







在VMWare中构建第二、三台运行Ubuntu的机器和构建第一台机器完全一样,再次不在赘述。。
与安装第一台Ubuntu机器不同的几点是:
第一点:我们把第二、三台Ubuntu机器命名为了Slave1、Slave2,如下图所示:
创建完的VMware中就有三台虚拟机了:

第二点:为了简化Hadoop的配置,保持最小化的Hadoop集群,在构建第二、三台机器的时候使用相同的root超级用户的方式登录系统。
2.按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器;
按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器和配置第一台机器完全相同,
下图是家林完全安装好后的截图:

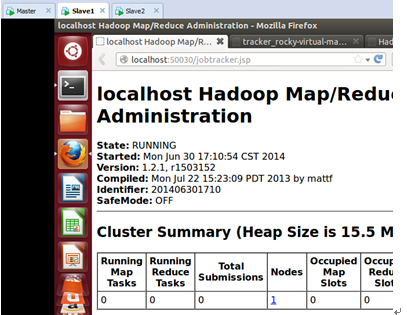
3. 配置Hadoop分布式集群环境;
根据前面的配置,我们现在已经有三台运行在VMware中装有Ubuntu系统的机器,分别是:Master、Slave1、Slave2;
下面开始配置Hadoop分布式集群环境:
Step 1:在/etc/hostname中修改主机名并在/etc/hosts中配置主机名和IP地址的对应关系:
我们把Master这台机器作为Hadoop的主节点,首先看一下Master这台机器的IP地址:

可以看到当前主机的ip地址是“192.168.184.133”.
我们在/etc/hostname中修改主机名:

进入配置文件:

可以看到按照我们装Ubuntu系统时候的默认名称,配置文件中的机器的名称是” rocky-virtual-machine”,我们把” rocky-virtual-machine”改为“Master”作为Hadoop分布式集群环境的主节点:

保存退出。此时使用以下命令查看当前主机的主机名:

发现修改的主机名没有生效,为使得新修改的主机名生效,我们重新启动系统后再次查看主机名:
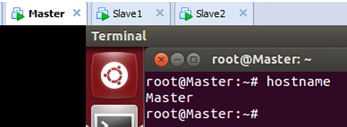
发现我们的主机名成为了修改后的“Master”,表明修改成功。
打开在/etc/hosts 文件:

此时我们发现文件中只有Ubuntu系统的原始ip(127.0.0.1)地址和主机名(localhost)的对应关系:
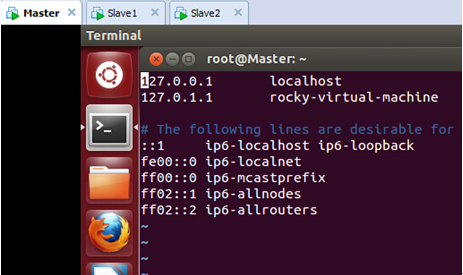
我们在/etc/hosts中配置主机名和IP地址的对应关系:

修改之后保存退出。
接下来我们使用“ping”命令看一下主机名和IP地址只见的转换关系是否正确:

可以看到此时我们的主机“Master”对应的IP地址是“192.168.184.133”,这表明我们的配置和运行都是正确的。
进入第二台机器,看一下这台主机的IP地址:
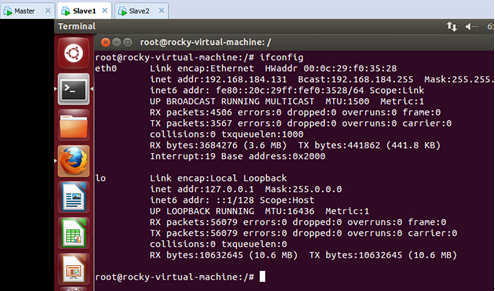
可以看出这台主机的IP地址是“192.168.184.131”.
我们在/etc/hostname中把主机名称修改为“Slave1”:
保存退出。
为了使修改生效,我们重新启动该机器,此时查看主机名:

表明我们的修改生效了。
进入第三台机器,看一下这台主机的IP地址:

可以看出这台主机的IP地址是“192.168.184.132”.
我们在/etc/hostname中把主机名称修改为“Slave2”

保存退出。
为了使修改生效,我们重新启动该机器,此时查看主机名:

表明我们的修改生效了。
现在, Slave1上的/etc/hosts中配置主机名和IP地址的对应关系,打开后:

此时我们修改为配置文件为:

把“Master”和“Slave1”和“Slave2”的主机名和IP地址的对应关系都配置进去。保存退出。
我们此时ping一下Master这个节点发现网络访问没有问题:

接着,在 Slave2上的/etc/hosts中配置主机名和IP地址的对应关系,配置完后如下:
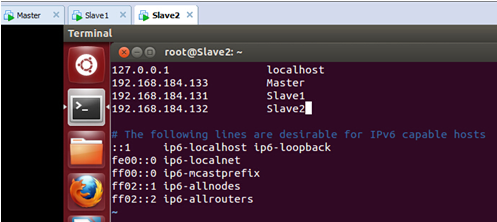
保存退出。
此时我们ping一下Master和Slave1发现都可以ping通;
最后把在 Master上的/etc/hosts中配置主机名和IP地址的对应关系,配置完后如下:
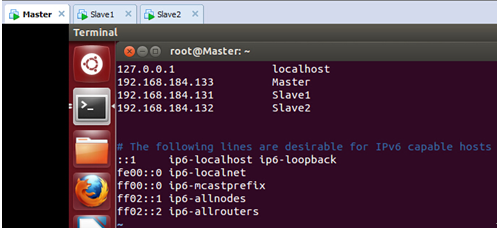
此时在Master上使用ping命令和Slave1和Slave2这两台机器进行沟通:

发现此时已经ping通了两个slave节点的机器。
最后我们在测试一下Slave1这台机器和Master、Slave2的通信:

到目前为止,Master、Slave1、Slave2这三台机器之间实现了相互通信!
Step 2:SSH无密码验证配置
首先我们看一下在没有配置的情况下Master通过SSH协议访问Slave1的情况:
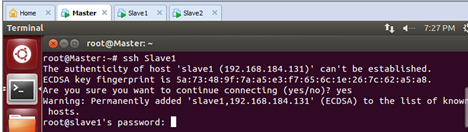
此时会发现我们是需要密码的。我们不登陆进去,直接退出。
怎么使得集群能够通过SSH免登陆密码呢?
按照前面的配置,我们已经分布在Master、Slave1、Slave2这三台机器上的/root/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
此时把Slave1的id_rsa.pub传给Master,如下所示:
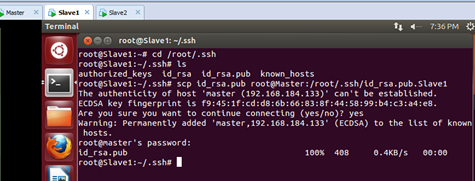
同时把Slave2的id_rsa.pub传给Master,如下所示:

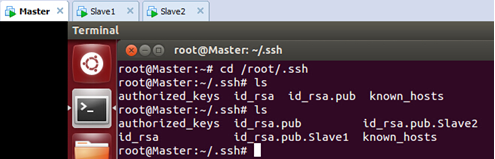
在Master上检查一下是否复制了过来:
此时我们发现Slave1和Slave2节点的公钥已经传输过来
Master节点上综合所有公钥:

将Master的公钥信息authorized_keys复制到Slave1和Slave1的.ssh目录下:

此时再次通过SSH登录Slave1和Slave2:

此时Master通过SSH登录Slave1和Slave2已经不需要密码,同样的Slave1或者Slave2通过SSH协议登录另外两台机器也不需要密码了。
Step 3:修改Master、Slave1、Slave2的配置文件
首先修改Master的core-site.xml文件,此时的文件内容是:

我们把“localhost”域名修改为“Master”:

