









 本文详细解析了Android Room数据库框架的使用流程,包括@Entity、@Dao和@Database注解的作用、用法及注意事项,帮助开发者深入了解Room的工作原理。
本文详细解析了Android Room数据库框架的使用流程,包括@Entity、@Dao和@Database注解的作用、用法及注意事项,帮助开发者深入了解Room的工作原理。
写在前面
官方文档镇楼
首先先摘选官方文档上的讲解,之后针对Room涉及的注解进行阅读分析。
使用 Room 将数据保存到本地数据库
Room 在 SQLite 上提供了一个抽象层,以便在充分利用 SQLite 的强大功能的同时,能够流畅地访问数据库。
处理大量结构化数据的应用可极大地受益于在本地保留这些数据。最常见的用例是缓存相关数据。这样,当设备无法访问网络时,用户仍可在离线状态下浏览相应内容。设备之后重新连接到网络后,用户发起的所有内容更改都会同步到服务器。
声明依赖项
要将其中某个库添加到您的构建中,请在您的顶级 build.gradle 文件中包含 Google 的 Maven 代码库:
allprojects {
repositories {
google()
// If you're using a version of Gradle lower than 4.1, you must instead use:
// maven {
// url 'https://maven.google.com'
// }
// An alternative URL is 'https://dl.google.com/dl/android/maven2/'
}
}
在应用或模块的 build.gradle 文件中添加所需工件的依赖项:
dependencies {
def room_version = "2.2.4"
implementation "androidx.room:room-runtime:$room_version"
annotationProcessor "androidx.room:room-compiler:$room_version" // For Kotlin use kapt instead of annotationProcessor
// optional - Kotlin Extensions and Coroutines support for Room
implementation "androidx.room:room-ktx:$room_version"
// optional - RxJava support for Room
implementation "androidx.room:room-rxjava2:$room_version"
// optional - Guava support for Room, including Optional and ListenableFuture
implementation "androidx.room:room-guava:$room_version"
// Test helpers
testImplementation "androidx.room:room-testing:$room_version"
}
配置编译器选项
Room 具有以下注释处理器选项:
- room.schemaLocation:配置并启用将数据库架构导出到给定目录中的 JSON 文件的功能。如需了解详情,请参阅 Room 迁移。
- room.incremental:启用 Gradle 增量注释处理器。
- room.expandProjection:配置 Room 以重新编写查询,使其顶部星形投影在展开后仅包含 DAO 方法返回类型中定义的列。
以下代码段举例说明了如何配置这些选项:
android {
...
defaultConfig {
...
javaCompileOptions {
annotationProcessorOptions {
arguments = [
"room.schemaLocation":"$projectDir/schemas".toString(),
"room.incremental":"true",
"room.expandProjection":"true"]
}
}
}
}
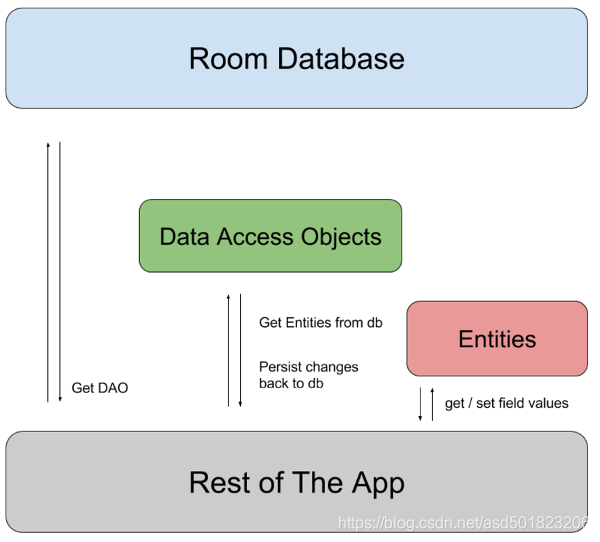
Room 包含 3 个主要组件:
-
数据库:包含数据库持有者,并作为应用已保留的持久关系型数据的底层连接的主要接入点。
使用 @Database 注释的类应满足以下条件:
- 是扩展 RoomDatabase 的抽象类。
- 在注释中添加与数据库关联的实体列表。
- 包含具有 0 个参数且返回使用 @Dao 注释的类的抽象方法。
在运行时,您可以通过调用 Room.databaseBuilder() 或 Room.inMemoryDatabaseBuilder() 获取 Database 的实例。
-
Entity:表示数据库中的表。
-
DAO:包含用于访问数据库的方法。
应用使用 Room 数据库来获取与该数据库关联的数据访问对象 (DAO)。然后,应用使用每个 DAO 从数据库中获取实体,然后再将对这些实体的所有更改保存回数据库中。最后,应用使用实体来获取和设置与数据库中的表列相对应的值。
Room 不同组件之间的关系如图所示:
以下代码段包含具有一个实体和一个 DAO 的示例数据库配置。
@Entity
public class User {
@PrimaryKey
public int uid;
