







文章目录
一、基础知识
1.1、变量
Python的变量类型
-
变量存储在内存中的值,这就意味着在创建变量时会在内存中创建一个地址。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,这些变量可以存储整数,浮点数或字符串等。
-
Python 中的变量赋值不需要声明类型。每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。等号
=用来给变量赋值。等号=运算符左边是变量名,等号=运算符右边是存储在变量中的值。 -
Python中也允许同时对多变量进行赋值。
a, b, c = 1, 2.0, "3.0"
1.2、命名空间
-
定义: 命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
- 作用: 命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何联系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名,但建议在实际编程过程中尽量避免重名的情况。
-
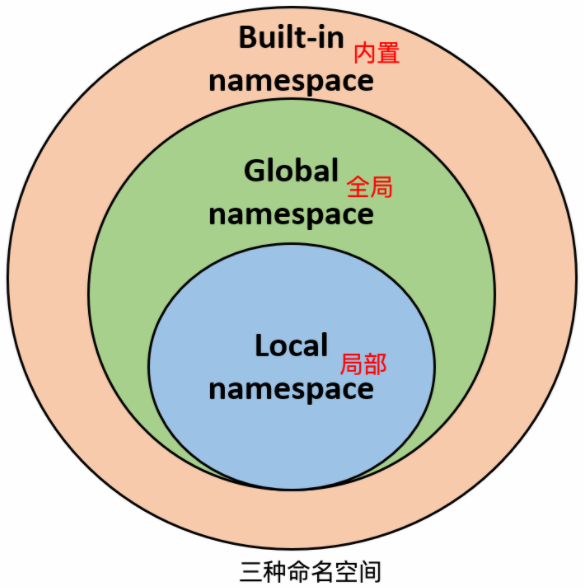
一般有三种形式的命名空间。
-
内置命名空间(Built-in names): 用于存放Python 的内置函数的空间,比如,print,input等不需要定义即可使用的函数就处在内置命名空间。
-
全局命名空间(Global names):模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
-
局部命名空间(Local names):函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。在函数内定义的局部变量,在函数执行结束后就会失效,即无法在函数外直接调用函数内定义的变量。
-
-
命名空间查找顺序: 局部命名空间→全局命名空间→内置命名空间。
-
命名空间的生命周期: 命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
-
1.3、作用域
- 作用域就是一个 Python 程序可以直接访问命名空间的正文区域。在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- Local:在程序的最内层,包含局部变量,比如,一个函数的内部。
- Enclosing:包含了非局部(non-local)也非全局(non-global)的变量。比如,两个嵌套函数,函数(或类)A里面又包含了函数B,那么对于B中的名称来说 A中的作用域就为no-nlocal。
- Global:当前脚本的最外层,比如,当前模块的全局变量。
- Built-in: 包含了内建的变量/关键字等,比如,int。
1.4、异常
1.4.1、什么是异常
- 异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。一般情况下,在Python无法正常处理程序时就会发生一个异常。异常是Python对象,表示一个错误。当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
1.4.2、异常处理
-
捕捉异常可以使用
try/except语句。try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。如果你不想在异常发生时结束你的程序,只需在try里捕获它。 -
**说明:**try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
-
语法:
try: 语句 # 正常的操作。 except name: 语句 # 如果在try部份触发了'name'异常,执行这块代码。 except name,数据: 语句 # 如果触发了'name'异常,获得附加的数据,执行这块代码。 else: 语句 # 如果没有异常执行这块代码 finally: 语句 # 无论有没有异常都会执行
1.5、常用函数
1.5.1、sorted函数
-
Python中
sorted()函数可对所有可迭代的对象进行排序操作。 -
Tip:sort与sorted区别:
sort是应用在list上的方法,sorted可以对所有可迭代的对象进行排序操作。
list的sort方法返回的是对已经存在的列表进行操作,而内建函数sorted方法返回的是一个新的list,而不是在原来的基础上进行的操作。
-
语法
sorted(iterable, key=None, reverse=False) # iterable:可迭代对象。 # key:主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。 # reverse:排序规则,reverse = True 降序 , reverse = False 升序(默认)。
1.5.2、pop函数
-
Python中
pop()函数可用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。 -
语法:
list.pop([index]) # index:index为可选参数,用于表示要移除列表元素的索引值,不能超过列表总长度,默认为index值为“-1”,即删除列表中的最后一个值。
1.5.3、id函数
-
Python中
id()函数可返回对象的唯一标识符,标识符是一个整数。CPython 中id()可用于获取对象的内存地址。 -
语法
id(object) # object:需要获取标识符的对象。
1.5.4、dir函数
-
Python中
dir()函数不带参数时,可返回当前范围内的变量、方法和定义的类型列表;带参数时,可返回参数的属性、方法列表。如果参数包含方法dir(),该方法将被调用。如果参数不包含dir(),该方法将最大限度地收集参数信息。 -
语法
dir(object) # object:对象、变量、类型。
1.5.5、split函数
-
Python中
split()函数可通过指定分隔符对字符串进行分割,如果参数num有指定值,则分隔num+1个子字符串。 -
语法
str.split("sign", num) # sign:分隔符,用于指定对字符串进行分割的单位,常见的分隔符有空格、逗号等。 # num:分割次数,需要注意的是,分割之后的字符串个数等于分割次数加一。
