






近年来,生成式人工智能(Generative AI)的突破性发展,将大语言模型(LLM)和深度学习系统的算力需求推向了前所未有的量级。
本地部署大模型避雷区
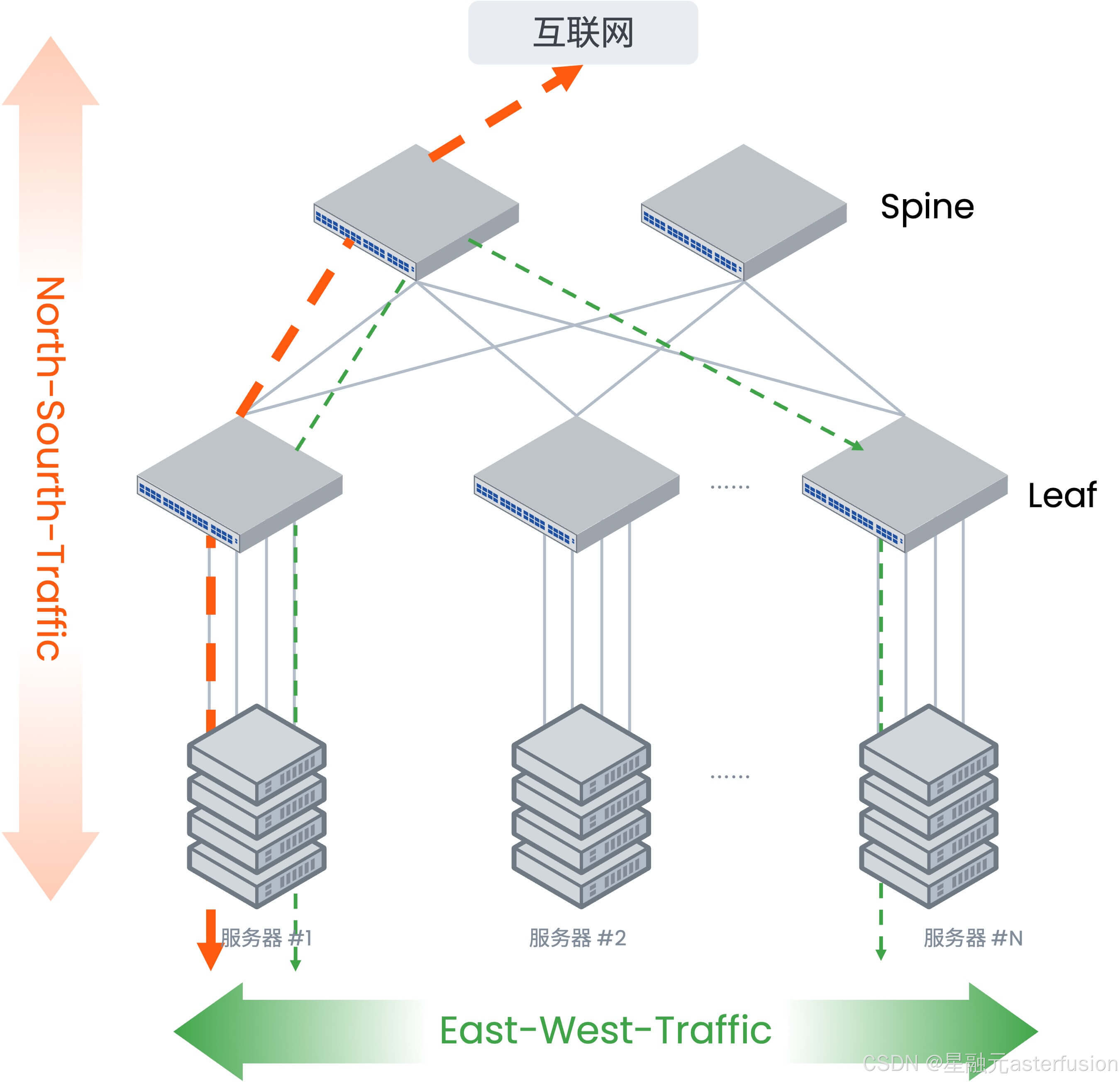 云数据中心网络的Spine-Leaf架构及流量模型
云数据中心网络的Spine-Leaf架构及流量模型
传统数据中心网络一般是基于对外提供服务的流量模型而设计的,流量主要是从数据中心到最终客户,即以南北向流量为主,云内部东西向流量为辅。承载业务网络的底层物理网络架构,对于承载智算业务存在如下挑战:
