







一、list-watch机制
1.1 list-watch介绍
Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。
用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。
APIServer 经过 API 调用,权限控制,调用资源和存储资源的过程,实际上还没有真正开始部署应用。这里需要 Controller Manager、Scheduler 和 kubelet 的协助才能完成整个部署过程。
在 Kubernetes 中,所有部署的信息都会写到 etcd 中保存。实际上 etcd 在存储部署信息的时候,会发送 Create 事件给 APIServer,而 APIServer 会通过监听(Watch)etcd 发过来的事件。其他组件也会监听(Watch)APIServer 发出来的事件。
1.2 list-watch工作流程
Pod是Kubernetes的基础单元,Pod 启动典型创建过程如下:
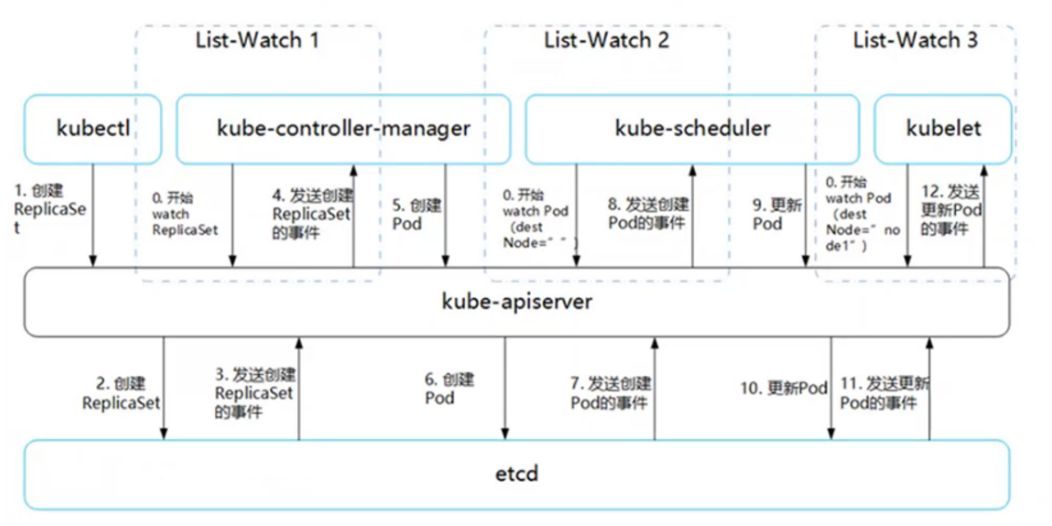
(1)这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在 Master),kubelet(运行在 Node)。他们在进程已启动就会监听(Watch)APIServer 发出来的事件。
(2)用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
(3)APIServer 尝试着将 Pod 对象的相关元信息存入 etcd 中,待写入操作执行完成,APIServer 即会返回确认信息至客户端。
(4)当 etcd 接受创建 Pod 信息以后,会发送一个 Create 事件给 APIServer。
(5)由于 Controller Manager 一直在监听(Watch,通过http的8080端口)APIServer 中的事件。此时 APIServer 接受到了 Create 事件,又会发送给 Controller Manager。
(6)Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证 Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的 Controller(PS:扩容缩容的担当)。
(7)在 Controller Manager 创建 Pod 副本以后,APIServer 会在 etcd 中记录这个 Pod 的详细信息。例如 Pod 的副本数,Container 的内容是什么。
(8)同样的 etcd 会将创建 Pod 的信息通过事件发送给 APIServer。
(9)由于 Scheduler 在监听(Watch)APIServer,并且它在系统中起到了“承上启下”的作用,“承上”是指它负责接收创建的 Pod 事件,为其安排 Node;“启下”是指安置工作完成后,Node 上的 kubelet 进程会接管后继工作,负责 Pod 生命周期中的“下半生”。 换句话说,Scheduler 的作用是将待调度的 Pod 按照调度算法和策略绑定到集群中 Node 上。
(10)Scheduler 调度完毕以后会更新 Pod 的信息,此时的信息更加丰富了。除了知道 Pod 的副本数量,副本内容。还知道部署到哪个 Node 上面了。并将上面的 Pod 信息更新至 API Server,由 APIServer 更新至 etcd 中,保存起来。
(11)etcd 将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果。
(12)kubelet 是在 Node 上面运行的进程,它也通过 List-Watch 的方式监听(Watch,通过https的6443端口)APIServer 发送的 Pod 更新的事件。kubelet 会尝试在当前节点上调用 Docker 启动容器,并将 Pod 以及容器的结果状态回送至 APIServer。
(13)APIServer 将 Pod 状态信息存入 etcd 中。在 etcd 确认写入操作成功完成后,APIServer将确认信息发送至相关的 kubelet,事件将通过它被接受。