@ColumnInfo(name = "first_name")
public String firstName;
@ColumnInfo(name = "last_name")
public String lastName;
}
@Dao
public interface UserDao {
@Query("SELECT * FROM user")
List<User> getAll();
@Query("SELECT * FROM user WHERE uid IN (:userIds)")
List<User> loadAllByIds(int[] userIds);
@Query("SELECT * FROM user WHERE first_name LIKE :first AND " +
"last_name LIKE :last LIMIT 1")
User findByName(String first, String last);
@Insert
void insertAll(User... users);
@Delete
void delete(User user);
}
@Database(entities = {User.class}, version = 1)
public abstract class AppDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
// 使用
AppDatabase db = Room.databaseBuilder(getApplicationContext(),
AppDatabase.class, "database-name").build();
注意:如果您的应用在单个进程中运行,则在实例化AppDatabase对象时应遵循单例设计模式。每个RoomDatabase实例的成本相当高,而您几乎不需要在单个进程中访问多个实例。
如果您的应用在多个进程中运行,请在数据库构建器调用中包含enableMultiInstanceInvalidation()。这样,如果您在每个进程中都有一个AppDatabase实例,就可以在一个进程中使共享数据库文件失效,并且这种失效会自动传播到其他进程中的 AppDatabase 实例。
源码分析
一.Entity
惯例,按顺序来,首先我们来看一下Entity实体,即@Entity的源码:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.CLASS)
public @interface Entity {
/**
* SQLite数据库的表名,默认值为当前类名
* @return The SQLite tableName of the Entity.
*/
String tableName() default "";
/**
* 表的索引列表
* @return The list of indices on the table.
*/
Index[] indices() default {};
/**
* 如果设置为true,则在父类中定义的所有索引都将被带到当前的Entity。
* 请注意,如果将其设置为true,即使实体的父类中将此值设置为false,
* 实体仍然会从 父类 及 父类的父类 中继承索引
*
* 当Entity从父级继承索引时,它一定会用默认的命名模式重命名,
* 因为SQLite不允许在多个表中使用相同的索引名
*
* 默认情况下,将删除父类中定义的索引,以避免意外的索引。
* 发生这种情况时,您将在编译过程中收到{@link RoomWarnings#INDEX_FROM_PARENT_FIELD_IS_DROPPED}
* 或{@link RoomWarnings#INDEX_FROM_PARENT_IS_DROPPED}警告。
*
* @return True if indices from parent classes should be automatically inherited by this Entity,
* false otherwise. Defaults to false.
*/
boolean inheritSuperIndices() default false;
/**
* 主键列名称列表。
*
* 如果您要定义自动生成的主键,则可以在{@link PrimaryKey#autoGenerate()}设置为true的字段上使用{@link PrimaryKey}批注。
*
* @return The primary key of this Entity. Can be empty if the class has a field annotated
* with {@link PrimaryKey}.
*/
String[] primaryKeys() default {};
/**
* 实体的外键列表
*
* @return The list of {@link ForeignKey} constraints on this entity.
*/
ForeignKey[] foreignKeys() default {};
/**
* Room应该忽略的列名列表。
*
* 通常,您可以使用{@link Ignore},但该方法对于忽略从父级继承的字段很有用。
* {@link Embedded}字段中的列不能单独忽略。
* 要忽略来自继承的{@link Embedded}字段的列,请使用该字段的名称。
*
* @return The list of field names.