- 时延敏感型业务受限:跨节点通信依赖Spine层中转,多跳转发引入额外时延,难以满足AI训练等场景的微秒级时延要求;
- 带宽资源供给不足:受限于单物理机单网卡接入模式(商用网卡带宽普遍≤200Gbps),叠加收敛比限制,无法支撑千卡级GPU集群的全互联通信需求;
- 传输可靠性挑战:传统TCP/IP网络缺乏无损保障机制,高负载下易引发丢包,导致GPU算力空转。
AI定义网络
优化网络架构
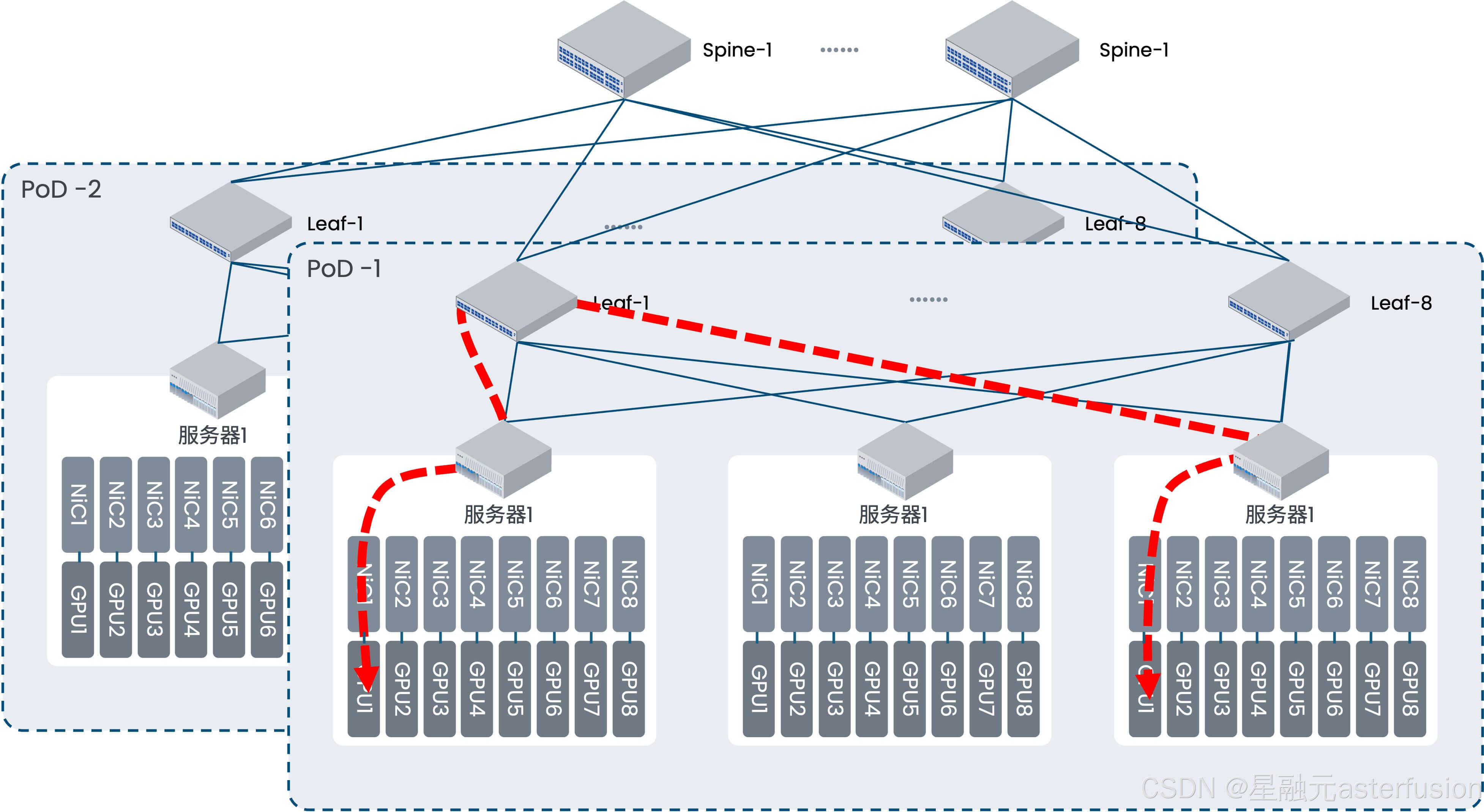 同一Pod中的计算节点间仅一跳互通
