







目录
一、实验目标
数据集包括164个标注为猫的.wav文件,总共1323秒和113个标注为狗叫声的.wav文件,总共598秒,要求判别每个音频是狗叫还是猫叫
二、数据分析
随机播放了一些音频,然后使用下面的代码输出了他们的声谱图、频率随时间变化和梅尔倒频率系数的热力图:
# 读取音频文件
Audio = np.array(librosa.load('./cats_dogs/cat_86.wav')[0])
SampleRate=librosa.load('./cats_dogs/cat_86.wav')[1]
# 绘制声谱图
plt.plot(Audio)
plt.show()
#绘制频率随时间变化的波形图
plt.specgram(Audio, Fs = SampleRate)
plt.show()
#绘制梅尔频率倒谱系数热图
MFCC = librosa.feature.mfcc(y = Audio, sr = SampleRate)
plt.imshow(MFCC, cmap = 'hot')
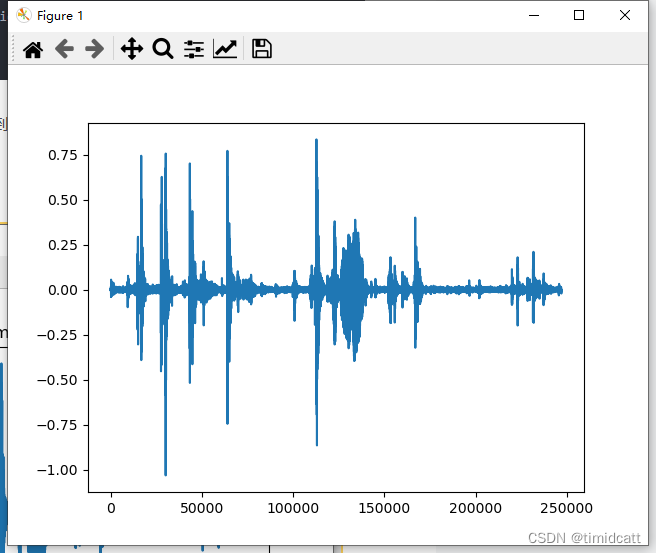
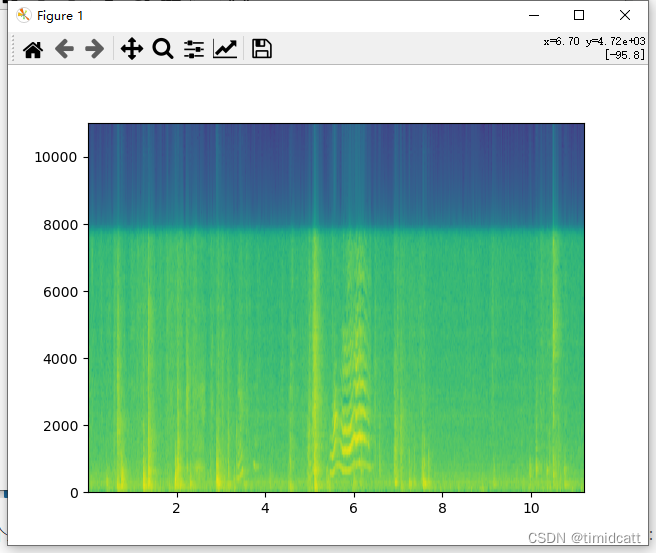
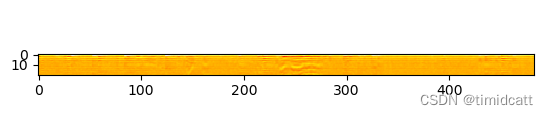
plt.show()发现一些音频10秒左右的长度中只有不到3秒的动物叫声,其他都是一些杂音,在6s左右的地方还是能看出来猫的声音特征的:
cat_1.wav:
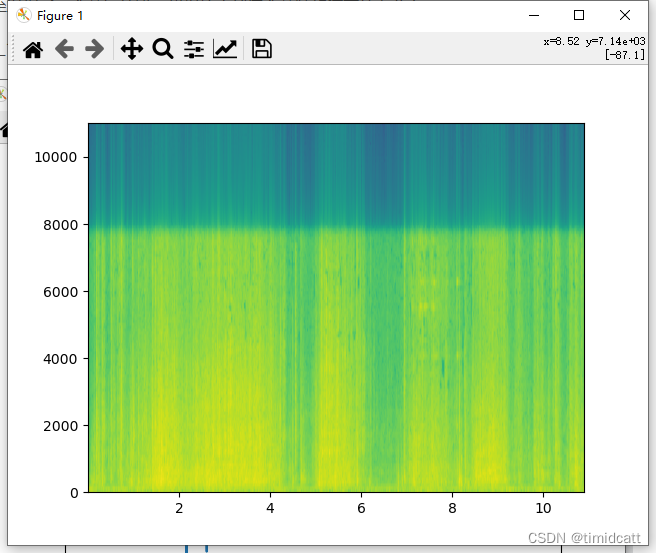
有一些音频是没有动物叫声的,只有杂音,从频率图可以看出没有猫的特征:
cat_41.wav

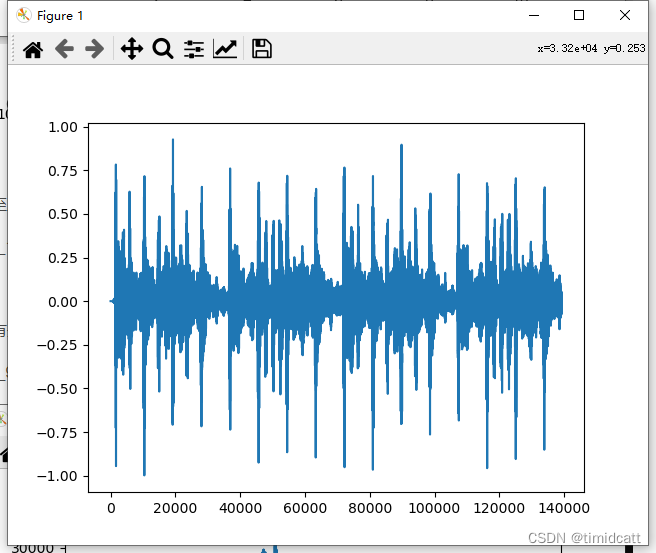
还发现了一个音乐片段,也是与猫的特征完全不同:
cat_123.wav:
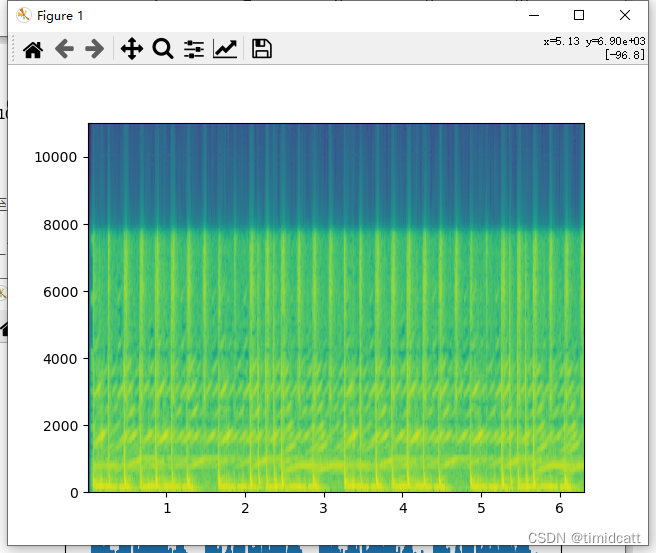

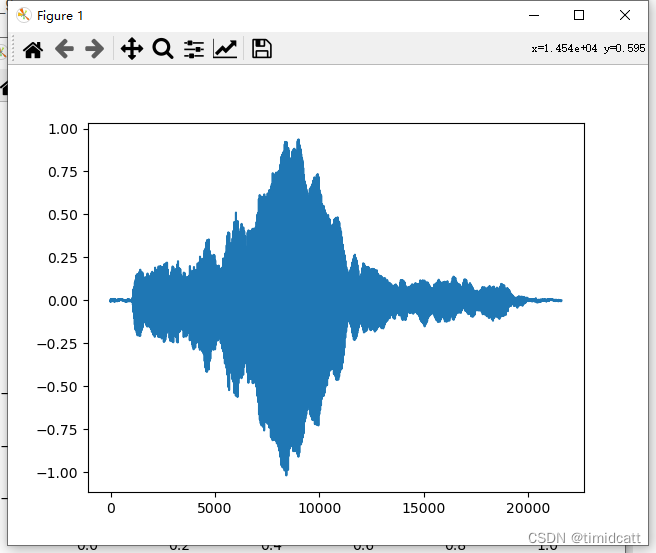
也有最容易辨别的,只有叫声的音频,猫的特征最为明显:
cat_9.wav
