







目录
今天是1024,首先,祝大家节日快乐! 中文句法分析,先分析下面的一句话再进入正题哈哈:博客技术交流加QQ群:955817470
分析结果如下:
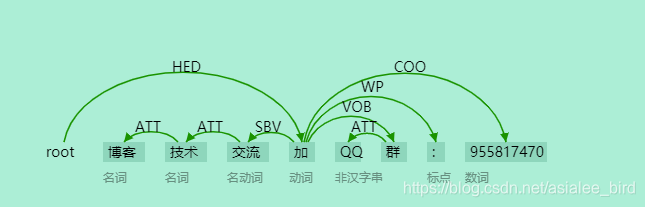
从分析结果我们可以看到每个词的词性以及句法结构,比如:交流和加这两个词构成了主谓关系(SBV),加和群这两个词构成了动宾关系(VOB),通过该结果可以分析句子的组成成分等。这个其实就是依存句法分析的一个例子,接下来看正文 ……
一、中文句法分析内容概述
主要任务:
- 词法分析:分句、分词、词性标注、命名实体识别
- 句法分析:依存句法分析
- 语义分析:语义角色标注、语义依存分析
1、分句
一般可以根据标点符号正则表达式进行分句。
2、分词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
3、词性标注
词性(part-of-speech)是词汇基本的语法属性,通常也称为词性。
词性标注(part-of-speech tagging)又称为词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。词性标注是很多NLP任务的预处理步骤,如句法分析,经过词性标注后的文本会带来很大的便利性,但也不是不可或缺的步骤。
词性标注主要可以分为基于规则和基于统计的方法,下面列举几种统计方法:基于最大熵的词性标注、基于统计最大概率输出词性、基于HMM的词性标注。
词性标注的应用:句法分析预处理、词汇获取预处理、信息抽取预处理。
4、命名实体识别
命名实体识别(Named Entity Recognition,NER)是将文本中的元素分成预先定义的类,如人名、地名、 机构名、时间、货币等等。作为自然语言的承载信息单位,命名实体识别 属于文本信息处理的基础的研究领域,是信息抽取、信息检索、机器翻译、 问答系统等多种自然语言处理技术中必不可少的组成部分。
5、依存句法分析
依存语法 (Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
6、语义角色标注
语义角色标注(Semantic Role Labeling,SRL)是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等。其能够对问答系统、信息抽取和机器翻译等应用产生推动作用。
7、语义依存分析
语义依存分析 (Semantic Dependency Parsing, SDP),分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。 使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。
语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。
二、基于Python的LTP句法分析
1、LTP基础
LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等工作。
2、pyltp安装
环境:Linux
准备:LTP模型下载
安装pyltp:pip install pyltp
注:安装成功之后,尝试import pyltp,可能报错:undefined symbol: _ZTISt19__codecvt_utf8_baseIwE
解决方法如下(参看方法):
cd ~/anaconda2/lib
rm libstdc++.so.6.0.19
ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6 libstdc++.so.6.0.193、pyltp实现句法分析
pyltp实现分句、分词、词性标注、命名实体识别、依存句法分析、语义角色标注,代码如下(ltp_analyze.py):
#!/usr/bin/env python
# coding=utf-8
import importlib,sys
importlib.reload(sys)
import os
from pyltp import SentenceSplitter,Segmentor, Postagger, NamedEntityRecognizer, Parser,SementicRoleLabeller,CustomizedSegmentor
#分句
def sentence_split(text):
sents = SentenceSplitter.split(text) # 分句
print('\n'.join(sents))
class LtpModelAnalysis(object):
def __init__(self, model_dir="/mnt/f/model/ltp_model/ltp_data_v3.4.0/"):
self.segmentor = Segmentor()
self.segmentor.load(os.path.join(model_dir, "cws.model")) #加载分词模型
#使用自定义词典
#self.segmentor.load_with_lexicon(os.path.join(model_dir, "cws.model"), 'lexicon') # 加载分词模型,第二个参数是外部词典文件路径
#使用个性化分词模型 #pyltp支持使用用户训练好的个性化模型
#customized_segmentor = CustomizedSegmentor() # 初始化实例
#customized_segmentor.load(os.path.join(model_dir, "cws.model"), 'customized_model') # 加载模型,第二个参数是增量模型的路径
#个性化分词模型的同时也可以使用外部词典