同一Pod中的计算节点间仅一跳互通
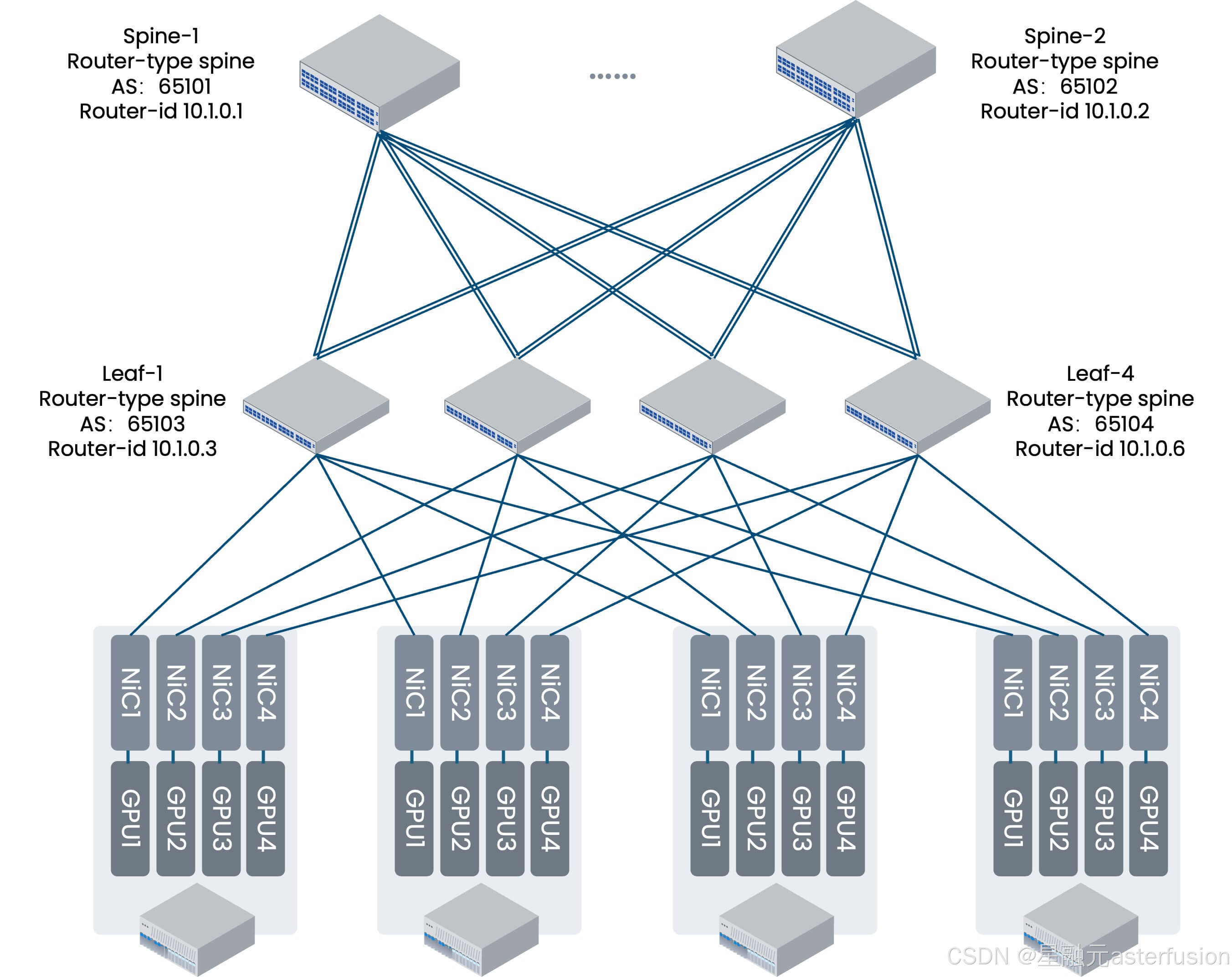
与传统方案相比,星融元智算网络方案中采用 Fat-tree CLOS架构,实现全互联无阻塞设计 ,通过ECMP(等价多路径路由)消除带宽收敛,同GPU卡号的两台智算节点间仅一跳就可互通。不同GPU编号的智算节点间,借助NCCL通信库中的Rail Local技术,可以充分利用主机内GPU间的NVSwitch的带宽,将多机间的跨卡号互通转换为跨机间的同GPU卡号的互通。