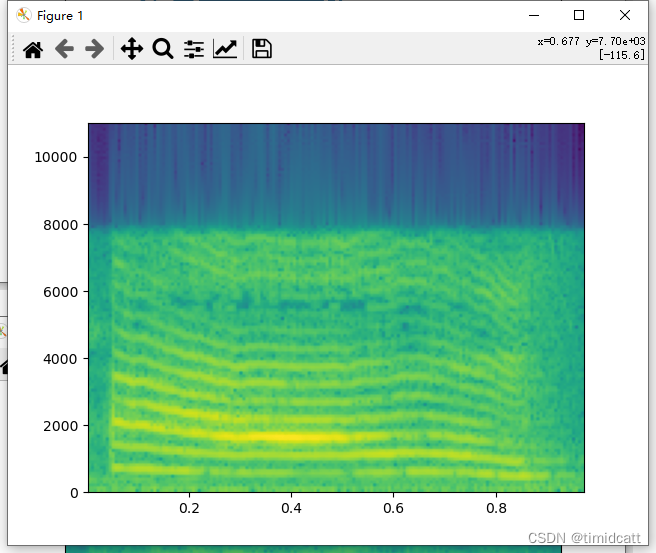
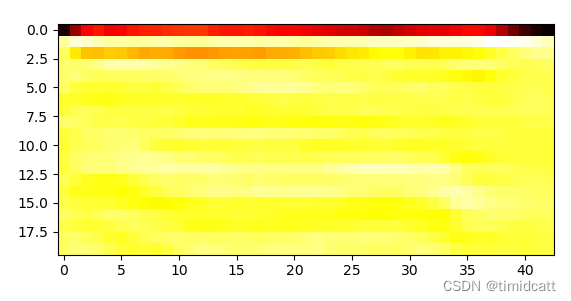
狗叫声听上去大部分都比较正常(不过也发现有像dog_barking_108.wav是杂音)
dog_barking_39.wav:
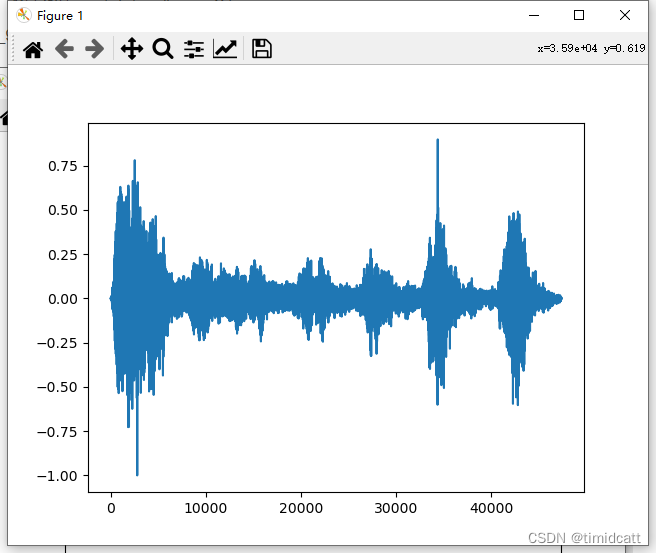
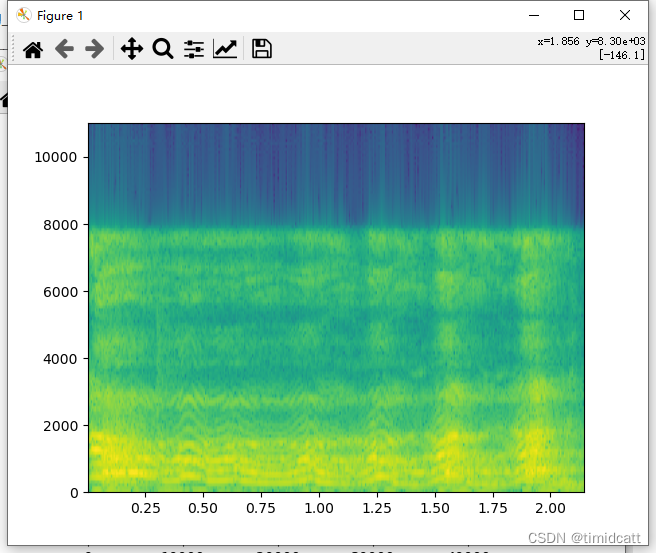
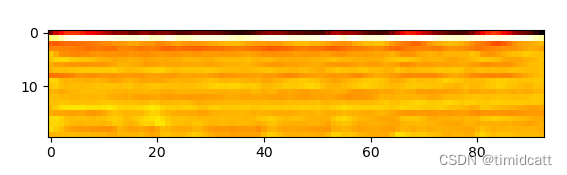
其他的音频就不过多展示了,可以看出猫叫声的频率在2000及以上最高,狗叫声频率分布在2000以下,猫叫声的MFCC热力图颜色浅,而狗的热力图颜色深
三、实验探究不同参数的影响
我们这里选择了差距看上去更大一点的MFCC作为音频特征,更准确的说是MFCC均值,构建高斯混合模型,并使用期望最大化算法进行训练,代码如下:
#音频特征
Features = []
#音频标签
Labels = []
#遍历277个音频文件
