






二叉搜索树:
这里实现两个版本 一个是val版本 一个是key-val版本
树节点
val版本:
template<class val_type>
struct BSTreeNode
{
typedef BSTreeNode<val_type> Node;
Node* _left;
Node* _right;
val_type _key;
BSTreeNode(const val_type& key)
:_key(key)
,_left(nullptr)
,_right(nullptr)
{}
};key-val版本:
template<class key_type ,class val_type>
struct BSTreeNode
{
typedef BSTreeNode<key_type ,val_type> Node;
Node* _left;
Node* _right;
val_type _val;
key_type _key;
BSTreeNode(const key_type& key , const val_type& val = val_type())
:_key(key)
,_val(val)
, _left(nullptr)
, _right(nullptr)
{}
};二叉搜索树,首先满足二叉树,节点中存左孩子指针,右孩子指针,然后存val 或者key-val。
初始化,先将节点指针初始化位空,再将传入的值赋key 和 val 这里 key-val版本中如果只传一个key的话,val默认调用val_type 的构造函数进行初始化
成员成员函数
key版本
template<class val_type>
class BSTree
{
public:
typedef BSTreeNode<val_type> Node;
private:
Node* _root = nullptr;
};key-val版本
template<class key_type, class val_type>
class BSTree
{
public:
typedef BSTreeNode<key_type, val_type> Node;
private:
Node* _root = nullptr;
};区别就是一个模板只用传一个参数,一个模板需要传两个参数 默认的根节点都初始化成nullptr
构造函数
BSTree() = default;声明根节点的时候已经进行了nullptr初始化,所以无需再进行初始化
拷贝构造
BSTree(const BSTree<val_type>& sorce)
{
_root = copy(sorce._root);
}
BSTree<val_type> operator = (BSTree<val_type> sorce)
{
swap(_root, sorce._root);
return *this;
}Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newRoot = new Node(root->_key);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
}拷贝构造两个版本几乎没有任何区别
注意这里的copy函数要放在private里 不对外界开放使用
这里的operator 只进行了指针的拷贝,并没有拷贝整颗搜索树!!!
析构
~BSTree()
{
Destroy(_root);
}
void Destroy(Node* root)
{
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}这里的Destroy也建议放到private里,不对外界开放使用
这里进行递归析构(后续遍历二叉树)因为被释放了之后就找不到left和right了,所以应该先释放孩子,在释放parent
两份版本的析构没有任何区别
查找
key版本:
bool find(const val_type& val)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > val)
{
cur = cur->_left;
}
else if (cur->_key < val)
{
cur = cur->_right;
}
else
return true;
}
return false;
}key-val版本:
Node* find(const key_type& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->_left;
}
else if (cur->_key < key)
{
cur = cur->_right;
}
else
return cur;
}
return nullptr;
}原理:由于二叉搜索树的数据特点,左孩子比自己小,右孩子比自己大,所以比自己大向右走,比自己小向左走如果相同就说明找到了;
差别:这里key-val版本中传参与key一样,只用key来找整个节点,如果找到了返回节点的引用,与key版本区别的是,如果找到了只需要返回true(一般key都是不可以修改的,所以返回节点的引用没有意义)
插入
key版本
bool insert(const val_type& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
return false;
}
cur = new Node(key);
if (parent->_key > key)
parent->_left = cur;
else
parent->_right = cur;
return true;
}key-val版本
bool insert(const key_type& key,const val_type& val = val_type())
{
if (_root == nullptr)
{
_root = new Node(key,val);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
return false;
}
cur = new Node(key,val);
if (parent->_key > key)
parent->_left = cur;
else
parent->_right = cur;
return true;
}插入元素比较简单,首先判断根节点是不是为空,如果为空则根节点指向新节点,若不为空,则需要先找到新节点在整个二叉搜索树的合适位置,遍历到叶子节点,根据与叶子节点的内容大小判断插入到叶子节点的左还是右。
这里两个版本的插入没有什么太大的区别,主要还是传参不同,这里key-val版本的val默认调用val_type的构造函数进行初始化
删除
删除的情况比较多,需要分多种情况考虑,但是两个版本的区别几乎没有(不需要用到val)
这里用key版本举例
bool erase(const key_type& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)//先找到节点
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else//cur->_key==key
{
if (cur->_left == nullptr)//左节点为空
{
if (cur == _root)
_root = _root->_right;
else
{
if (cur == parent->_left)//cur位parent的左节点
parent->_left = cur->_right;
else//cur是parent的右节点
parent->_right = cur->_right;
}
delete cur;//清理要删除的节点
cur = nullptr;
return true;
}
else if (cur->_right == nullptr)
{
if (cur == _root)
_root = _root->_right;
else
{
if (cur == parent->_left)//cur位parent的左节点
parent->_left = cur->_left;
else//cur是parent的右节点
parent->_right = cur->_left;
}
delete cur;//清理要删除的节点
cur = nullptr;
return true;
}
else//cur 左右节点都不为空
{
//找到与cur差距最小的节点
Node* rightMinParent = cur;
Node* rightMin = cur->_right;
while (rightMin->_left)//找到cur->_right的最左节点
{
rightMinParent = rightMin;
rightMin = rightMin->_left;
}
cur->_key = rightMin->_key;//交换两个节点的值,让rightMin替换cur
//加一层判断
if (rightMin == rightMinParent->_left)
rightMinParent->_left = rightMin->_right;
else
rightMinParent->_right = rightMin->_right;
delete rightMin;
rightMin = nullptr;
return true;
}
}
}
return false;
}首先还是找到该节点,如果没有找到则不需要删除,返回false即可,如果需要删除,返回true
接下来看删除的具体情况分类:(要删除的节点找到了,为cur)
注:圆形表示节点,方形表示子树
1.
if (cur->_left == nullptr)1-1
if (cur == _root)
这种情况下,要删除cur节点的话,直接让 _root = _root->_right 完成删除!
1-2
if(cur != _root)
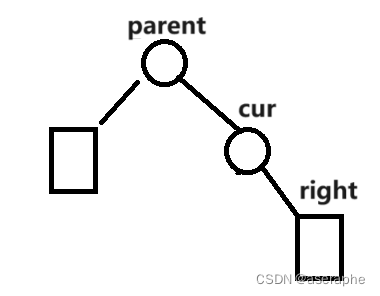
这两种情况:比较简单,由于cur的left为空,所以直接将cur的右子树,给parent的left或right即可
if (cur == parent->_left)//cur位parent的左节点
parent->_left = cur->_right;
else//cur是parent的右节点
parent->_right = cur->_right;2
if (cur->_right == nullptr)这种情况与第一种情况分析相同:
2-1:
if (cur == _root) 
这种情况下,要删除cur节点的话,直接让 _root = _root-> _left 完成删除!
2-2
if(cur != _root) 