网络设备搭载AsterNOS网络操作系统,划分出计算平面(RoCEv2)、存储平面(NVMe-oF)、 控制平面(BGP/EVPN) ,实现物理资源与协议栈的垂直解耦。
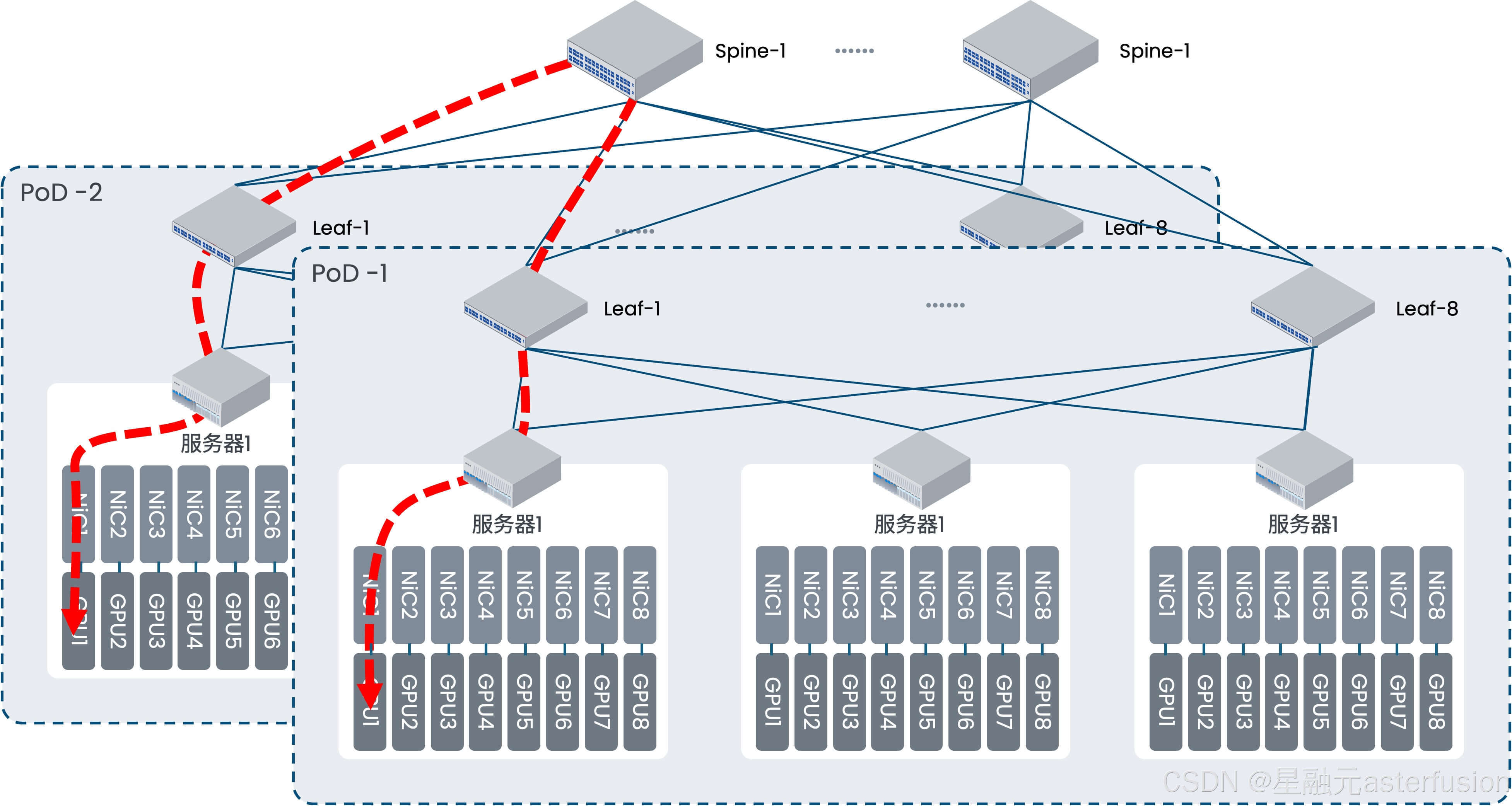
对于跨PoD的两台物理机的互通,需要过Spine交换机,此时会有 3 跳。
| 架构 | 两层胖树架构 |
| 同GPU卡号转发跳 | 1跳 |
| 不同GPU卡号转发跳数(无优化情况) | 3跳 |
如何优化配置智算网络通信路径?
