







DBCP主要是为jdbc提供连接池服务。
2.实现
2.1 Jakarta Commons Pool
DBCP利用了Jakarta Commons Pool来实现连接池管理。下面回顾一下Commons Pool的基本概念
PoolableObjectFactory: 用于管理被池化的对象的产生、激活、挂起、校验和销毁;
ObjectPool: 用于管理要被池化的对象的借出和归还,并通知PoolableObjectFactory完成相应的工作
使用过程:
1. 生成一个要用的PoolableObjectFactory类的实例
- PoolableObjectFactory factory = new PoolableObjectFactorySample();
2. 利用这个PoolableObjectFactory实例为参数,生成一个实现了ObjectPool接口的类(例如StackObjectPool)的实例,作为对象池
- ObjectPool pool = new StackObjectPool(factory);
3. 需要从对象池中取出对象时,调用该对象池的Object borrowObject()方法。
- obj = pool.borrowObject();
4. 需要将对象放回对象池中时,调用该对象池的void returnObject(Object obj)方法。
- pool.returnObject(obj);
- 5. 当不再需要使用一个对象池时,调用该对象池的void close()方法,释放它所占据的资源。
- pool.close();
给一个PoolableObjectFactory 的例子:
- public class PoolableObjectFactorySample implements PoolableObjectFactory {
- public Object makeObject() throws Exception {
- return new Object();
- }
- public void activateObject(Object obj) throws Exception {
- System.err.println("Activating Object " + obj);
- }
- public void passivateObject(Object obj) throws Exception {
- System.err.println("Passivating Object " + obj);
- }
- public boolean validateObject(Object obj) {
- return true;
- }
- public void destroyObject(Object obj) throws Exception {
- System.err.println("Destroying Object " + obj);
- }
- }
通过以上内容,相信大家都了解了common pool的基本用法。
2.2 DBCP
一个普通的jdbc连接大概是这样的:
- public static Connection getConn() throws Exception {
- Class.forName("oracle.jdbc.driver.OracleDriver");
- Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@10.20.143.12:1521:crmp?args[applicationEncoding=UTF-8,databaseEncoding=UTF-8]","eve", "ca");
- return conn;
- }
然后考虑池化,我们能想到的第一步就是把getConn()放到刚刚的PoolableObjectFactory的makeObject里面去。
dbcp其实做的也就比这件事多一点点,先上个图:
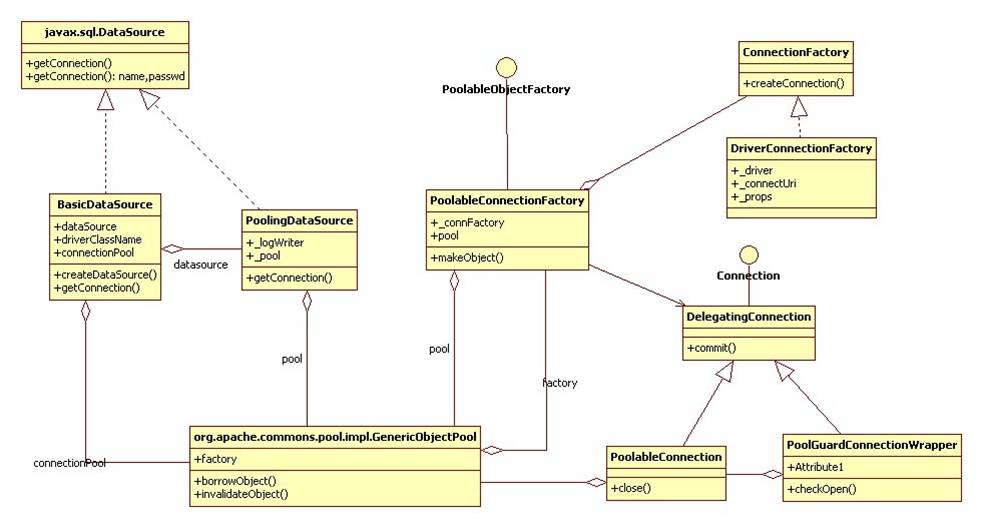
datasource和connection都用decorator包装了一下。这也是一个decorator的典型用法。
最主要的一点是PoolableConnection持有了ObjectPool的一个引用,这样才能在connection被使用完后,任意时刻都可以放回池中,而conn的使用者无需关注ObjectPool。
主要的createDatasource过程如下:
- protected synchronized DataSource createDataSource()
- throws SQLException {
- if (closed) {
- throw new SQLException("Data source is closed");
- }
- // Return the pool if we have already created it
- if (dataSource != null) {
- return (dataSource);
- }
- // create factory which returns raw physical connections
- ConnectionFactory driverConnectionFactory = createConnectionFactory();
- // create a pool for our connections
- createConnectionPool();
- // Set up statement pool, if desired
- GenericKeyedObjectPoolFactory statementPoolFactory = null;
- if (isPoolPreparedStatements()) {
- statementPoolFactory = new GenericKeyedObjectPoolFactory(null,
- -1, // unlimited maxActive (per key)
- GenericKeyedObjectPool.WHEN_EXHAUSTED_FAIL,