*/
String[] ignoredColumns() default {};
}
当你为一个类加上@Entity注解后,即将该类标记为实体,该类将在数据库中具有映射SQLite表。每个实体必须至少有1个主键,即用{@link PrimaryKey}注释的字段,或者可以使用{@link #primaryKeys()}属性来定义主键。
当一个类被标记为实体时,其所有字段都将保留。如果您想排除其某些字段,可以使用{@link Ignore}进行标记。如果字段是transient,则除非使用{@link ColumnInfo},{@ link Embedded}或{@link Relation}进行注释,否则它将被自动忽略。
我们再来看一下Entity中涉及到的几个注解:
1.PrimaryKey
该注解的作用是将实体中的字段标记为主键。如果要定义复合主键,则应使用{@link Entity#primaryKeys()}方法。每个实体都必须声明一个主键,除非它的其中一个父类声明了一个主键。 如果实体及其父类都定义了主键,则子级的主键定义将覆盖父级的主键。
如果在{@link Embedded} 字段上使用{@code PrimaryKey}批注,则从该embedded字段继承的所有列都将成为组合主键(包括其grand children 级字段)。
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.CLASS)
public @interface PrimaryKey {
/**
* true:让SQLite自动生成唯一ID。
* 设置为true时,该字段的SQLite类型相似性应为{@code INTEGER}。
* 如果字段类型为{@code long}或{@code int}(或其类型转换程序将其转换为{@code long}或{@code int}),则{@link Insert}方法将0视为未设置。
* 如果字段的类型为{@link Integer}或{@link Long}(或其TypeConverter将其转换为{@link Integer}或{@link Long}),则{@link Insert}方法将null视为未设置。
*
* @return Whether the primary key should be auto-generated by SQLite or not. Defaults
* to false.
*/
boolean autoGenerate() default false;
}
2.ColumnInfo
该注解允许对与此字段关联的列进行特定的自定义。例如,可以为字段指定列名或更改列的类型。
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.CLASS)
public @interface ColumnInfo {
/**
* 数据库中列的名称。 如果未设置,则默认为字段名称
*
* @return Name of the column in the database.
*/
String name() default INHERIT_FIELD_NAME;
/**
* 列的类型,将在构造数据库时使用。
* 如果未指定,则默认值为{@link #UNDEFINED},Room会根据字段的类型和可用的TypeConverters对其进行解析。
*
* @return The type affinity of the column. This is either {@link #UNDEFINED}, {@link #TEXT},
* {@link #INTEGER}, {@link #REAL}, or {@link #BLOB}.
*
* “ BLOB”类型的相似性曾经被称为“ NONE”。
* 但是该术语很容易与“no affinity”混淆,因此将其重命名。
*/
@SuppressWarnings("unused") @SQLiteTypeAffinity int typeAffinity() default UNDEFINED;
/**
* 索引字段的便捷方法
*
* @return True if this field should be indexed, false otherwise. Defaults to false.
*/
boolean index() default false;
/**
* 列的整理顺序,将在构造数据库时使用。
* 默认值为{@link #UNSPECIFIED}。在这种情况下,Room不会向该列添加任何排序规则序列,而SQLite会将其视为{@link #BINARY}。
*
* @return The collation sequence of the column. This is either {@link #UNSPECIFIED},
* {@link #BINARY}, {@link #NOCASE}, {@link #RTRIM}, {@link #LOCALIZED} or {@link #UNICODE}.
*/
@Collate int collate() default UNSPECIFIED;
/**
* 该列的默认值
* <pre>
* {@literal @}ColumnInfo(defaultValue = "No name")
* public String name;
*
* {@literal @}ColumnInfo(defaultValue = "0")
* public int flag;
* </pre>
* <p>
* 请注意,如果仅使用{@link Insert}插入{@link Entity},将不会使用在此处指定的默认值,而是会使用Java / Kotlin中分配的值。
* 将Query与INSERT语句一起使用,并在此跳过此列,则会使用此默认值。
* </p>
* <p>
* NULL,CURRENT_TIMESTAMP和其他SQLite常量值将被解释为对应的值。
* 如果出于某种原因要将它们用作字符串,请用单引号将它们引起来。
* </p>
* <pre>
* {@literal @}ColumnInfo(defaultValue = "NULL")
* {@literal @}Nullable
* public String description;
*
* {@literal @}ColumnInfo(defaultValue = "'NULL'")
* {@literal @}NonNull
* public String name;
* </pre>
* <p>
* 可以用括号将常量表达式括起来使用
* </p>
* <pre>
* {@literal @}CoumnInfo(defaultValue = "('Created at' || CURRENT_TIMESTAMP)")
* public String notice;
* </pre>
*
* @return The default value for this column.