首先是需要明确GPU卡的连接方式。如果是N卡,你可以使用nvidia-smi topo -m的命令直接查看。但综合考虑成本因素,要想在更为通用的智算环境下达到GPU通信最优,最好的办法还是在采购和建设初期就根据业务模型特点和通信方式预先规划好机内互联(GPU-GPU、GPU-NIC)和机间互联(GPU-NIC-GPU),避免过早出现通信瓶颈,导致昂贵算力资源的浪费。
下面我们以星融元智算网络方案具体举例,使用CX-N系列RoCE交换机组网。

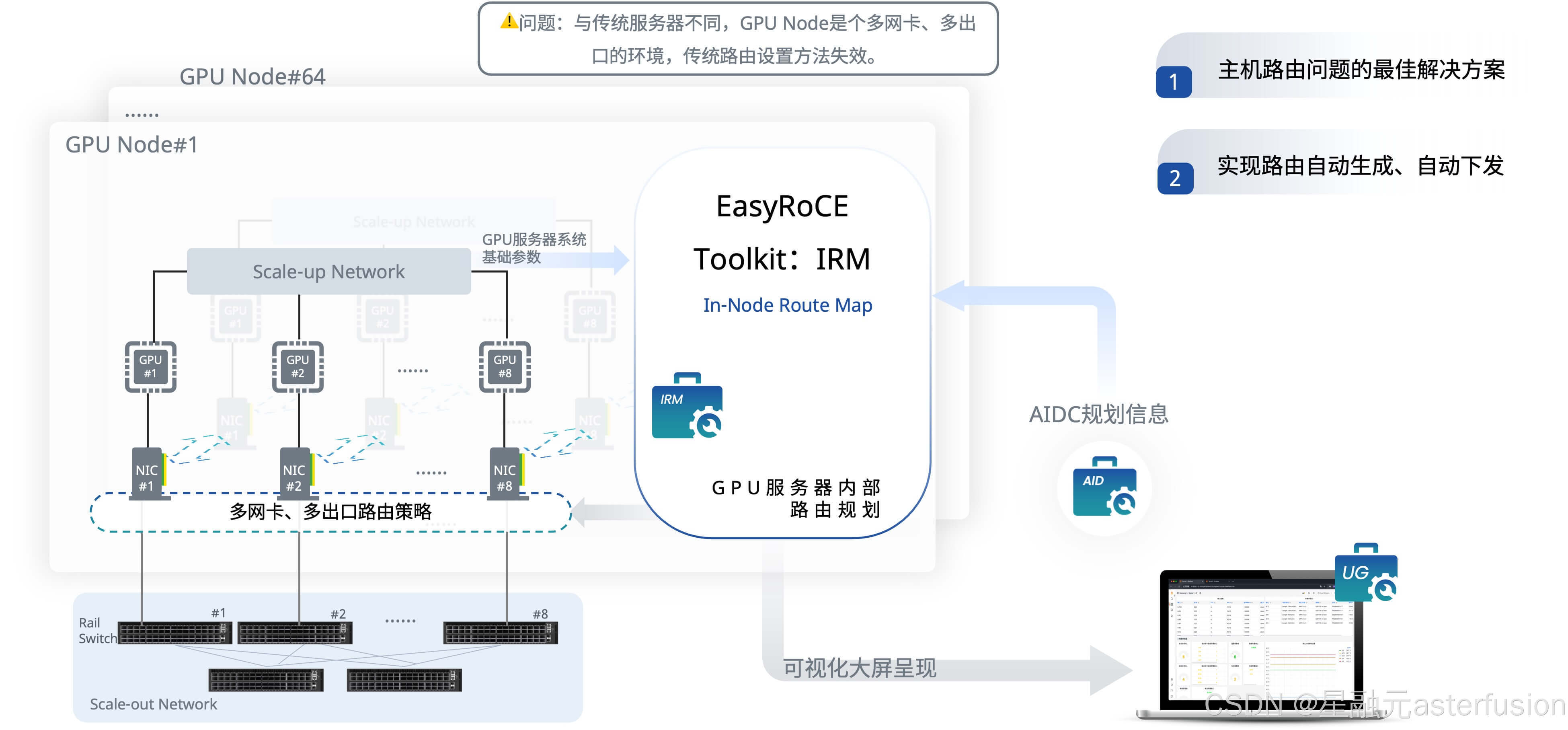
主机侧的路由配置
智算环境下以GPU卡(而非服务器)为单位的通信模式形成了服务器多网卡多出口环境的路由策略,通常会有8张网卡用于接入参数/计算网,每张网卡位于各自的轨道平面上。为避免回包通信失败,服务器上的网卡配置需要利用Linux多路由表和策略路由机制进行路由规划,这与传统云网的配置方式完全不同。
第一步是按照组网规划和网段规划,进行IP地址规划和Rail平面划分。在我们的EasyRoCE Toolkit 下的AID工具(AI Infrastructure Descriptor,AI基础设施蓝图规划)中,Notes字段用于标注Rail编号,即0代表Rail平面0、1代表Rail平面1,以此类推。
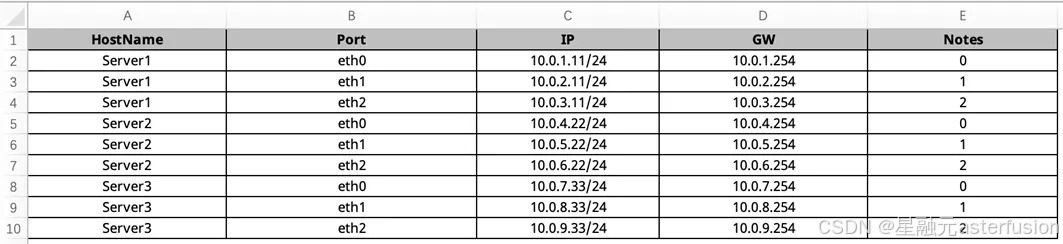 截取自星融元 EasyRoCE AID 工具
截取自星融元 EasyRoCE AID 工具