1.5.6、help函数
-
Python中
help()函数可用于查看函数或模块用途的详细说明。help()函数相当于一个内置的Python帮助手册,当我们遇到一些新的函数名称时,掌握好help()函数的使用可以让我们更快更清晰地理解Python里面这些新函数的作用 -
语法
help(object) # object:需要查看详细说明信息的对象。
1.6、模块
1.6.1、threading模块
-
threading,基于线程的并行,这个模块在较低级的模块
_thread(底层多线程 API)基础上建立较高级的线程接口。 -
该模块定义了以下函数:
-
threading.active_count() 返回当前存活的线程类 Thread 对象。返回的计数等于 enumerate() 返回的列表长度。
-
threading.current_thread() 返回当前对应调用者的控制线程的 Thread 对象。如果调用者的控制线程不是利用 threading 创建,会返回一个功能受限的虚拟线程对象。
-
threading.get_ident() 返回当前线程的 “线程标识符”。它是一个非零的整数。它的值没有直接含义,主要是用作 magic cookie,比如作为含有线程相关数据的字典的索引。线程标识符可能会在线程退出,新线程创建时被复用。
-
1.6.2、zipfile模块
-
ZIP 文件格式是一个常用的归档与压缩标准。 这个模块提供了创建、读取、写入、添加及列出 ZIP 文件的工具。 任何对此模块的进阶使用都将需要理解此格式,其定义参见 PKZIP 应用程序笔记。
-
此模块目前不能处理分卷 ZIP 文件。它可以处理使用 ZIP64 扩展(超过 4 GB 的 ZIP 文件)的 ZIP 文件。它支持解密 ZIP 归档中的加密文件,但是目前不能创建一个加密的文件。解密非常慢,因为它是使用原生 Python 而不是 C 实现的。
-
zipfile的几个常用函数:- ZipFile.close() 关闭归档文件。 你必须在退出程序之前调用 close() 否则将不会写入关键记录数据
- ZipFile.getinfo(name) 返回一个 ZipInfo 对象,其中包含有关归档成员 name 的信息。 针对一个目前并不包含于归档中的名称调用 getinfo() 将会引发 KeyError。
- ZipFile.infolist() 返回一个列表,其中包含每个归档成员的 ZipInfo 对象。 如果是打开一个现有归档则这些对象的排列顺序与它们对应条目在磁盘上的实际 ZIP 文件中的顺序一致。
- ZipFile.namelist() 返回按名称排序的归档成员列表。
二、Python面向对象
2.1、选手的最好三次成绩
-
处理文件中运动员的测试数据,并选出该运动员的最好的三次成绩
-
# 读取文件内容,按逗号进行切分 def get_coach_data(filename): with open(filename) as f: line = f.readline() return line.strip().split(',') # 输出读取文件的结果 times = get_coach_data('mywork/james.txt') print('读取文件james.txt后的结果:\n') print(times) ''' 读取文件james.txt后的结果: ['2-34', '3:21', '2', '34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22'] ''' -
get_coach_data函数说明
- filename为文件路径
- f表示文件对象
- f.realine()表示读取文件的一行
- line.strip().split(’,’)为链式函数写法意思是,先对这一行的数据进行strip(),就是去掉改行头尾空格和换行符。然后对strip()的结果进行split(’,’),对结果以逗号的进行切分形成一个数组。
-
# 数据格式标准化 def sanitize(time_string): if '-' in time_string: splitter = '-' elif ':' in time_string: splitter = ':' else: return (time_string) (mins,secs) = time_string.split(splitter) return (mins+'.'+secs) -
sanitize函数说明
- time_string为时间数组
- splitter是根据原数据的格式来确实分钟和秒的分隔符
- (mins,secs) = time_string.split(splitter)以splitter分隔符切分每个时间数据到两个变量中mins,secs
- return (mins+’.’+secs)将分钟和秒以字符串点进行连接
-
# 输出数据格式标准化后的时间 james_times = get_coach_data('mywork/james.txt') clean_james = [] for each_t in james_times: clean_james.append(sanitize(each_t)) print('输出james.txt标准化后的结果\n') print(clean_james) ''' 输出james.txt标准化后的结果 ['2.34', '3.21', '2', '34', '2.45', '3.01', '2.01', '2.01', '3.10', '2.22'] ''' -
# 排序 sorted_james=sorted(clean_james) # 去掉重复 unique_james = [] for each_t in sorted_james: if each_t not in unique_james: unique_james.append(each_t) print('输出排序并去重后的结果,并取前3个数据\n') print(unique_james[0:3]) ''' 输出排序并去重后的结果,并取前3个数据 ['2', '2.01', '2.22'] ''' -
# python,一句话搞定数据标准化,排序和去重 james_times = get_coach_data('mywork/james.txt') print('一句话搞定数据标准化、排序、去重\n') print(sorted(set([sanitize(t) for t in james_times]))[0:3]) ''' 一句话搞定数据标准化、排序、去重 ['2', '2.01', '2.22'] '''
2.2、获取选手的数据