这两种情况:比较简单,由于cur的 right 为空,所以直接将cur的左子树,给parent的left或right即可
if (cur == parent->_left)//cur位parent的左节点
parent->_left = cur->_left;
else//cur是parent的右节点
parent->_right = cur->_left;3:cur 的left和right 都不为空 这种情况最复杂!
我们需要找到合适的元素来替换掉cur节点来完成删除cur的目的,首要是要满足替换完之后整体还要满足二叉搜索树的特点,我们只需要找到cur->left 节点 cur->right节点之间的值就可以了,我们可以把cur->right 节点的最左节点 或者cur->left 节点的最右节点来替换掉cur 都可以满足任务,这里采用第一种
注意:这种情况下,如果cur为root 时,同样可以用这种方法来完成删除
我们让rightMin = cur->right 然后一直找左
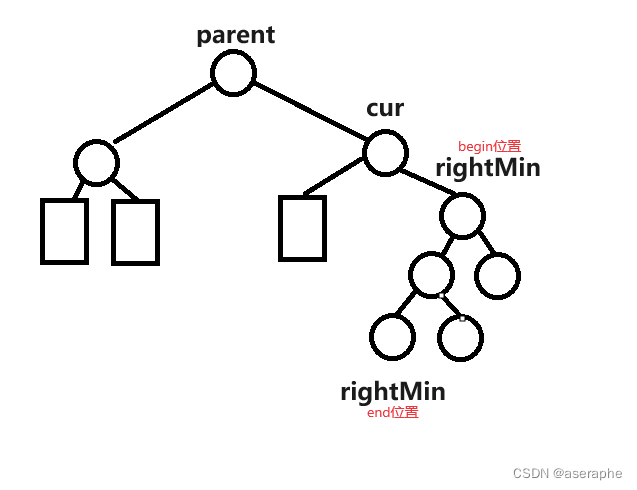

Node* rightMinParent = cur;
Node* rightMin = cur->_right;
while (rightMin->_left)//找到cur->_right的最左节点
{
rightMinParent = rightMin;
rightMin = rightMin->_left;
}然后我们需要替换掉cur节点,并将rightMin的parent->left 设为nullptr
cur->_key = rightMin->_key;//交换两个节点的值,让rightMin替换cur
//加一层判断
if (rightMin == rightMinParent->_left)
rightMinParent->_left = rightMin->_right;
else
rightMinParent->_right = rightMin->_right;
delete rightMin;
rightMin = nullptr;
return true;完成删除
遍历
key版本:
public:
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}key-val版本:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << "-"<<root->_val<<" ";
_InOrder(root->_right);
}利用中序遍历 对所有节点中的key (val)进行打印输出















 3641
3641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