* @see #VALUE_UNSPECIFIED
*/
String defaultValue() default VALUE_UNSPECIFIED;
/**
* 让Room继承字段名称作为列名称的常量。
* 如果使用,Room将使用字段名称作为列名称。
*/
String INHERIT_FIELD_NAME = "[field-name]";
···
/**
* The SQLite column type constants that can be used in {@link #typeAffinity()}
*/
@IntDef({UNDEFINED, TEXT, INTEGER, REAL, BLOB})
@Retention(RetentionPolicy.CLASS)
@interface SQLiteTypeAffinity {
}
···
@IntDef({UNSPECIFIED, BINARY, NOCASE, RTRIM, LOCALIZED, UNICODE})
@Retention(RetentionPolicy.CLASS)
@interface Collate {
}
/**
* A constant for {@link #defaultValue()} that makes the column to have no default value.
*/
String VALUE_UNSPECIFIED = "[value-unspecified]";
}
3.Index
声明实体上的索引。SQLite索引文档
添加索引通常可以加快SELECT查询的速度,但会减慢INSERT或UPDATE等其他查询的速度。 在添加索引时,请务必小心,以确保值得增加这些额外成本。有两种方法在{@link Entity}中定义索引。 您可以设置{@link ColumnInfo#index()}属性为各个字段建立索引,也可以通过{@link Entity#indices()}定义复合索引。
如果通过{@link Embedded}将索引字段嵌入到另一个实体中,不会将其作为索引添加到包含的{@link Entity}中。 如果要保留它的索引,则必须在包含的{@link Entity}中重新声明它。同样,如果{@link实体}扩展了另一个类,则不会继承超类的索引。 您必须在子{@link Entity}中重新声明它们,或将{@link Entity#inheritSuperIndices()}设置为true。
@Target({})
@Retention(RetentionPolicy.CLASS)
public @interface Index {
/**
* 索引中的列名列表。
* 列的顺序很重要,因为它定义了SQLite何时可以使用特定索引。
*
* @return The list of column names in the Index.
*/
String[] value();
/**
* 索引名称。
* 如果未设置,Room会将其设置为以“ _”连接并以“ index _ $ {tableName}”为前缀的列的列表。
* 因此,如果您有一个名为“ Foo”且索引为{“ bar”,“ baz”}的表,则生成的索引名称将为“ index_Foo_bar_baz”。
* 如果需要在查询中指定索引,不要依赖此名称,应为索引指定名称。
*
* @return The name of the index.
*/
String name() default "";
/**
* 如果设置为true,这将是唯一索引,任何重复项都将被拒绝
*
* @return True if index is unique. False by default.
*/
boolean unique() default false;
}
4.Embedded
标记{@link Entity}或POJO的字段,以允许在SQL查询中直接引用嵌套字段(即带注释字段的类的字段)。如果容器是{@link Entity},则这些子字段将是{@link Entity}的数据库表中的列。
例如以下两个类:
public class Coordinates {
double latitude;
double longitude;
}
public class Address {
String street;
@Embedded
Coordinates coordinates;
}
当将SQLite行映射到Address时,Room会认为latitude和longitude是Address类的字段。因此,如果您有一个返回street,latitude,longitude的查询,Room将正确构造一个Address类。
如果名称与子对象和所有者对象的字段冲突,则可以为子对象的字段指定{@link #prefix()}。请注意,即使子字段具有带有特定name的ColumnInfo,也始终将前缀应用于子字段。如果嵌入字段的子字段具有PrimaryKey注解,在Entity中,它们不会被视为主键。
读取嵌入字段时,如果嵌入字段(及其子字段)的所有字段在{@link android.database.Cursor Cursor}中为null,则将其设置为null,否则将调用构造函数进行实例化。
请注意,即使您有TypeConverter可以将null转换为non-null值,但Cursor为空时不会调用TypeConverter,并且不会构造Embedded字段。
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.CLASS)
public @interface Embedded {
/**
* 指定前缀,以在嵌入字段中添加字段的列名
* <p>
* 例如:
* <pre>
* @Embedded(prefix = "loc_")
* Coordinates coordinates;
* </pre>
* {@code latitude}和{@code longitude}的列名称分别为{@code loc_latitude}和{@code loc_longitude}。
* 默认情况下,prefix是空字符串。
*
* @return The prefix to be used for the fields of the embedded item.