for File in os.listdir("./cats_dogs"):
#获取音频时间序列和采样率
y, sr = librosa.load("./cats_dogs/"+File)
#计算音频的MFCC
#MFCC的计算过程通常包括以下几个步骤:对原始信号进行傅里叶变换,以将其从时域转换到频域;接着将线性频率尺度转换为梅尔频率尺度;然后通常取其对数并施加离散余弦变换(DCT),最终得到倒谱系数。
MFCC = librosa.feature.mfcc(y=y, sr=sr,n_mfcc=100)
#计算MFCC的平均值作为特征
Features.append(np.mean(MFCC, axis=1))
if File[0]=='c':
Labels.append(0)
else:
Labels.append(1)
Features=np.array(Features)
Labels=np.array(Labels)
#构建高斯混合模型
GMM=GaussianMixture(n_components=2,covariance_type='full',tol=1e-3,reg_covar=1e-6,max_iter=100,n_init=1,random_state=2)
#通过期望最大化算法对模型进行聚类并预测
GMM.fit(Features)
Predictions = GMM.predict(Features)
#输出测试的准确率
Accuracy = accuracy_score(Labels, Predictions)
print(confusion_matrix(Labels,Predictions))
print("Accuracy:", Accuracy)1.默认参数
首先用的是默认参数,两个单高斯模型,每个分量有不同的协方差矩阵,收敛阈值1e-3,协方差正则化参数1e-6,EM算法最大迭代次数100,随机初始化1次,随机数种子=2,初始化参数方法Kmeans
结果:
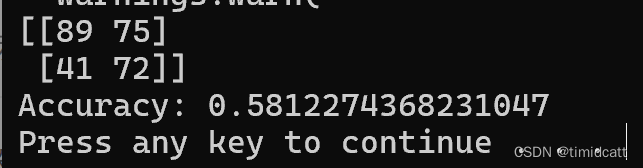
通过混淆矩阵可以看出,狗的正确率达到了64%,而猫的正确率只有54%,这个差距应该和数据集有关,标注为狗的音频质量比猫要高一些
2.协方差正则化参数