- 0, // maxWait
- 1, // maxIdle (per key)
- maxOpenPreparedStatements);
- }
- // Set up the poolable connection factory
- createPoolableConnectionFactory(driverConnectionFactory, statementPoolFactory, abandonedConfig);
- // Create and return the pooling data source to manage the connections
- createDataSourceInstance();
- try {
- for (int i = 0 ; i < initialSize ; i++) {
- connectionPool.addObject();
- }
- } catch (Exception e) {
- throw new SQLNestedException("Error preloading the connection pool", e);
- }
- return dataSource;
- }
创建连接池(datasource)的过程,通过以上代码就比较清楚了。
下面再补充一点连接失效时的处理:
- 在数据库端正常关闭tcp连接的情况下(发送了FIN包,如oracle的kill process),connection能够检测到。
- 在 数据库端未正常关闭tcp连接的情况下(未发送FIN包,如session失效,比如DB服务器端断掉了连接,oracle中杀掉了 session,mysql中超过最大时常断掉了连),这种情况下应用端的连接会继续可用,知道使用类似insert,commit这样的操作,才会抛出 异常
在应用catach到连接断开的异常时,会释放conn,即调用conn.close,这时一般再检查下,如果发现连接无效,是不会放回连接池的。从而说明,数据库如果切换,应用这边理论上是不用重启就可以切过去的。
- public synchronized void close() throws SQLException {
- boolean isClosed = false;
- try {
- isClosed = isClosed();
- } catch (SQLException e) {
- try {
- _pool.invalidateObject(this);
- } catch (Exception ie) {
- // DO NOTHING the original exception will be rethrown
- }
- throw new SQLNestedException("Cannot close connection (isClosed check failed)", e);
- }
- if (isClosed) {
- throw new SQLException("Already closed.");
- } else {
- try {
- _pool.returnObject(this);
- } catch(SQLException e) {
- throw e;
- } catch(RuntimeException e) {
- throw e;
- } catch(Exception e) {
- throw new SQLNestedException("Cannot close connection (return to pool failed)", e);
- }
- }
- }
2.3 连接池常用配置
先贴一个常用配置:
- <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
- <property name="driverClassName" value="driverClassName" />
- <property name="url" value="${db_url}" />
- <property name="username" value="${db_user}" />
- <property name="password" value="${db_passwd}" />
- <property name="maxWait" value="${db_maxWait}" />
- <property name="initialSize" value="2" />
- <property name="maxActive" value="20" />
- <property name="maxIdle" value="20" />
- <property name="minIdle" value="2" />
- <property name="timeBetweenEvictionRunsMillis" value="300000" />
- <property name="testOnBorrow" value="false" />
- <property name="testWhileIdle" value="true" />
- <property name="validationQuery" value="select 1 from dual" />
- </bean>
其实多数配置是common.pool的配置,一提到池,大家就想到最大活动,最大空闲,最小空闲,空闲时间等概念。
这里主要解释一下:maxActive,maxIdle这两个参数
- maxActive:最多活动连接数,连接池是这样用它的
- if(_maxActive < 0 || _numActive < _maxActive) {
- // allow new object to be created
- } else {
- // the pool is exhausted
- switch(_whenExhaustedAction) {
- case WHEN_EXHAUSTED_GROW:
- // allow new object to be created
- break;
- ....
