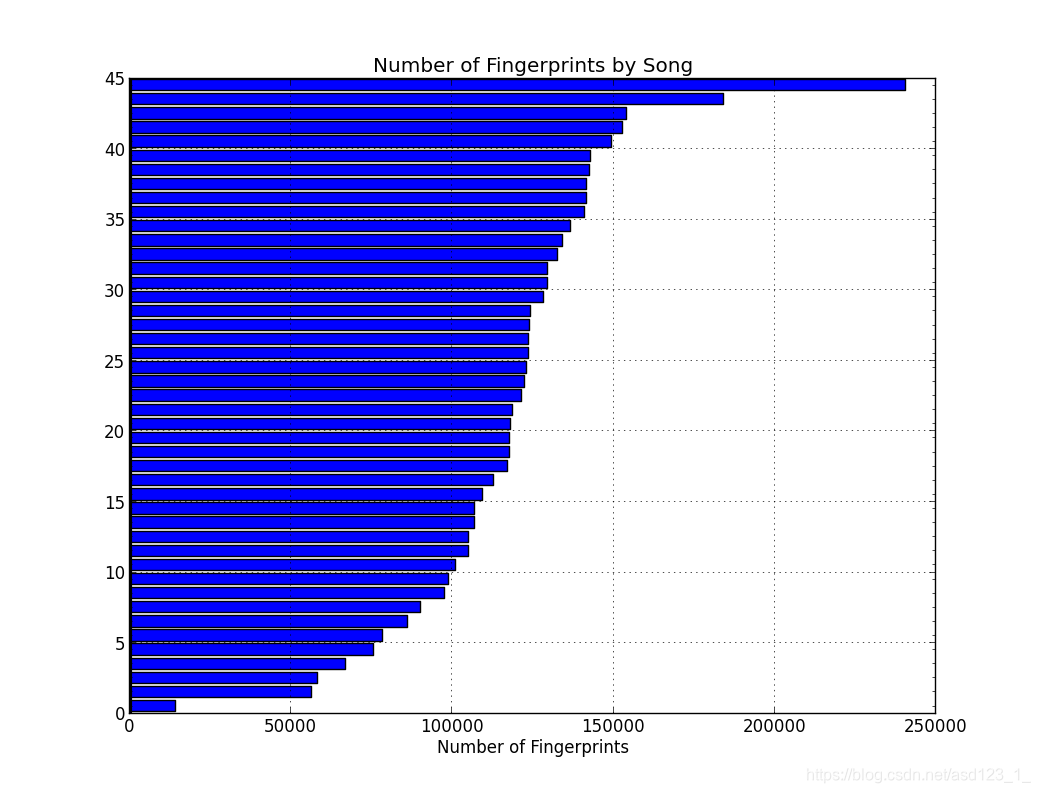
排在最前面的是贾斯汀·汀布莱克(Justin Timberlake)的“镜子”,具有超过24万个指纹,紧随其后的是罗宾·锡克(Robin Thicke)的“模糊线”,具有180k。底部是无伴奏合唱“ Cups”,这是一首稀疏的歌曲-只是声音,实际上是一杯。根据合同,听“镜子”。您会注意到明显的“噪音墙”仪器,并从高到低排列了频谱,这意味着频谱图在高频和低频中都有很多峰值。该数据集的平均值为每首歌曲超过10万个指纹。
有了这么多指纹,我们需要从哈希值级别上减少不必要的磁盘存储。对于我们的指纹哈希,我们将从使用SHA-1哈希开始,然后将其缩减到其大小的一半(仅前20个字符)。这将每个哈希的字节使用量减少了一半:
char(40)=> char(20)从40字节变为20字节
接下来,我们将采用这种十六进制编码,并将其转换为二进制,再次大幅缩减空间:
char(20)=> binary(10)从20字节变为10字节
好多了。我们从该hash字段的320位降低到80位,减少了75%。
我第一次尝试该系统时,我char(40)为每个哈希使用了一个字段-仅指纹就产生了超过1 GB的空间。通过使用binary(10)字段,我们将表的大小缩减为377 MB,可存储520万个指纹。
我们确实会丢失一些信息-从统计学上讲,我们的哈希值现在会更加频繁地发生冲突。我们已大大降低了哈希的“熵”。但是,重要的是要记住,我们的熵(或信息)还包括offset4字节的字段。这使我们每个指纹的总熵达到:
10字节(哈希)+ 4字节(偏移)= 14字节= 112位= 2 ^ 112?= 5.2 + e33可能的指纹
不是太寒酸。我们已经节省了75%的空间,但仍然设法拥有难以想象的大指纹空间。关于密钥分配的保证是很难做出的,但是我们当然有足够的熵来解决。
歌曲表
歌曲表将非常漂亮,基本上,我们将使用它来保存有关歌曲的信息。我们需要它来将asong_id与歌曲的字符串名称配对。
CREATE TABLE songs ( song_id mediumint unsigned not null auto_increment, song_name varchar(250) not null, fingerprinted tinyint default 0, PRIMARY KEY (song_id), UNIQUE KEY song_id (song_id));
fingerprinted Dejavu在内部使用该标志来决定是否对文件进行指纹打印。我们最初将位设置为0,只有在指纹识别过程(通常是两个通道)完成后才将其设置为1。
指纹对准
太好了,所以现在我们聆听了一个音轨,在歌曲长度上的重叠窗口中执行了FFT,提取了峰值并形成了指纹。怎么办?
