







 Orca解析查询生成内存中的逻辑表达式树,并进行逻辑等价变换。在探索阶段,新表达式被添加到组中,可能创建新组。Orca使用统计派生机制计算Memo组的统计信息,主要基于列直方图估算基数和倾斜。优化过程涉及成本计算和物理实现的选择,如哈希join和嵌套循环join。优化请求会被缓存,以提高效率。
Orca解析查询生成内存中的逻辑表达式树,并进行逻辑等价变换。在探索阶段,新表达式被添加到组中,可能创建新组。Orca使用统计派生机制计算Memo组的统计信息,主要基于列直方图估算基数和倾斜。优化过程涉及成本计算和物理实现的选择,如哈希join和嵌套循环join。优化请求会被缓存,以提高效率。
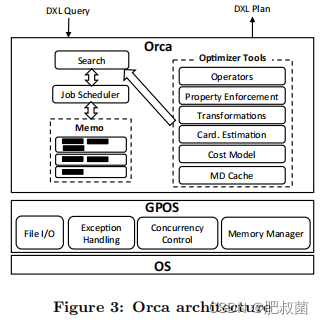
- DXL query messages is parsed and transformed to an in-memory logical expression tree that is copied-in to the Memo
- Exploration 触发生成逻辑等价表达式的转换规则。探索阶段将新的群组表达式添加到现有组中,并可能创建新的组。Exploration results in adding new group expressions to existing groups and possibly creating new groups.
- Statistics Derivation Orca’s statistics derivation mechanism is triggered to compute statistics for the Memo groups. Orca中的统计对象主要是列直方图的集合,用于导出基数和数据倾斜的估计。统计数据的推导在Memo结构上进行,以避免扩展搜索空间。In order to derive statistics for a target group, Orca picks the group expression with the highest promise of delivering reliable statistics. 为了获得目标组的统计数据,Orca选择最有希望提供可靠统计数据的组表达式。 Statistics promise computation is expression-specific. Computing a confidence score for cardinality estimation is challenging due to the need to aggregate confidence scores across all nodes of a given expression. 计算基数估计的置信度分数是很困难的,因为需要在给定表达式的所有节点上聚合置信度分数。
After picking the most promising group expression in the target group, Orca recursively triggers statistics derivation on the child groups of the picked group expression. Finally, the target group’s statistics object is constructed by com�bining the statistics objects of child groups. 在目标组上选择最有希望的组表达式后,Orca递归地触发对所选组表达式的子组的统计派生。最后,结合子分组的统计对象构建目标分组的统计对象。The requested histograms are loaded on demand from the catalog through the registered MD Provider, parsed into DXL and stored in the MD Cache to service future requests. - Implementation. Transformation rules that create physical implementations of logical expressions are triggered. For example, Get2Scan rule is triggered to generate physical table Scan out of logical Get. Similarly, InnerJoin2HashJoin and InnerJoin2NLJoin rules are triggered to generate Hash and Nested Loops join implementations
- Optimization 在此步骤,执行属性并对替代计划方案进行成本计算。In this step, properties are enforced and plan alternatives are costed. Optimization starts by submitting an initial optimization request to the Memo’s root group specifying query requirements such as result distribution and sort order. 优化首先向Memo根组提交初始化请求,指定查询需求,如结果分布和排序顺序。Submitting a request r to a group g corresponds to requesting the least cost plan satisfying r with a root physical operator in g. For each incoming request, each physical group expression passes corresponding requests to child groups depending on the incoming requirements and operator’s local requirements. 对于每个传入请求,每个物理组表达式根据传入需求和操作本地需求将相应的请求传递给子组。
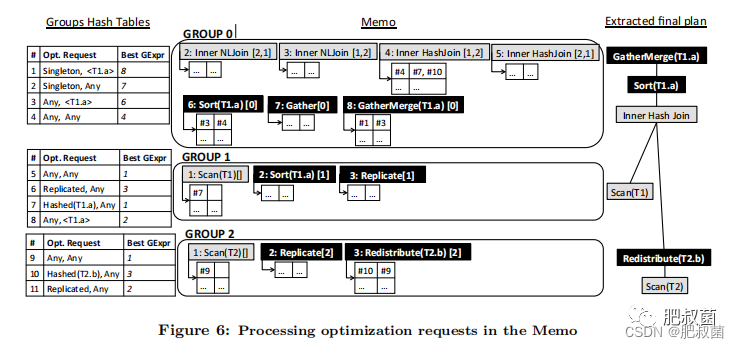

During optimization, many identical requests may be submitted to the same group. Orca caches computed requests into a group hash table. An incoming request is computed only if it does not already exist in group hash table. Additionally, each physical group expression maintains a local hash table mapping incoming requests to the corresponding child requests. Local hash tables provide the linkage structure used when extracting a physical plan from the Memo.
内容摘自
Orca: A Modular Query Optimizer Architecture for Big Data



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