注意:在创建 Pod 的工作就已经完成了后,为什么 kubelet 还要一直监听呢?原因很简单,假设这个时候 kubectl 发命令,要扩充 Pod 副本数量,那么上面的流程又会触发一遍,kubelet 会根据最新的 Pod 的部署情况调整 Node 的资源。又或者 Pod 副本数量没有发生变化,但是其中的镜像文件升级了,kubelet 也会自动获取最新的镜像文件并且加载。
二、节点调度
2.1 调度策略
Sheduler是作为单独的程序运行的,启动之后会一直监听APIServer,获取spec.nodeName为空的pod,对每个pod都会创建一个binding,表明该pod应该放到哪个节点上。
调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为预算策略(predicate);然后对通过的节点按照优先级排序,这个是优选策略(priorities);最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
2.2 预算策略
Predicate(预算策略)常见的算法可以使用
● PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源。
● PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配。
● PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突。
● PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点。
● NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读。
如果在 predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。 经过这个步骤,如果有多个节点满足条件,就继续 priorities 过程:按照优先级大小对节点排序。
2.3 优选策略
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。有一系列的常见的优先级选项包括:
● LeastRequestedPriority:通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。也就是说,这个优先级指标倾向于资源使用比例更低的节点。
● BalancedResourceAllocation:节点上 CPU 和 Memory 使用率越接近,权重越高。这个一般和上面的一起使用,不单独使用。比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,虽然 node01 的总使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,从而调度时会优选 node02。
● ImageLocalityPriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。
优选策略通过算法对所有的优先级项目和权重进行计算,得出最终的结果。
2.4 指定调度节点
2.4.1 方法一:nodeName
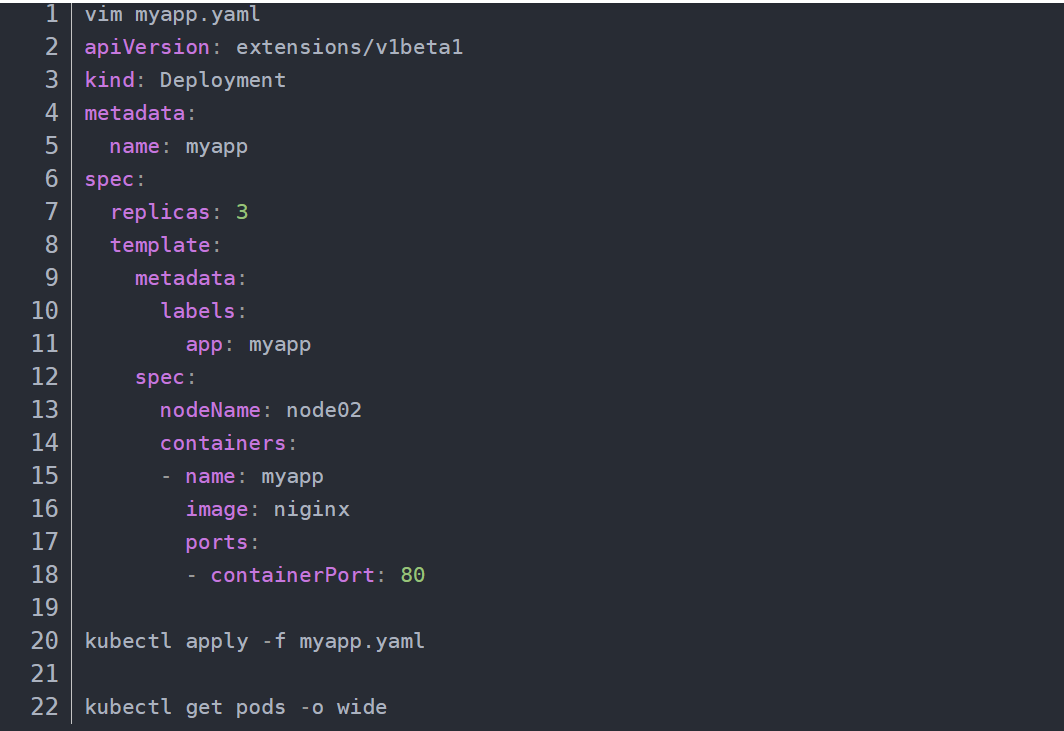
使用pod.spec.nodeName 参数,将Pod直接调度到指定的Node节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配

2.4.2 方法二:nodeSelector
使用pod.spec.nodeSelector参数,通过 kubernetes 的 label-selector 机制选择节点,由调度器调度策略匹配 label,然后调度 Pod 到目标节点,该匹配规则属于强制约束
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1868
1868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