#customized_segmentor = CustomizedSegmentor() # 初始化实例
#customized_segmentor.load_with_lexicon(os.path.join(model_dir, "cws.model"), 'customized_model','lexicon')
self.postagger = Postagger()
self.postagger.load(os.path.join(model_dir, "pos.model")) #加载词性标注模型
self.recognizer=NamedEntityRecognizer()
self.recognizer.load(os.path.join(model_dir, "ner.model")) #加载命名实体识别模型
self.parser = Parser()
self.parser.load(os.path.join(model_dir, "parser.model")) #加载依存句法分析模型
self.labeller=SementicRoleLabeller()
self.labeller.load(os.path.join(model_dir, "pisrl.model")) #加载语义角色标注模型
def analyze(self, text):
#分词
words = self.segmentor.segment(text)
print( '\t'.join(words))
#词性标注
postags = self.postagger.postag(words)
print( '\t'.join(postags))
#命名实体识别
netags = self.recognizer.recognize(words, postags) # 命名实体识别
print('\t'.join(netags))
#句法分析
arcs = self.parser.parse(words, postags)
print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs)) #arc.head 表示依存弧的父节点词的索引,arc.relation 表示依存弧的关系。
arcs_list=[]
#语义角色标注
roles = self.labeller.label(words, postags, arcs) #arcs 使用依存句法分析的结果
for role in roles:
print(role.index, "".join(["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
def release_model(self):
# 释放模型
self.segmentor.release()
self.postagger.release()
self.recognizer.release()
self.parser.release()
self.labeller.release()
if __name__ == '__main__':
text="你觉得我的博客写的怎么样?进一步交流请加QQ群:955817470"
ltp = LtpModelAnalysis()
ltp.analyze(text)
ltp.release_model()
#sentence_split(text)分词、词性标注、命名实体识别、依存句法分析、语义角色标注运行结果如下

(1)依存句法结果分析
2:SBV 0:HED 5:ATT 3:RAD 6:SBV 8:ATT 6:RAD 2:VOB 2:WP 11:ADV 2:COO 11:COO 12:VOB 15:ATT 13:VOB 15:WP 13:COOarc.head表示依存弧的父节点词的索引。ROOT节点的索引是0,第一个词开始的索引依次为1、2、3…arc.relation表示依存弧的关系。
(2)语音角色标注结果分析
1 A0:(0,0)A1:(2,7)
5 A1:(2,4)
10 ADV:(9,9)A1:(13,15)
11 A2:(12,16)
12 A1:(13,15)- 第一个词开始的索引依次为0、1、2…
- 返回结果
roles是关于多个谓词的语义角色分析的结果。由于一句话中可能不含有语义角色,所以结果可能为空。 role.index代表谓词的索引,role.arguments代表关于该谓词的若干语义角色。arg.name表示语义角色类型,arg.range.start表示该语义角色起始词位置的索引,arg.range.end表示该语义角色结束词位置的索引。
三、基于C++的LTP句法分析
1、LTP源码和模型
2、LTP的C++源码编译及测试
./configure
make编译成功后,会在 bin 目录下生成以下二进制程序
| 程序名 | 说明 |
|---|---|
ltp_test | LTP主程序 |
ltp_server | LTP Server |
在 bin/examples 目录下生成以下二进制程序
| 程序名 | 说明 |
|---|---|
cws_cmdline | 分词模块命令行程序 |
pos_cmdline | 词性标注模块命令行程序 |
ner_cmdline | 命名实体识别模块命令行程序 |
par_cmdline | 依存句法分析模块命令行程序 |
在 examples 目录下有C++源码和Makefile文件
使用pos_cmdline完成词性标注测试
$ cat input
这 是 测试 样本 ,中文 句法 分析 。
$ cat input | ./bin/examples/pos_cmdline --postagger-model ./ltp_model/pos.model
TRACE: Model is loaded
TRACE: Running 1 thread(s)
WARN: Cann't open file! use stdin instead.