- default:
- throw new IllegalArgumentException("WhenExhaustedAction property " + _whenExhaustedAction + " not recognized.");
- }
- }
- }
- _numActive++;
这里可以看到,每次创建一个对象_numActive++,当创建的对象>=最大值时,新的对象就需要排队等待了。等待如果超过了默认时间(配置中的maxWait)就回抛出
throw new NoSuchElementException("Timeout waiting for idle object");从而出现我们常常看到的连接拿不到的情况。
- maxIdle:在池内的最多空闲连接数,默认配置为8
- if (decrementNumActive) {
- _numActive--;
- }
- if((_maxIdle >= 0) && (_pool.size() >= _maxIdle)) {
- shouldDestroy = true;
- } else if(success) {
- _pool.addLast(new ObjectTimestampPair(obj));
- }
- notifyAll(); // _numActive has changed
- if(shouldDestroy) {
- try {
- _factory.destroyObject(obj);
- } catch(Exception e) {
- // ignored
- }
- }
在return的过程中,我们可以看到,如果_pool.size() >= _maxIdle,连接就会直接消耗,在dbcp的默认配置中,这里的值为8,而maxactive为28,这样最大的问题照成高并发的情况下,可能有一 批连接在归还的时候被销毁,很快大并发上来的时候又会创建. 创建是一个耗时耗资源的事情,而且public synchronized Object borrowObject() 是同步方法,所以在高并发时出现大量线程block,以下是一个20并发查询的测试结果(查询sql本身耗时不多):
上面是maxactive=28,maxidle=8的情况,响应时间和tps也就不用说了。对于调整后的线程还是有一定阻塞的情况,是因为测试使用了ibatis,ibatis的一些原因照成的,详见附录[1]
- timeBetweenEvictionRunsMillis:表示多少时间执行一次逐出。
逐出的大概原理是后台timer每隔timeBetweenEvictionRunsMillis起一个线程,
取出池中的 return Math.min(_numTestsPerEvictionRun, _pool.size());个连接,(默认是3个,可通过参数控制),检查他的空闲时间:
- if ((_minEvictableIdleTimeMillis > 0) && (idleTimeMilis > _minEvictableIdleTimeMillis)) {
- removeObject = true;
- }
如果大于_minEvictableIdleTimeMillis(默认是30分钟,同样可以设置),就销毁。如果配置了testWhileIdle,还 会测试这个连接是否可用,不可用同样也会销毁。注意这里一次只会处理numTestsPerEvictionRun个连接,不会一次全部处理。
- minIdle:最小空闲数
对于这个值,有的推荐配成0,有的推荐配成2,各有说法:
推荐配成0的原因是:
- public void run() {
- try {
- evict();
- } catch(Exception e) {
- // ignored
- }
- try {
- ensureMinIdle();
- } catch(Exception e) {
- // ignored
- }
- }
evict()会检查对象空闲时间,删除不用对象,然后ensureMinIdle()会检查池中是否有大于minIdle个对象,如果没有,就创建对 象。这就可能造成在应用很闲的时候,先将所有对象删除,然后又重新创建两个对象,过会又删除的抖动情况。目前的配置是30分钟逐出,也就是每30分钟会多 一次消耗。
配成2的好处是,应用比较闲的时候,至少不会每次请求都重新建立连接。
附录:
[1] ibatis导致线程阻塞的问题
1. 对于上文的阻塞,通过dump线程发现,是由于ibatis在处理返回结果的时候出现的。
- at com.ibatis.common.beans.ClassInfo.getInstance(ClassInfo.java:362)
- - locked <0x00002aaaae2c9b60> (a java.lang.Class for java.util.HashMap)
- at com.ibatis.common.beans.ComplexBeanProbe.setProperty(ComplexBeanProbe.java:328)
- ….
ClassInfo.getInstance对应的代码是:
- if (cacheEnabled) {
- synchronized (clazz) {
- ClassInfo cache = (ClassInfo) CLASS_INFO_MAP.get(clazz);
- if (cache == null) {
- cache = new ClassInfo(clazz);
- CLASS_INFO_MAP.put(clazz, cache);
- }
- return cache;
- }
上面这段代码的目的是什么呢?ibatis在取得查询结果后,需要通过反射将driver返回的 object[]设置到resultMap中指定的对象(通过set**方法)。出于性能考虑(反射调用getMethod相对耗时很多),ibatis 使用class作为key,将所用的set方法放到map中缓存方便反射调用。为了避免被并发多次初始化,使用了同步。但是在高并发的情况下(而且我们的 测试是取得同一个对象的数据),该同步导致阻塞,也就是测试报告中新配置线程block的地方。
解释了上面所有的问题后,还有一个疑问,除了第一次调用,每次调用这个函数只会操作
- ClassInfo cache = (ClassInfo) CLASS_INFO_MAP.get(clazz)
这个方法虽然有同步,但执行是非常快的,为什么会造成多个线程阻塞呢?
调研发现是因为这个方法在设置每一个属性的时候会被调用一次,假设一个查询返回20条记录,一条记录有10个属性,那么一个结果拼装至少会调用 200次,由于释放锁只是修改内存结构,并不会切换线程(java中block的线程在linux中是sleep状态,处于等待队列中),因此一般情况 下,当前持有锁的线程会一直反复持有这个锁并连续调用200次,然后其他线程重新竞争的时候,又只有一个线程会竞争到锁,这样运气最坏的线程就会等待 (19*200)次操作,虽然每次时间很短,加起来也有一定的阻塞情况了。















 2399
2399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