同样的操作分别打开Slave1和Slave2节点core-site.xml,把“localhost”域名修改为“Master”。
其次修改Master、Slave1、Slave2的mapred-site.xml文件.
进入Master节点的mapred-site.xml文件把“localhost”域名修改为“Master”,保存退出。
同理,打开Slave1和Slave2节点mapred-site.xml,把“localhost”域名修改为“Master”,保存退出。
最后修改Master、Slave1、Slave2的hdfs-site.xml文件:
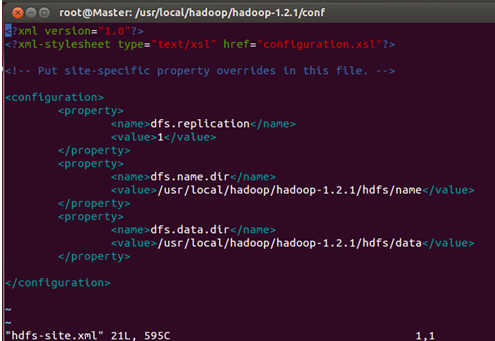
我们把三台机器上的“dfs.replication”值由1改为3,这样我们的数据就会有3份副本:

保存退出。
Step 4:修改两台机器中hadoop配置文件的masters和slaves文件
首先修改Master的masters文件:

进入文件:

把“localhost”改为“Master”:

保存退出。
修改Master的slaves文件,

进入该文件:

具体修改为:

保存退出。
从上面的配置可以看出我们把Master即作为主节点,又作为数据处理节点,这是考虑我们数据的3份副本而而我们的机器台数有限所致。
把Master配置的masters和slaves文件分别拷贝到Slave1和Slave2的Hadoop安装目录下的conf文件夹下:
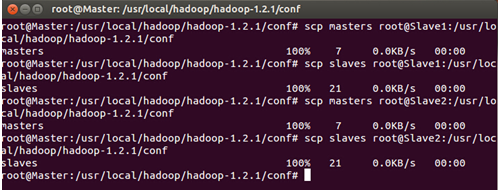
进入Slave1或者Slave2节点检查masters和slaves文件的内容:


发现拷贝完全正确。
至此Hadoop的集群环境终于配置完成!
4.测试Hadoop分布式集群环境;
首先在通过Master节点格式化集群的文件系统:

输入“Y”完成格式化:

格式化完成以后,我们启动hadoop集群

我们在尝试一下停止Hadoop集群:
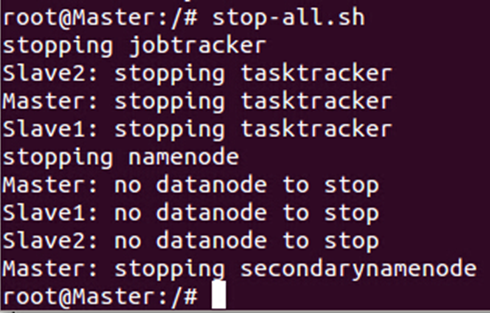
此时出现了“no datanode to stop”的错误,出现这种错误的原因如下:
每次使用 “hadoop namenode -format”命令格式化文件系统的时候会出现一个新的namenodeId,而我我们在搭建Hadoop单机伪分布式版本的时候往我们自己创建的tmp目录下放了数据,现在需要把各台机器上的“/usr/local/hadoop/hadoop-1.2.1/”下面的tmp及其子目录的内容清空,于此同时把“/tmp”目录下的与hadoop相关的内容都清空,最后要把我们自定义的hdfs文件夹中的data和name文件夹中的内容清空:

把Slave1和Slave2中同样的内容均删除掉。
重新格式化并重新启动集群,此时进入Master的Web控制台:

此时可以看到Live Nodes只有三个,这正是我们预期的,因为我们Master、Slave1、Slave2都设置成为了DataNode,当然Master本身同时也是NameNode。
此时我们通过JPS命令查看一下三台机器中的进程信息:

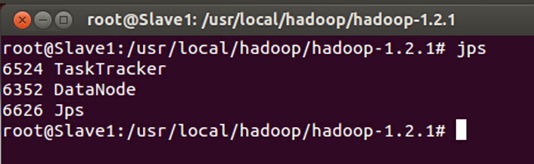

发现Hadoop集群的各种服务都正常启动。
至此,Hadoop集群构建完毕。














 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