先改这个参数的原因是本来想先改协方差矩阵,但是改了后发现提示拟合失败,建议提高正则化参数,以下是正则化参数=[1e-6,1e-5,1e-4,1e-3,1e-2,1e-1,1]时的结果
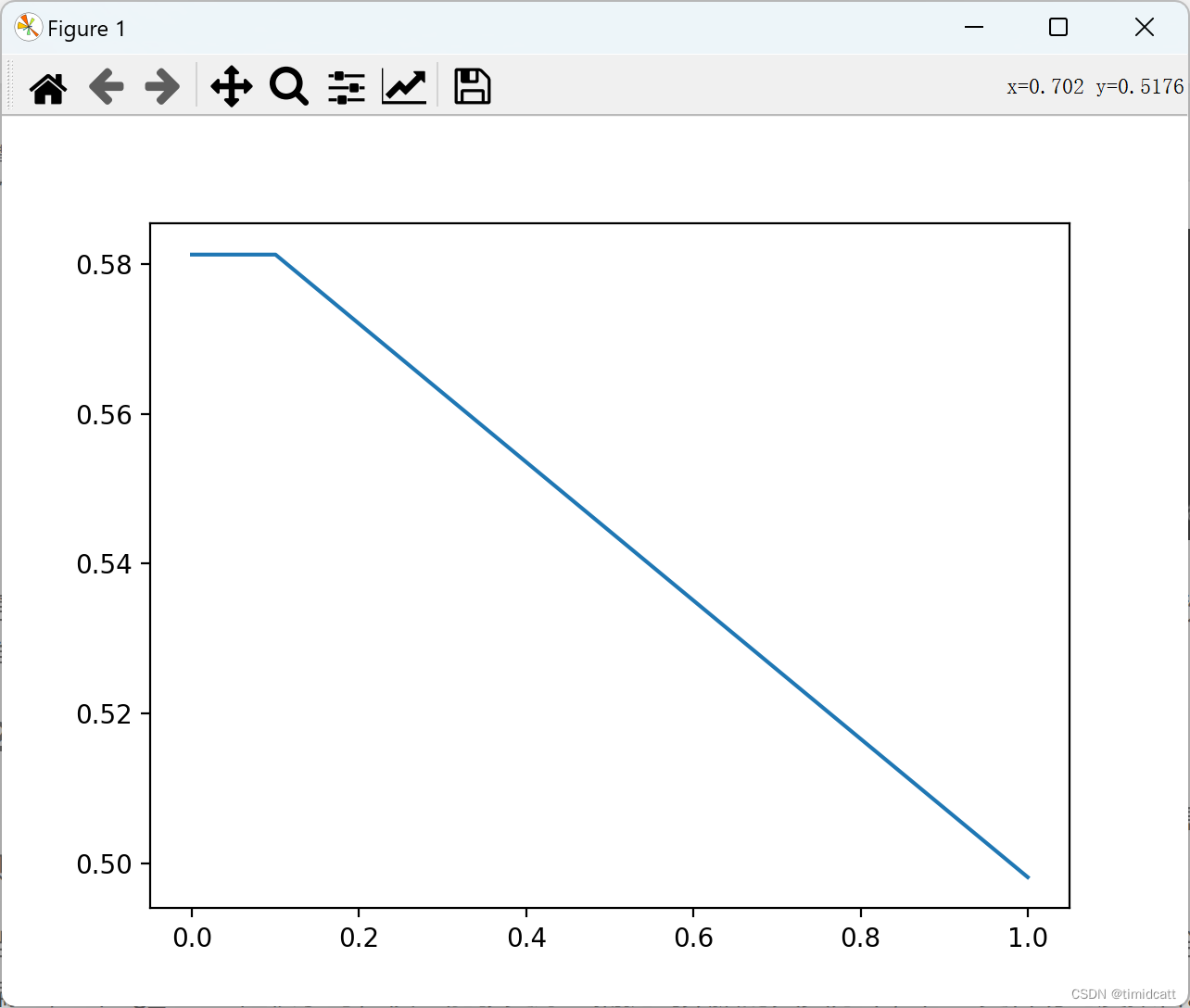
只有等于1时出现了准确率下降,其他值时对准确率没有影响
从理论上来说,当正则化参数较大时,协方差矩阵会更倾向于接近于0,有助于减少模型复杂度,可以避免过拟合,但可能会引入偏差,而且本实验因为数据集很小,所以没有分训练集和测试集;当正则化参数值较小时,模型能够更好地捕捉到数据的真实分布,但也容易过度拟合,也可能因为过于复杂出现拟合失败。
后续实验中采用1e-5这个值,在保证不会拟合失败的前提下增加模型的复杂度
3.协方差类型
协方差类型决定了模型在处理特征间的相关性和数据分布的假设,采用了4种协方差矩阵模式,[full,tied,diag,spherical]
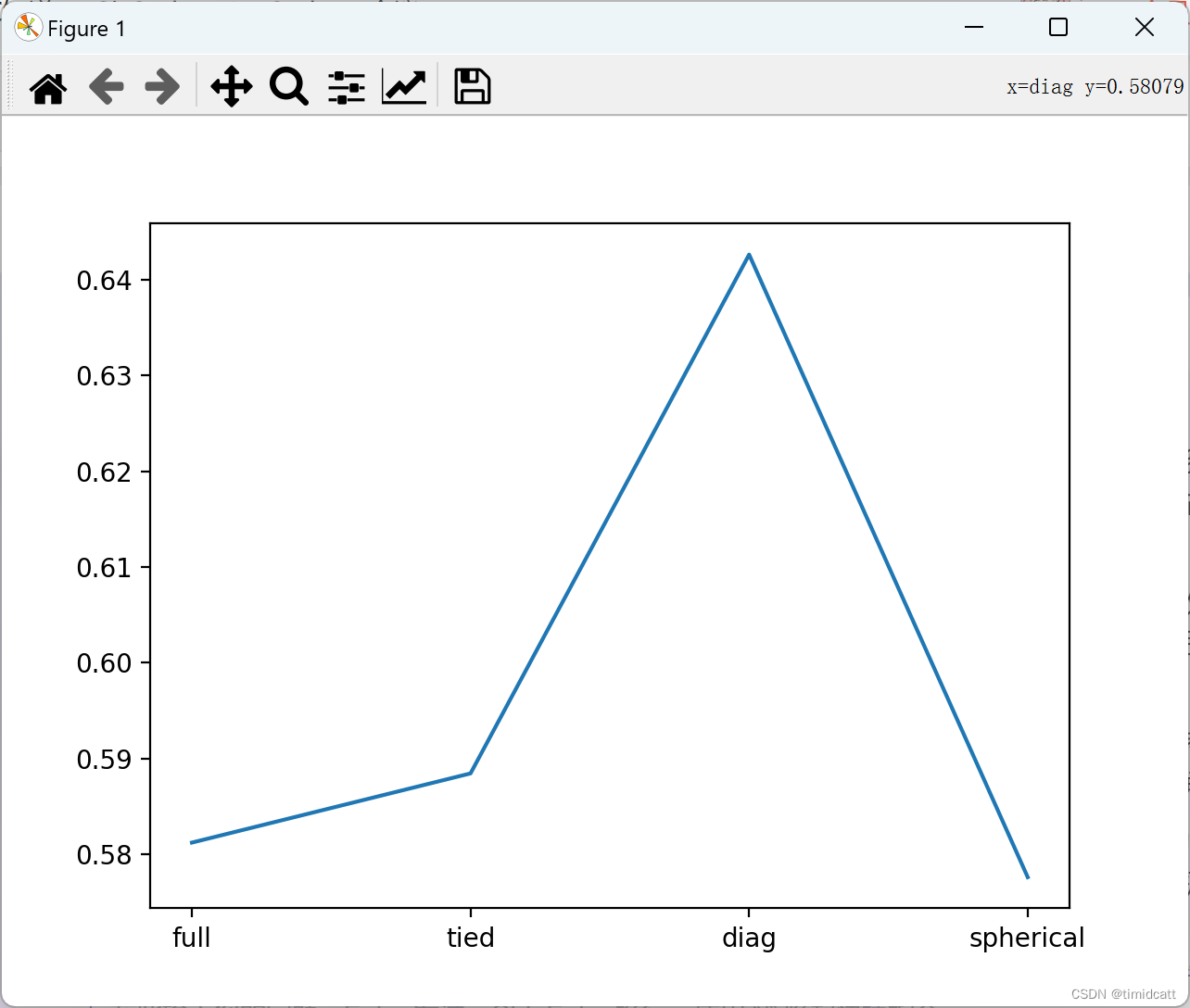
