






1 决策树的概念
顾名思义,决策树就是一棵树,一颗决策树包含一个根节点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集,从根结点到每个叶子结点的路径对应了一个判定测试序列。
决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
判断好瓜坏瓜的决策树:
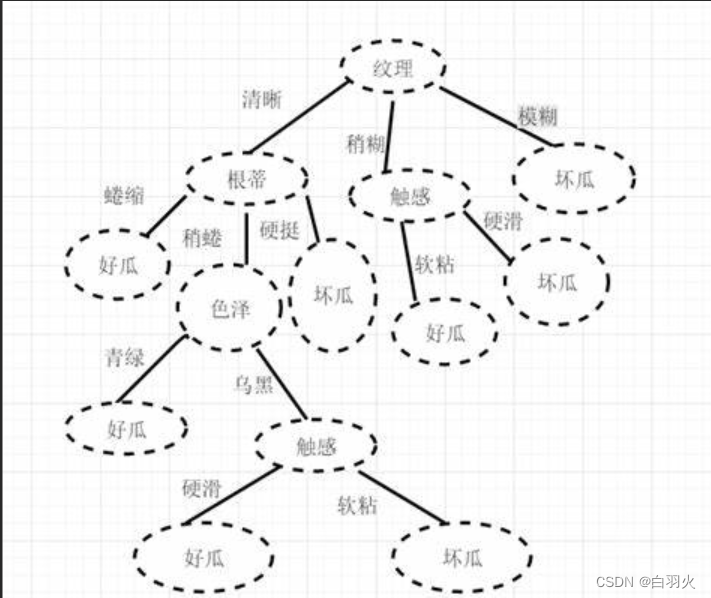
2 划分数据集
划分数据集的大原则是:将无序的数据变的更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。决策树学习的关键在于如何选择最优划分属性。经典的属性划分方法有:信息增益(ID3)、增益率(C4.5)、基尼指数(CART)。
2.1 信息增益
度量特征的纯度就需要用到”信息熵“,信息熵公式如下:
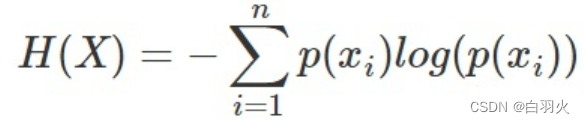
H(x)的值越小,则x的纯度越高。
为了计算熵,我们需要计算所有类别所有可能包含的信息期望值,n是分类的数目。
3 实现决策树
3.1 数据集
创建txt数据集
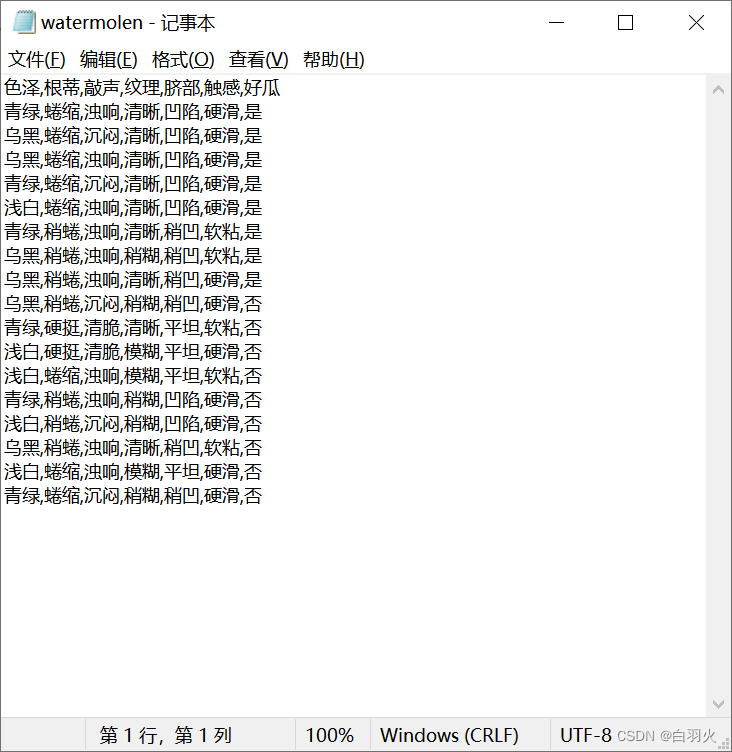
代码实现
import graphviz
import numpy as np
import pandas as pd
from sklearn import tree
data = pd.read_csv('D:\作业\大数据\watermolen.txt')
data.head(10)
data['色泽']=data['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
data['根蒂']=data['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
data['敲声']=data['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
data['纹理']=data['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
data['脐部']=data['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
data['触感'] = np.where(data['触感']=="硬滑",1,2)
data['好瓜'] = np.where(data['好瓜']=="是",1,0)
x_train=data[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=data['好瓜']
print(data)
Tree=tree.DecisionTreeClassifier(criterion='entropy')
Tree=Tree.fit(x_train,y_train)
# print(Tree)
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = tree.export_graphviz(Tree,feature_names=labels,class_names=["好瓜","坏瓜"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph.render('graph', view=True) 运行结果及绘制的效果图
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