*/
String prefix() default "";
}
5.Relation
可以在POJO中使用来自动获取关系实体的便捷注释。当从查询返回POJO时,Room还将获取其所有关系。
@Entity
public class Song {
@PrimaryKey
int songId;
int albumId;
String name;
// other fields
}
public class AlbumNameAndAllSongs {
int id;
String name;
@Relation(parentColumn = "id", entityColumn = "albumId")
List<Song> songs;
}
@Dao
public interface MusicDao {
@Query("SELECT id, name FROM Album")
List<AlbumNameAndAllSongs> loadAlbumAndSongs();
}
对于一对多或多对多关系,用{@code Relation}注释的字段的类型必须为{@link java.util.List}或{@link java.util.Set}。默认情况下,从返回类型推断出{@link Entity}类型。如果您想返回其他对象,则可以在批注中指定{@link #entity()}属性。
public class Album {
int id;
// other fields
}
public class SongNameAndId {
int songId;
String name;
}
public class AlbumAllSongs {
@Embedded
Album album;
@Relation(parentColumn = "id", entityColumn = "albumId", entity = Song.class)
List<SongNameAndId> songs;
}
@Dao
public interface MusicDao {
@Query("SELECT * from Album")
List<AlbumAllSongs> loadAlbumAndSongs();
在上面的示例中,{@code SongNameAndId}是常规POJO,但是所有字段都是从{@code @Relation}批注(Song.class)中定义的实体中获取的。 {@code SongNameAndId}也可以定义自己的关系,所有这些关系也将自动获取。如果要指定从子{@link实体}提取哪些列,则可以在{@code Relation}批注中使用{@link #projection()}属性。
public class AlbumAndAllSongs {
@Embedded
Album album;
@Relation(
parentColumn = "id",
entityColumn = "albumId",
entity = Song.class,
projection = {"name"})
List<String> songNames;
}
如果关系是由关联表(也称为联结表)定义的,则可以使用{@link #associateBy()}进行指定。 这对于获取多对多关系很有用。请注意,{@ code @Relation}批注只能在POJO类中使用,{@ link Entity}类不能具有relations。 这是一项设计决策,旨在避免在{@link Entity}设置中遇到常见的陷阱。加载数据时,可以通过创建扩展{@link Entity}的POJO类来解决此限制。
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.CLASS)
public @interface Relation {
/**
* 从中获取项目的实体或视图,类似map
* 如果实体或视图与返回类型中的type参数匹配,则无需设置此项
*
* @return The entity or view to fetch from. By default, inherited from the return type.
*/
Class<?> entity() default Object.class;
/**
* 父POJO中的参考列。
* 在一对一或一对多关系中,此值将与{@link #entityColumn()}中定义的列匹配。
* 在多对多使用{@link #associateBy()}的情况下,此值将与{@link Junction#parentColumn()}相匹配
*
* @return The column reference in the parent object.
*/
String parentColumn();
/**
* {@link #entity()}中要匹配的列。
* 在一对一或一对多关系中,此值将与{@link #parentColumn()}中定义的列匹配。
* 在多对多使用{@link #associateBy()}的情况下,此值将与{@link Junction#entityColumn()}相匹配
*/
String entityColumn();
/**
* 在获取相关实体时用作关联表(也称为联结表)的实体或视图
*
* @return The junction describing the associative table. By default, no junction is specified
* and none will be used.
*
* @see Junction
*/
Junction associateBy() default @Junction(Object.class);
/**
* 如果应该从实体中获取子列,则可以使用此字段指定它们
* 默认情况下,从返回类型推断
*
* @return The list of columns to be selected from the {@link #entity()}.