这_r 是_v 测试_v 样本_n ,中文_nz 句法_n 分析。_v
TRACE: consume 0.162231 seconds.3、在Linux下使用动态库生成可执行程序
(1)分词cws.cpp代码如下
#include <iostream>
#include <string>
#include "ltp/segment_dll.h"
int main(int argc, char * argv[])
{
if (argc < 2) //命令行参数,没有分词模型的情况下输出
{
std::cerr << "cws [model path] [lexicon_file]" << std::endl;
return 1;
}
void * engine = 0; //声明一个指向模型的指针
if (argc == 2) //第一个命令行参数,为分词模型
{
engine = segmentor_create_segmentor(argv[1]); //分词接口,初始化分词器
}
else if (argc == 3) //第二个命令行参数,可以外加词典文件
{
engine = segmentor_create_segmentor(argv[1], argv[2]); //分词接口,初始化分词器
}
if (!engine)
{
return -1;
}
std::vector<std::string> words; //将分词结果存入vector中
//分词的文本
const char * suite[2] = {
"What's wrong with you? 别灰心! http://t.cn/zQz0Rn", "台北真的是天子骄子吗?",};
for (int i = 0; i < 2; ++ i) {
words.clear();
int len = segmentor_segment(engine, suite[i], words); //分词接口,对句子分词。
for (int i = 0; i < len; ++ i) {
std::cout << words[i];
if (i+1 == len) std::cout <<std::endl;
else std::cout<< "|";
}
}
segmentor_release_segmentor(engine); //分词接口,释放分词器
return 0;
}(2)生成cws可执行程序
将下载的LTP置于 ltp-project 目录下,编译命令如下
$ g++ -o cws cws.cpp -I ../include/ -I ../thirdparty/boost/include/ -Wl,-dn -L ../lib/ -lsegmentor -lboost_regex -Wl,-dy运行生成的可执行程序
$ cws ../ltp_model/cws.model运行结果如下:
- What's|wrong|with|you|?|别|灰心|!|Sina Visitor System
- 台北|真|的|是|天子骄子|吗|?
4、 构建基于LTP的句法分析类Parsing
#include <iostream>
#include <vector>
#include "ltp/segment_dll.h"
#include "ltp/postag_dll.h"
#include "ltp/parser_dll.h"
using namespace std;
//构建LTP句法分析类
class Parsing
{
public:
void* cws_engine = 0;
void* pos_engine = 0;
void* par_engine = 0;
vector<string> words;
vector<string> postags;
vector<int> heads;
vector<string> deprels;
public:
void get_models(char* cws, char* pos, char* par);
void get_words(string str);
void get_postags(string str);
void get_parsing(string str);
void release_model();
};
//加载模型文件
void Parsing::get_models(char* cws,char* pos,char* par)
{
cws_engine = segmentor_create_segmentor(cws);
pos_engine = postagger_create_postagger(pos);
par_engine = parser_create_parser(par);
}
//分词
void Parsing::get_words(string str)
{
words.clear();
segmentor_segment(cws_engine, str, words);
}
//词性标注
void Parsing::get_postags(string str)
{
words.clear();
postags.clear();
segmentor_segment(cws_engine, str, words);
postagger_postag(pos_engine, words, postags);
}
//句法分析
void Parsing::get_parsing(string str)
{
words.clear();
postags.clear();
heads.clear();
deprels.clear();
segmentor_segment(cws_engine, str, words);
postagger_postag(pos_engine, words, postags);
parser_parse(par_engine, words, postags, heads, deprels);
}
//释放模型
void Parsing::release_model()
{
segmentor_release_segmentor(cws_engine);
postagger_release_postagger(pos_engine);
parser_release_parser(par_engine);
}
int main(int argc, char * argv[])
{
Parsing pars;
//pars.get_models("/mnt/f/ltp_project/ltp_model/cws.model","/mnt/f/ltp_project/ltp_model/pos.model","/mnt/f/ltp_project//ltp_model/parser.model");
pars.get_models(argv[1],argv[2],argv[3]);
//cout<<"测试代码"<<endl;
pars.get_parsing("Welcome to my blog!");
cout<<pars.words.size()<<endl;
for (int i = 0; i < pars.words.size(); i++)