确认好了上述信息,到这里其实可以开始手动配置了,但你也可以使用另一个EasyRoCE的IRM工具(In-node Route Map,GPU内部路由规划器)。IRM 从AID 生成的配置文件中获取适合当前集群环境的路由规划信息,并且自动化地对集群中的所有GPU服务器进行IP和策略路由配置。
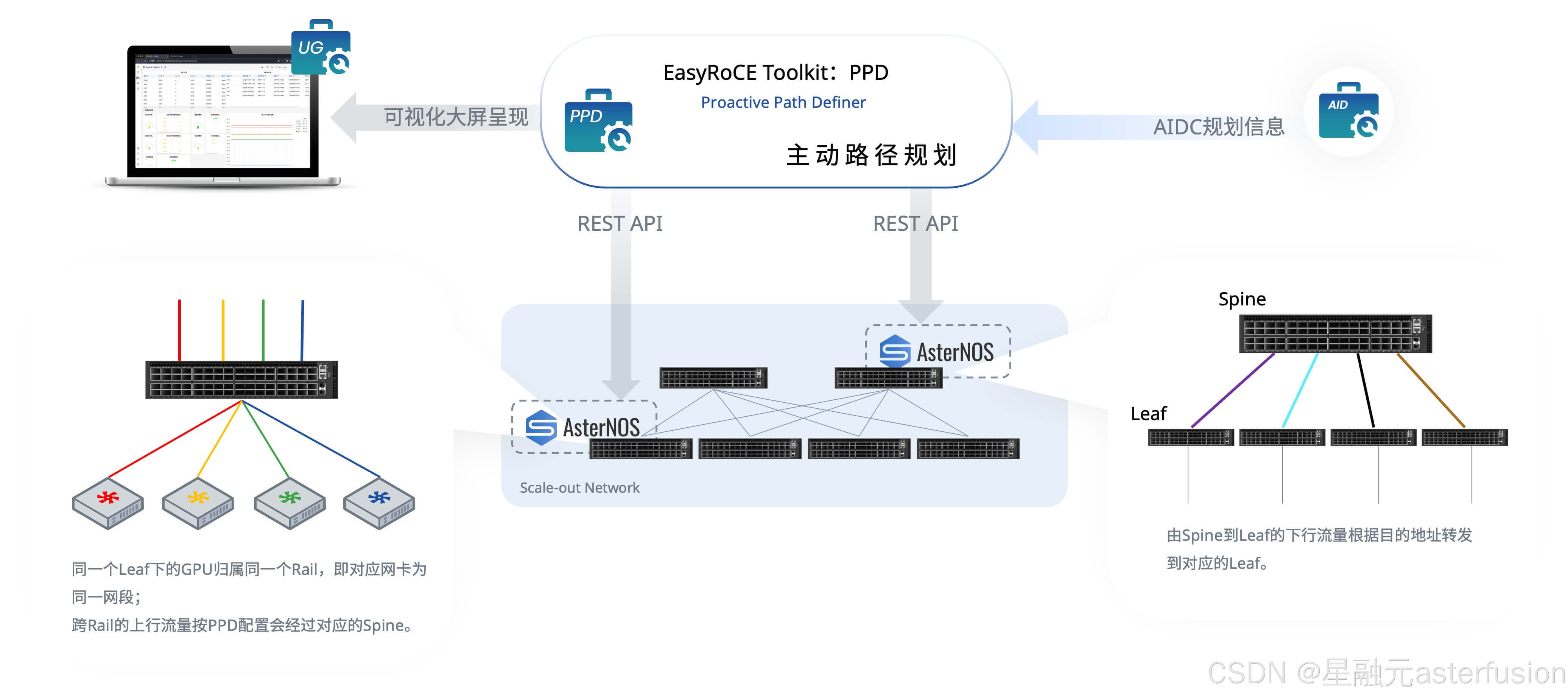
 交换机侧的主动路径规划
交换机侧的主动路径规划
CLOS架构下,各交换节点分布式运行和自我决策转发路径容易导致无法完全感知全局信息,在多层组网下流量若发生Hash极化(经过2次或2次以上Hash后出现的负载分担不均)将拖慢集群性能。
为解决满足AI集群规模化部署的通信需求,一般来说我们会通过规范流量路径来解决性能和规模方面的痛点(例如负载均衡、租户隔离等),按照如下转发逻辑去配置RoCE交换机:
- 跨 Spine上行流量进入Leaf后根据源IP和是否为跨Spine远端流量,执行策略路由转发给Spine,每网卡对应一个接口:
- 在上下行流量1:1无收敛的情况下,Leaf的每个下行端口绑定一个上行端口;
- 在n:1的情况下,上下行端口以倍数关系(向上取整)形成n:1映射。
- 跨Spine上行流量在Spine上按照标准L3逻辑转发,在轨道组网中多数流量仅在轨道内传输,跨轨道传输流量较小,网络方案暂不考虑Spine上拥塞的情况(由GPU Server集合通信处理)。
- 跨 Spine下行流量进入Leaf后根据 default 路由表指导转发。
当然,这里也可以使用EasyRoCE Toolkit下的PPD工具(主动路径规划,Proactive Path Definer)自动生成以上配置。以下为PPD工具运行过程。
正在生成配置文件
100%[#########################]
Configuring leaf1's port
leaf1的端口配置完成
Generating leaf1's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf2's port
leaf2的端口配置完成
Generating leaf2's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf3's port
leaf3的端口配置完成
Generating leaf3's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf4's port
leaf4的端口配置完成
Generating leaf4's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
show running config
是否需要查看生成的配置(Y|N):PPD可以独立运行在服务器上,也可以代码形式被集成到第三方管理软件中,利用AID工具来生成最终配置脚本,将配置呈现在统一监控面板(例如Prometheus+Grafana)进行浏览和核对。

如想了解更多方案及产品,请关注 vx:星融元Asterfusion
或官方网站:http://www.asterfusion.com
【参考文献】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