*/
String[] projection() default {};
}
二.DAO
接下来我们来看一下@DAO:
该注解将类标记为数据访问对象。数据访问对象是定义数据库交互的主要类,它们可以包括各种查询方法。
标有{@code @Dao}的类应该是接口或抽象类。 在编译时,{@ link数据库}引用Room时,它将生成该类的实现。抽象的{@code @Dao}类可以有一个构造函数,该构造函数将{@link Database}作为其唯一参数。建议您在代码库中有多个{@code Dao}类,具体取决于它们接触的表。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.CLASS)
public @interface Dao {
}
1.Query
将{@link Dao}注释类中的方法标记为查询方法。注释的值包括将在调用此方法时运行的查询,Room会在编译时验证此查询,以确保可以对数据库进行正确的编译。
Room仅支持命名绑定参数{@code:name},以避免方法参数和查询绑定参数之间的混淆。Room会自动将方法的参数绑定到绑定参数中,这是通过将参数名称与绑定参数名称匹配来完成的。
@Query("SELECT * FROM song WHERE release_year = :year")
public abstract List<Song> findSongsByReleaseYear(int year);
作为对SQLite绑定参数的扩展,Room支持将参数列表绑定到查询。在运行时,Room将根据方法参数中的项目数来构建具有匹配数量的绑定参数的查询。
@Query("SELECT * FROM song WHERE id IN(:songIds)")
public abstract List<Song> findByIds(long[] songIds);
对于上面的示例,如果{@code songIds}是由3个元素组成的数组,Room将以以下方式运行查询:{@code SELECT * FROM song WHERE id IN(?,?,?)}并将绑定项绑定到将{@code songIds}数组放入该语句。这种绑定的一个警告是,只有999项可以绑定到查询,这是SQLite的限制。
{@code Query}方法支持4种类型的语句:SELECT,INSERT,UPDATE和DELETE。
-
对于SELECT查询,Room将根据方法的返回类型推断结果内容,并生成将查询结果自动转换为方法的返回类型的代码。对于单结果查询,返回类型可以是任何数据对象(也称为POJO)。对于返回多个值的查询,可以使用{@link java.util.List}或{@code Array}。
除了这些之外,任何查询都可以返回{@link android.database.Cursor游标},或者任何查询结果都可以包装在{@link androidx.lifecycle.LiveData LiveData}中。 -
INSERT查询可以返回{@code void}或{@code long}。如果它是{@code long},则值是此查询插入的行的SQLite row id。请注意,插入多行的查询不能返回一个以上的row id,因此如果返回{@code long},请避免使用此类语句。
-
UPDATE或DELETE查询可以返回{@code void}或{@code int}。如果它是{@code int},则值是此查询影响的行数。
RxJava:
如果您使用的是RxJava2,则还可以从查询方法返回{@code Flowable }或{@code Publisher }。由于Reactive Streams不允许{@code null},因此如果查询返回可为空的类型,则如果该值为{@code null},则它将不会分派任何内容(例如,获取不存在的{@link Entity}行)。
您可以返回{@code Flowable <T []>}或{@code Flowable <List >}以解决此限制。
{@code Flowable }和{@code Publisher }都将观察数据库中的更改,如果数据更改,则会重新调度。 如果要查询数据库而不观察更改,则可以使用{@code Maybe }或{@code Single }。 如果{@code Single }查询返回{@code null},Room将抛出{@link androidx.room.EmptyResultSetException EmptyResultSetException}。
可以从查询方法中返回任意POJO,只要POJO的字段匹配查询结果中的列名。例如:
class SongDuration {
String name;
@ColumnInfo(name = "duration")
String length;
}
@Query("SELECT name, duration FROM song WHERE id = :songId LIMIT 1")
public abstract SongDuration findSongDuration(int songId);
Room将创建正确的实现,以将查询结果转换为{@code SongDuration}对象。 如果查询结果与POJO的字段不匹配,并且只要至少有1个字段匹配,Room就会打印{@link RoomWarnings#CURSOR_MISMATCH}警告并设置尽可能多的字段。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.CLASS)
public @interface Query {
/**
* The SQLite query to be run.
* @return The query to be run.