完全协方差(full)中 每个高斯分量都拥有独立的一般协方差矩阵,能够处理分量间复杂的形状和方向差异,需要估计更多的参数。
共享协方差(tied)中所有高斯分量共享同一个一般协方差矩阵。减少了需要估计的参数数量,降低了模型复杂性。
对角协方差(diag)中协方差矩阵只有对角线上的元素是非零,这意味着模型只考虑每个特征与自身的方差,忽略了特征间的协方差,进一步减少了模型的复杂度。
球形协方差 (‘spherical’)中每个高斯分量具有相同的球形协方差,更进一步简化了模型。是参数设置中最简单的模型,计算需求最低。
从图表中可以看出大致趋势是模型复杂度越低准确率越高,这可能是因为该数据集的质量过低导致的,而球形协方差复杂度过低也会导致拟合准确率下降,后续实验都采用效果最好的对角协方差。
4.容忍度和最大迭代次数
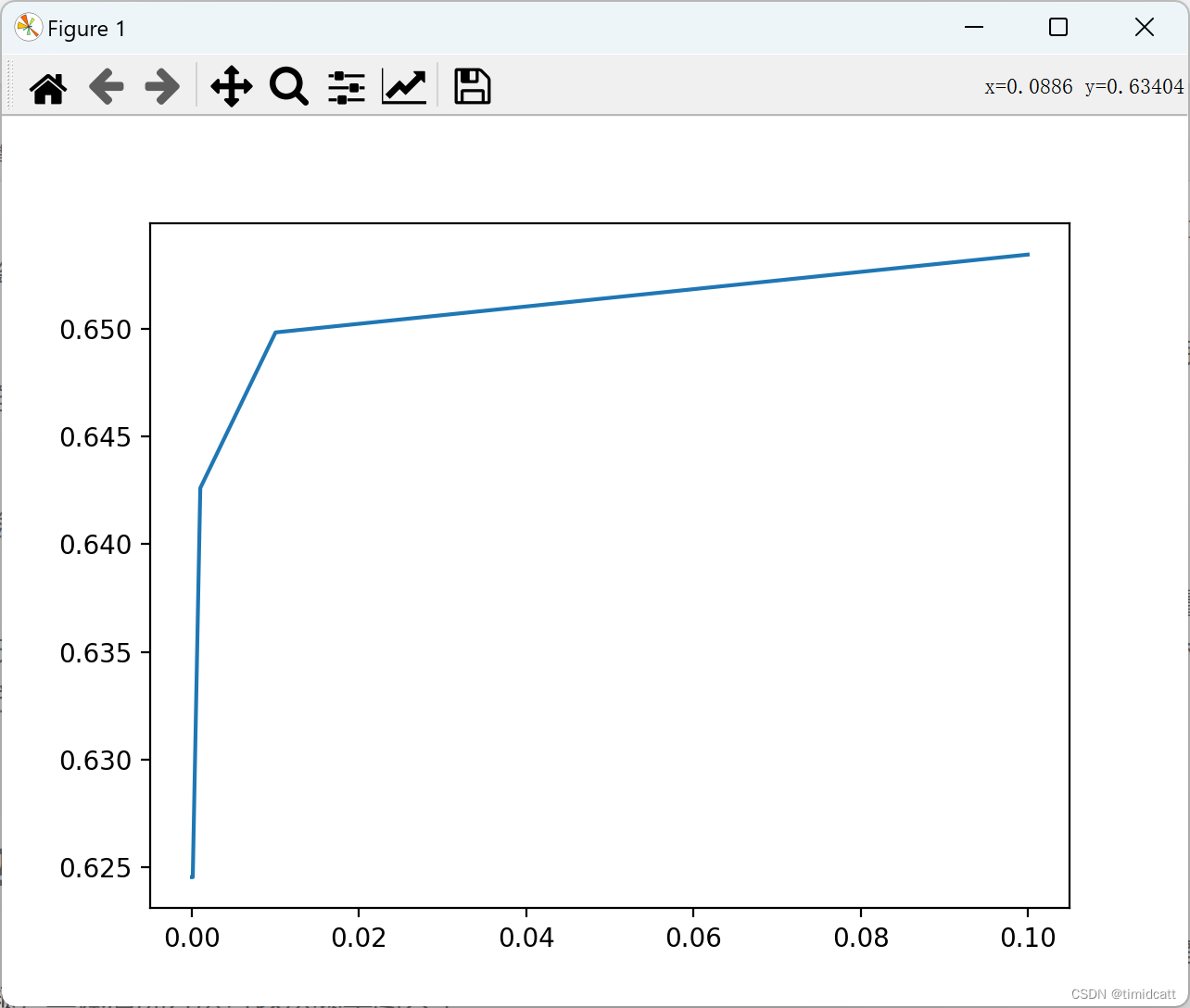
容忍度(tolerance)参数,用于控制在期望最大化算法迭代过程中,似然性或下界的变化小于何值时阈值时收敛。我们得到的结果是容忍度越大准确率越高,而在低于1e-3时也没有zh,可能依然时因为数据集质量过低,算的多反而不准确,后续实验采用准确率最高的1e-3。