假设我们已经在已知轨道上执行了这种指纹识别,即我们已经将指纹插入到标有歌曲ID的数据库中,那么我们可以简单地进行匹配。
我们的伪代码如下所示:
channels = capture_audio() fingerprints_matching = [ ] for channel_samples in channels hashes = process_audio(channel_samples) fingerprints_matching += find_database_matches(hashes) predicted_song = align_matches(fingerprints_matching)
哈希对齐是什么意思?让我们考虑一下我们正在作为原始音轨的一部分收听的样本。一旦我们做到这一点,我们哈希提取样品出来都会有一个offset是相对于样品的开始。
当然,问题在于,当我们最初进行指纹识别时,我们记录了哈希的绝对偏移量。除非我们从歌曲的开头就开始记录样本,否则样本中的相对哈希值与数据库中的绝对哈希值将永远不会匹配。不太可能。
但是尽管它们可能并不相同,但我们确实从噪声背后的真实信号中了解了一些匹配信息。我们知道所有相对偏移量将相距相同的距离。这就需要假设以与录音室中录制和发行的相同速度来播放和采样曲目。实际上,在回放速度不同的情况下,无论如何我们还是不走运,因为这会影响回放的频率,从而影响频谱图中的峰值。无论如何,回放速度假设是一个好(也是重要的)假设。
在此假设下,对于每个匹配项,我们计算偏移量之间的差:
差异=与原始轨道的数据库偏移-与记录的样本偏移
因为数据库跟踪将始终至少为样本的长度,所以它将始终产生一个正整数。具有的所有真实匹配都具有相同的差异。因此,我们从数据库中获得的匹配将更改为:
(song_id,不同)
现在,我们只需查看所有匹配项并预测差异最大的歌曲ID。如果将其可视化为直方图,这很容易想象。
这就是全部!
效果如何
为了真正获得音频指纹识别系统的好处,指纹识别不会花费很长时间。这是糟糕的用户体验,此外,用户可能只决定尝试在广播电台转播到商业广告之前,只用剩下的几秒钟宝贵的音频来匹配歌曲。
为了测试Dejavu的速度和准确性,我从2013年7月开始对美国VA Top 40中的45首歌曲列表进行了指纹识别(我知道,它们的计数不在某个地方)。我通过三种方式进行了测试:
-
从磁盘读取原始mp3-> wav数据,然后
-
在扬声器上播放歌曲,同时Dejavu在笔记本电脑的麦克风上收听。
-
在iPhone上播放的压缩流音乐
以下是结果。
1.从磁盘读取
从磁盘读取是令人难以置信的100%回想-我指纹识别的45首歌曲没有出错。由于Dejavu从歌曲中获取了所有样本(没有杂音),如果每次都无法从磁盘读取同一文件,这将是令人讨厌的惊喜!
2.笔记本电脑麦克风上的音频
在这里,我编写了一个脚本,n从原始mp3文件中随机选择几秒钟的音频来播放,并让Dejavu通过麦克风收听。为了公平起见,我只允许从曲目的开始/结束起超过10秒的音频段,以避免听静音。
另外,我的朋友甚至在说话,我在整个过程中都在嗡嗡作响,只是为了发出一些声音。
以下是收听时间(n)的不同值的结果:
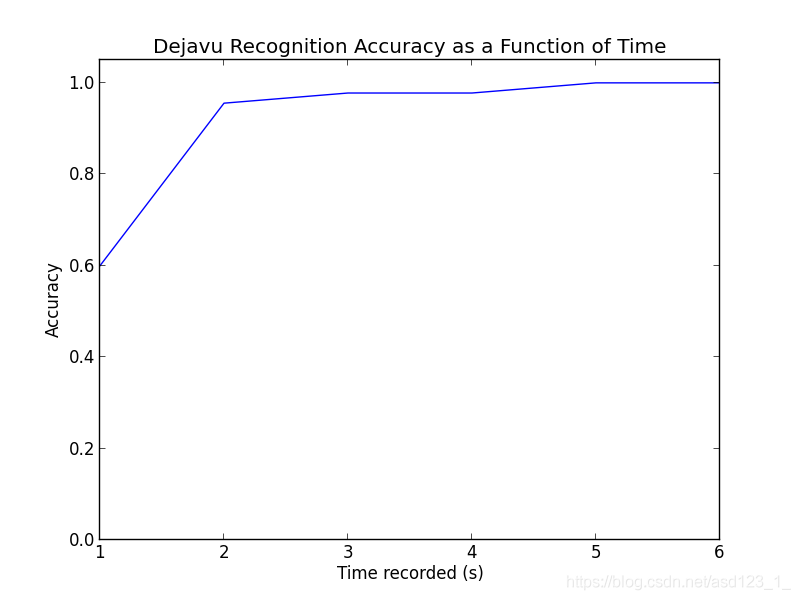
这很不错。对于百分比:
秒数号码正确百分比精度
1个27/4560.0%
243/4595.6%
344/4597.8%
444/4597.8%
545/45100.0%
645/45100.0%
即使只有一秒钟,从歌曲中的任意位置随机选择,Dejavu也能获得60%的收益!一秒钟到2秒的时间使我们达到96%左右,而达到完美只花了5秒或更长时间。老实说,当我自己测试时,我发现Dejavu击败了我-仅听一首1-2秒的上下文歌曲很难识别。调试时,我什至连续两天都在听这些相同的歌曲……
总而言之,Dejavu的工作非常出色,即使几乎没有工作可做。
3.在我的iPhone上播放的压缩流音乐
为了进行测试,我尝试通过iPhone的扬声器通过Spotify帐户(压缩后的160 kbit / s)播放音乐,让Dejavu再次收听MacBook麦克风。我没有发现性能下降;1-2秒足以识别任何歌曲。
性能:速度
在我的MacBook Pro上,匹配以3倍的收听速度完成,并且开销很小。为了测试,我尝试了不同的记录时间,并绘制了记录时间和匹配时间。由于速度很大程度上取决于特定歌曲的速度,并且更多地取决于所创建频谱图的长度,因此我测试了Daft Punk的单首歌曲“ Get Lucky”:
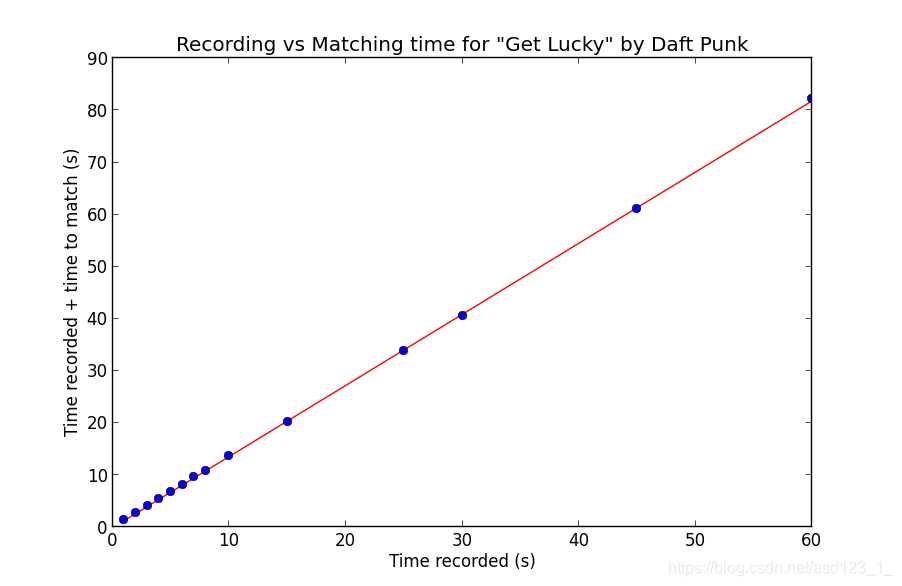
如您所见,该关系是线性的。您看到的线是对数据的最小二乘线性回归,并带有相应的线方程:
1.364757 *记录时间-0.034373 =匹配时间
当然要注意,因为匹配本身是单线程的,所以匹配时间包括记录时间。完全匹配时,将3倍速度设为合理是这样的:
1(记录)+ 1/3(匹配)= 4/3?= 1.364757
如果我们忽略微小的常数项。
峰值查找的开销是瓶颈-我尝试了多线程和实时匹配,可惜,这并不是在Python中实现的。等效的Java或C / C ++实现很可能不会遇到麻烦,可以实时应用FFT和峰值查找。
当然,重要的警告是进行比赛的往返时间(RTT)。由于我的MySQL实例是本地实例,因此无需处理通过空中传输指纹匹配项带来的延迟损失。这会将RTT添加到整个计算中的常数项,但不会影响匹配过程。
性能:存储
对于我指纹识别的45首歌曲,数据库使用了377 MB的空间来存储540万个指纹。相比之下,磁盘使用情况如下:
音频信息类型储存MB
mp3 339
wav 1885
fingerprints 377
在必要的记录时间和所需的存储量之间有一个非常直接的权衡。调整峰值的幅度阈值和指纹识别的扇形值将增加更多的指纹并以更大的空间为代价来提高准确性。
的确,指纹占用了惊人的空间(比原始MP3文件略多)。这似乎令人震惊,直到您认为每首歌曲有成千上万的哈希值。我们已经将波形文件中整个音频信号的纯信息折衷为指纹存储量的20%。我们还在五秒钟内非常可靠地启用了匹配歌曲的功能,因此我们在空间/速度方面的权衡似乎已得到回报。
下载
pip install dejavu
结论
我第一次看到音频指纹似乎很神奇。但是,由于对信号处理和基本数学知识很少,因此这是一个相当容易的领域。















 33
33











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