*/
String value();
}
2.Insert
将{@link Dao}注释类中的方法标记为insert方法,该方法的实现会将其参数插入数据库。Insert方法的所有参数必须是带有{@link Entity}注释的类或其集合/数组。例如:
@Dao
public interface MusicDao {
@Insert(onConflict = OnConflictStrategy.REPLACE)
public void insertSongs(Song... songs);
@Insert
public void insertBoth(Song song1, Song song2);
@Insert
public void insertAlbumWithSongs(Album album, List<Song> songs);
}
如果目标实体是通过{@link #entity()}指定的,则参数可以是任意POJO类型,这些类型将被解释为部分实体。 例如:
@Entity
public class Playlist {
@PrimaryKey(autoGenerate = true)
long playlistId;
String name;
@Nullable
String description
@ColumnInfo(defaultValue = "normal")
String category;
@ColumnInfo(defaultValue = "CURRENT_TIMESTAMP")
String createdTime;
@ColumnInfo(defaultValue = "CURRENT_TIMESTAMP")
String lastModifiedTime;
}
public class NameAndDescription {
String name;
String description
}
@Dao
public interface PlaylistDao {
@Insert(entity = Playlist.class)
public void insertNewPlaylist(NameAndDescription nameDescription);
}
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.CLASS)
public @interface Insert {
/**
* insert方法的目标实体。
* 声明此属性后,如果参数的类型不同于目标,则将插入方法参数解释为部分实体。 代表实体的POJO类必须包含所有非空字段,且没有目标实体的默认值。
* 如果目标实体包含自动生成的{@link PrimaryKey},则POJO类不需要相等的主键字段,否则主键也必须存在于POJO中。
* 默认情况下,目标实体由方法参数解释。
*
* @return the target entity of the insert method or none if the method should use the
* parameter type entities.
*/
Class<?> entity() default Object.class;
/**
* 如果发生冲突该怎么办。
* 使用{@link OnConflictStrategy#ABORT}(默认)在发生冲突时回滚事务。
* 使用{@link OnConflictStrategy#REPLACE}将现有行替换为新行。
* 使用{@link OnConflictStrategy#IGNORE}保留现有行。
*
* @return How to handle conflicts. Defaults to {@link OnConflictStrategy#ABORT}.
*/
@OnConflictStrategy
int onConflict() default OnConflictStrategy.ABORT;
}
3.Update
将{@link Dao}注释类中的方法标记为更新方法。该方法的实现会通过主键去检查数据库中的各参数(如果它们已经存在)并更新。如果它们尚不存在,则此选项将不会更改数据库。
Update方法的所有参数必须是带有{@link Entity}注释的类,或者是其集合/数组。例如:
@Dao
public interface MusicDao {
@Update
public void updateSong(Song);
@Update
public int updateSongs(List<Song> songs);
}
如果目标实体是通过{@link #entity()}指定的,则参数可以是任意POJO类型,这些类型将被解释为部分实体。 例如:
@Entity
public class Playlist {
@PrimaryKey(autoGenerate = true)
long playlistId;
String name;
@ColumnInfo(defaultValue = "")
String description
@ColumnInfo(defaultValue = "normal")
String category;
@ColumnInfo(defaultValue = "CURRENT_TIMESTAMP")
String createdTime;
@ColumnInfo(defaultValue = "CURRENT_TIMESTAMP")
String lastModifiedTime;
}
public class PlaylistCategory {
long playlistId;
String category;
String lastModifiedTime
}
@Dao
public interface PlaylistDao {
@Update(entity = Playlist.class)
public void updateCategory(PlaylistCategory... category);
}
@Retention(RetentionPolicy.CLASS)
public @interface Update {
/**
* 更新方法的目标实体。
* 声明此参数后,如果参数的类型不同于目标,则将更新方法参数解释为部分实体。 代表实体的POJO类必须包含目标实体的字段的子集及其主键。
* 如果找到具有相同主键的实体,则仅更新由部分实体字段表示的列。
* 默认情况下,目标实体由方法参数解释。
*
* @return the target entity of the update method or none if the method should use the
* parameter type entities.
*/
Class<?> entity() default Object.class;
/**
* 如果发生冲突该怎么办。
* 使用{@link OnConflictStrategy#ABORT}(默认)在发生冲突时回滚事务。
* 使用{@link OnConflictStrategy#REPLACE}将现有行替换为新行。
* 使用{@link OnConflictStrategy#IGNORE}保留现有行。
*
* @return How to handle conflicts. Defaults to {@link OnConflictStrategy#ABORT}.