-
# 读取新的数据文件 james_new = get_coach_data('mywork/james_new.txt') (james_name,james_dob) = james_new.pop(0),james_new.pop(0) james_top3 = sorted(set([sanitize(t) for t in james_new]))[0:3] print('姓名:%s,生日:%s,最快的3次成绩:%s' %(james_name,james_dob,james_top3)) ''' 姓名:james,生日:2006-11-11,最快的3次成绩:['2.01', '2.22', '2.34'] '''
2.3、使用字典减少处理多个运动员的数据时的变量数
-
james_new = get_coach_data('mywork/james_new.txt') james_data={} james_data['Name'] = james_new.pop(0) james_data['Dob'] = james_new.pop(0) james_data['top3'] = sorted(set([sanitize(t) for t in james_new]))[0:3] print('姓名:%s,生日:%s,最快的3次成绩:%s' %(james_data['Name'],james_data['Dob'],james_data['top3'])) ''' 姓名:james,生日:2006-11-11,最快的3次成绩:['2.01', '2.22', '2.34'] '''
2.4、类
-
使用类的好处
- 降低复杂性 -> 更少的bug -> 提高可维护行
- 类可以将数据与函数绑定在一起,使代码模块化
- 调用数据和函数,使用对象名.的方式,使代码更加优雅
-
运动员数据处理
class Athlete: #类属性 address = '中国足球协会训练基地xx街xx号' def __init__(self,a_name,a_dob=None,a_times=[]): self.name = a_name self.dob = a_dob self.times = a_times def top3(self): return sorted(set([sanitize(t) for t in self.times]))[0:3] def sanitize(self,time_string): if '-' in time_string: splitter = '-' elif ':' in time_string: splitter = ':' else: return (time_string) (mins,secs) = time_string.split(splitter) return (mins+'.'+secs) # 从文件中读取数据 james_new = get_coach_data('mywork/james_new.txt') james_name = james_new.pop(0) james_dob = james_new.pop(0) james_times = james_new # 创建Athlete对象 james = Athlete(james_name,james_dob,james_times) print('姓名:%s,生日:%s,最快的3次成绩:%s' %(james.name,james.dob,james.top3())) ''' 姓名:james,生日:2006-11-11,最快的3次成绩:['2.01', '2.22', '2.34'] '''
2.5、如何定义类
-
class Athlete
-
第一部分:class定义类的关键字,Athlete符合python标识符命名规则,:表示类内容的开始
def init(self,a_name,a_dob=None,a_times=[]):
-
第二部分:def定义函数的关键字,init 方法是一个特殊方法会在实例化对象时自动调用,我们会在这个方法中对数据进行赋值。self作为类中函数的第一个参数,方便该方法调用该类的其他属性和方法。
-
第三部分:自定义的属性和方法
-
2.6、如何使用类
-
1.创建对象
对象名 = 类名(参数)
-
2.使用:调用类的方法和属性
对象.属性名
对象.方法名()
2.7、类属性
- 所有对象共享的数据
- 如何使用:
- 定义:在 init之上,或者说在类的范围内与方法同等级别,书写变量名=值
- **调用:**类名.类属性
2.8、类方法
-
所有对象共享的方法
-
如何使用:
-
定义:方法定义时,使用@classmethod标记
-
调用:
类名.类方法
对象.类方法
-
2.9、私有属性和方法
-
外部不能访问的属性和方法
-
如何使用:
- 定义:在属性和方法名前加 __ 两个下划线
- 调用:只能通过类中的方法来调用私有的属性和方法
- 定义:在属性和方法名前加 __ 两个下划线
-
例子:
class Athlete: def __init__(self,a_name,a_dob=None,a_times=[]): self.__name = a_name self.dob = a_dob self.times = a_times def sayName(self): print(self.__name) def top3(self): return sorted(set([self.__sanitize(t) for t in self.times]))[0:3] def __sanitize(self,time_string): if '-' in time_string: splitter = '-' elif ':' in time_string: splitter = ':' else: return (time_string) (mins,secs) = time_string.split(splitter) return (mins+'.'+secs)















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