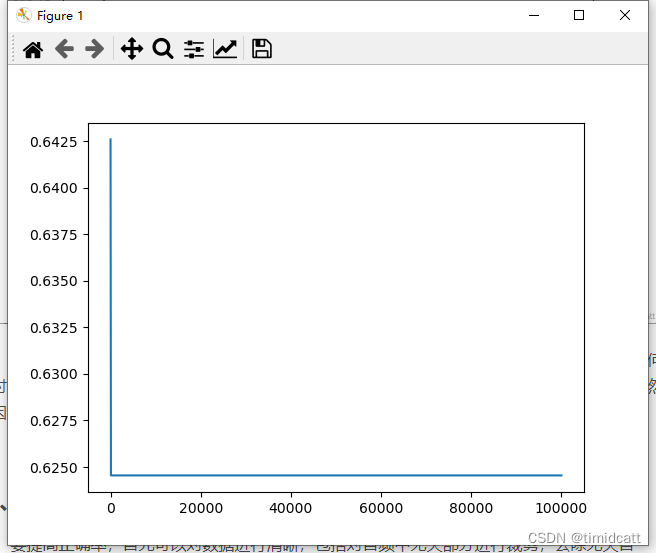
最大迭代次数(max_iter)指的是期望最大化算法在达到该迭代次数后,即使没有满足容忍度,也会提前终止,该结果同样证明了对于该数据集来说算的越多准确率可能越低
5.初始化次数
初始化次数决定了算法尝试寻找模型最佳参数的次数,在调整次数之前先取消设定随机数种子
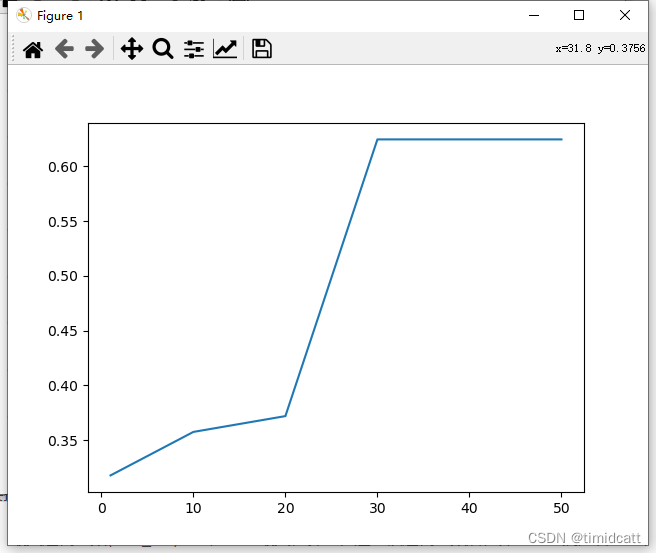
通过多次初始化,可以降低模型因单次不幸运的初始化导致收敛到局部最优或不合理的结果的风险。所以提高初始化次数可以一定程度上的提高准确率,单不需要过高,因为其会明显影响运算时间
四、改进方向
要提高正确率,首先可以对数据进行清晰,包括对音频中无关部分进行裁剪,去除无关音频,具体清洗方法也许可以从频率图入手
其次可以对GMM模型进行调参,以及尝试使用频率作为特征等



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