*/
@OnConflictStrategy
int onConflict() default OnConflictStrategy.ABORT;
}
4.Delete
将{@link Dao}注释类中的方法标记为删除方法,该方法的实现将从数据库中删除其参数。Delete方法的所有参数必须是带有{@link Entity}注释的类或该类的集合/数组。例如:
@Dao
public interface MusicDao {
@Delete
public void deleteSongs(Song... songs);
@Delete
public void deleteAlbumAndSongs(Album album, List<Song> songs);
}
如果目标实体是通过{@link #entity()}指定的,则参数可以是任意POJO类型,这些类型将被解释为部分实体。 例如:
@Entity
public class Playlist {
@PrimaryKey
long playlistId;
long ownerId;
String name;
@ColumnInfo(defaultValue = "normal")
String category;
}
public class OwnerIdAndCategory {
long ownerId;
String category;
}
@Dao
public interface PlaylistDao {
@Delete(entity = Playlist.class)
public void deleteByOwnerIdAndCategory(OwnerIdAndCategory... idCategory);
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.CLASS)
public @interface Delete {
/**
* delete方法的目标实体。
* 声明此参数后,当参数的类型不同于目标时,将delete方法参数解释为部分实体。
* 表示实体的POJO类必须包含目标实体的字段的子集。字段值将用于查找要删除的匹配实体。
* 默认情况下,目标实体由方法参数解释。
*
* @return the target entity of the delete method or none if the method should use the
* parameter type entities.
*/
Class<?> entity() default Object.class;
}
三.Database
将一个类标记为RoomDatabase,该类应为抽象类,并扩展{@link androidx.room.RoomDatabase RoomDatabase}。可以通过{@link androidx.room.Room#databaseBuilder Room.databaseBuilder}或者
{@link androidx.room.Room#inMemoryDatabaseBuilder Room.inMemoryDatabaseBuilder}接收该类的实现。
// Song and Album are classes annotated with @Entity.
@Database(version = 1, entities = {Song.class, Album.class})
abstract class MusicDatabase extends RoomDatabase {
// SongDao is a class annotated with @Dao.
abstract public SongDao getSongDao();
// AlbumDao is a class annotated with @Dao.
abstract public ArtistDao getArtistDao();
// SongAlbumDao is a class annotated with @Dao.
abstract public SongAlbumDao getSongAlbumDao();
}
上面的示例定义了一个类,该类具有2个表和3个DAO类用于访问它。 {@link Entity}或{@link Dao}类的数量没有限制,但是它们在数据库中必须唯一。强烈建议您创建{@link Dao}类,而不是直接在数据库上运行查询。使用Dao类将使您可以在一个更具逻辑性的层中抽象化数据库通信,与测试直接SQL查询相比,该层将更易于模拟测试。它还会自动完成从{@code Cursor}到应用程序数据类的转换,因此您无需为大多数数据访问处理低级数据库API。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.CLASS)
public @interface Database {
/**
* 数据库中包含的实体列表
* 每个实体都变成数据库中的一个表
*
* @return The list of entities in the database.
*/
Class<?>[] entities();
/**
* 数据库中包含的数据库视图列表。 每个类都变成数据库中的一个视图
*
* @return The list of database views.
*/
Class<?>[] views() default {};
/**
* The database version.
*
* @return The database version.
*/
int version();
/**
* 您可以设置注释处理器参数({@code room.schemaLocation})来指示Room将数据库模式导出到文件夹中。
* 尽管不是强制性的,但在代码库中拥有模式的版本历史记录是一个好习惯,并且您应该将模式文件提交到版本控制系统中(但不要随应用程序一起提供!)
*
* 设置{@code room.schemaLocation}时,Room将检查此变量,如果将其设置为true,则数据库架构将导出到给定的文件夹中。
*
* {@code exportSchema}在默认情况下为true,但是当您不想保留版本历史记录(例如仅内存数据库)时,可以将其禁用。
*
* @return Whether the schema should be exported to the given folder when the
* {@code room.schemaLocation} argument is set. Defaults to {@code true}.
*/
boolean exportSchema() default true;
}
写在后面
其实这篇文章不能算是源码解读,只是顺着Room的使用流程读了一遍这些注解的作用、用法、注意事项,让大家对Room有一个更加详细的认识。笔者能力有限,目前先写到这里,有时间再回来填坑。
如果文章中有错误的地方,希望各位大佬们批评指正~
If you like this article, it is written by Johnny Deng.
If not, I don’t know who wrote it.

















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