{
cout << pars.words[i]<<'\t'<<pars.postags[i]<<'\t'<<pars.heads[i]<<'\t'<<pars.deprels[i]<< endl;
//cout << pars.postags[i] << endl;
//cout << pars.heads[i] << endl;
//cout << pars.deprels[i] << endl;
}
pars.release_model();
return 0;
}
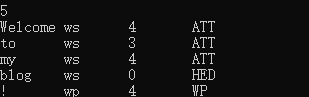
5、使用Parsing类实现句法分析
生成Parsing可执行程序
$ g++ -o parsing parsing.cpp -I ../include/ -I ../thirdparty/boost/include/ -Wl,-dn -L ../lib/ -lsegmentor -lpostagger -lparser -lboost_regex -Wl,-dy运行Parsing可执行程序
$ ./parsing ../ltp_model/cws.model ../ltp_model/pos.model ../ltp_model/parser.model运行结果如下
四、LTP标注集参考
1、词性标注集
LTP 使用的是863词性标注集,其各个词性含义如下表
| Tag | Description | Example | Tag | Description | Example |
|---|---|---|---|---|---|
| a | adjective | 美丽 | ni | organization name | 保险公司 |
| b | other noun-modifier | 大型, 西式 | nl | location noun | 城郊 |
| c | conjunction | 和, 虽然 | ns | geographical name | 北京 |
| d | adverb | 很 | nt | temporal noun | 近日, 明代 |
| e | exclamation | 哎 | nz | other proper noun | 诺贝尔奖 |
| g | morpheme | 茨, 甥 | o | onomatopoeia | 哗啦 |
| h | prefix | 阿, 伪 | p | preposition | 在, 把 |
| i | idiom | 百花齐放 | q | quantity | 个 |
| j | abbreviation | 公检法 | r | pronoun | 我们 |
| k | suffix | 界, 率 | u | auxiliary | 的, 地 |
| m | number | 一, 第一 | v | verb | 跑, 学习 |
| n | general noun | 苹果 | wp | punctuation | ,。! |
| nd | direction noun | 右侧 | ws | foreign words | CPU |
| nh | person name | 杜甫, 汤姆 | x | non-lexeme | 萄, 翱 |
2、命名实体识别标注集
LTP 采用 BIESO 标注体系。B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成命名实体。
LTP 提供的命名实体类型为:人名(Nh)、地名(Ns)、机构名(Ni)
| 标记 | 含义 |
|---|---|
| O | 这个词不是NE |
| S | 这个词单独构成一个NE |
| B | 这个词为一个NE的开始 |
| I | 这个词为一个NE的中间 |
| E | 这个词位一个NE的结尾 |
3、依存句法关系
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <– 送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花 (送 –> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花 (送 –> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读 (书 <– 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 –> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <– 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <– 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 –> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 –> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 –> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <– 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 –> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
4、语义角色类型
| 语义角色类型 | 说明 |
|---|---|
| ADV | adverbial, default tag ( 附加的,默认标记 ) |
| BNE | beneficiary ( 受益人 ) |
| CND | condition ( 条件 ) |
| DIR | direction ( 方向 ) |
| DGR | degree ( 程度 ) |
| EXT | extent ( 扩展 ) |
| FRQ | frequency ( 频率 ) |
| LOC | locative ( 地点 ) |
| MNR | manner ( 方式 ) |
| PRP | purpose or reason ( 目的或原因 ) |
| TMP | temporal ( 时间 ) |
| TPC | topic ( 主题 ) |
| CRD | coordinated arguments ( 并列参数 ) |
| PRD | predicate ( 谓语动词 ) |
| PSR | possessor ( 持有者 ) |
| PSE | possessee ( 被持有 ) |
参考:
本人博文NLP学习内容目录:
一、NLP基础学习
二、NLP项目实战
交流学习资料共享欢迎入群:955817470(群一),801295159(群二)


















 2059
2059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











