






在分布式AI训练场景中,GPU集合通信路径是支撑多节点协同计算的核心基础设施。通过集合通信库(如NVIDIA NCCL、华为HCCL等),跨GPU的数据交换(AllReduce、Broadcast等操作)得以高效执行,从而实现大规模模型参数的同步与梯度聚合。
然而,随着智算集群规模的扩展,通信路径的复杂性呈指数级增长,暴露出以下技术难题。
-
路径黑盒化:现有集合通信库(Collective Communication Libraries, CCLs)对用户屏蔽底层通信细节(如物理拓扑、网卡绑定策略、路由选择),导致性能瓶颈难以定位。
-
异构环境兼容性:多厂商CCLs(如ACCL、TCCL)的差异化实现,增加了跨平台部署与调优的复杂度。
-
动态资源适配不足:传统静态路由规划无法适应动态负载变化,易造成网络拥塞与带宽利用率低下。
-
故障溯源低效:训练中断时,需人工排查模型、硬件、网络多层级问题,MTTR(平均修复时间)显著增加。
集合通信路径的架构解析
通信路径的层级划分
GPU集合通信路径涵盖以下核心层级:
-
节点内通信:通过NVLink/PCIe实现多GPU间P2P直连,依赖CUDA驱动层优化。
-
跨节点通信:基于RDMA(如RoCEv2)协议,通过智能网卡(如ConnectX系列)与交换机构建低延迟、高吞吐的数据通道。
-
逻辑通信环:NCCL等库根据硬件拓扑自动构建逻辑环形/树形结构,优化数据流并行性。
现有方案的局限性
尽管NCCL通过拓扑感知算法优化通信效率,但其运行时仍存在以下缺陷:
-
路径不可观测:用户无法获取通信环的实际物理路径(如交换机端口映射、QoS策略)。
-
配置僵化:缺少动态路由调整机制,无法感知网络拥塞或链路故障。
-
诊断信息碎片化:日志分散于各节点,缺乏全局视图与关联分析能力。
EPS(E2E Path Scheduler,端到端路径规划)的技术实现
架构设计目标
EPS旨在打破集合通信的“黑盒”状态,提供以下核心能力:
-
全路径可视化:实时映射逻辑通信环至物理网络拓扑。
-
智能路由优化:基于实时流量状态生成最优路径配置。
-
自动化运维:通过API驱动网络设备策略下发,减少人工干预。
关键技术模块
通信环解析与拓扑重构
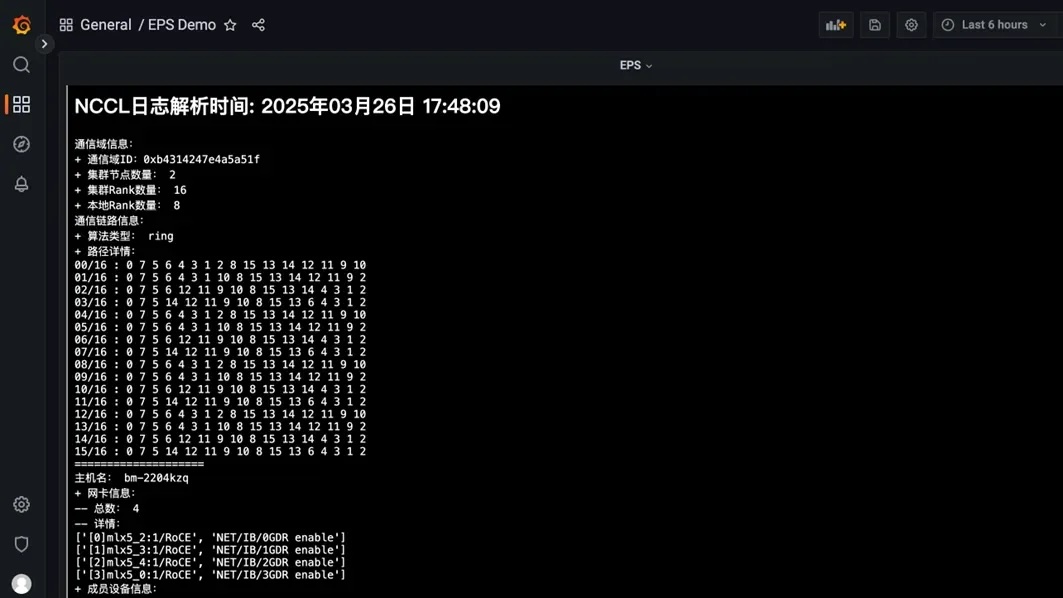
EPS通过解析NCCL日志中的ncclTopoGraph结构,提取逻辑GPU通信组(如Ring、Tree),并关联物理设备信息(GPU UUID、网卡端口号)。结合LLDP协议与交换机CLI查询,动态构建端到端路径拓扑图(如图1)。
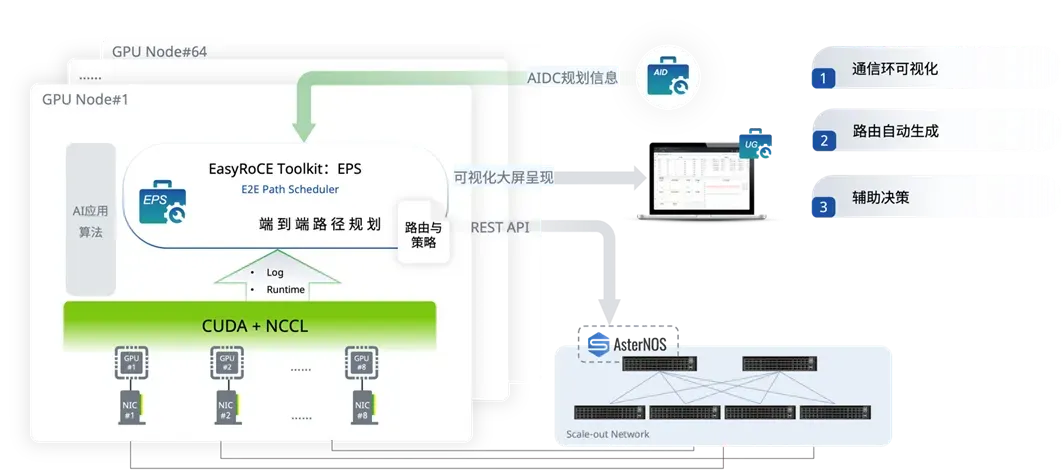 图1:EPS通信环与物理拓扑的映射示意图
图1:EPS通信环与物理拓扑的映射示意图
路由规划算法
采用混合式路径选择策略:
-
静态权重分配:基于链路带宽、延迟、丢包率构建代价模型。
-
动态负载均衡:集成Prometheus监控数据,实时感知队列深度与ECN标记,触发路径重计算。
-
容灾路由:预设多路径冗余,在链路故障时自动切换至备份路径。
如何使用 EPS?
安装配置
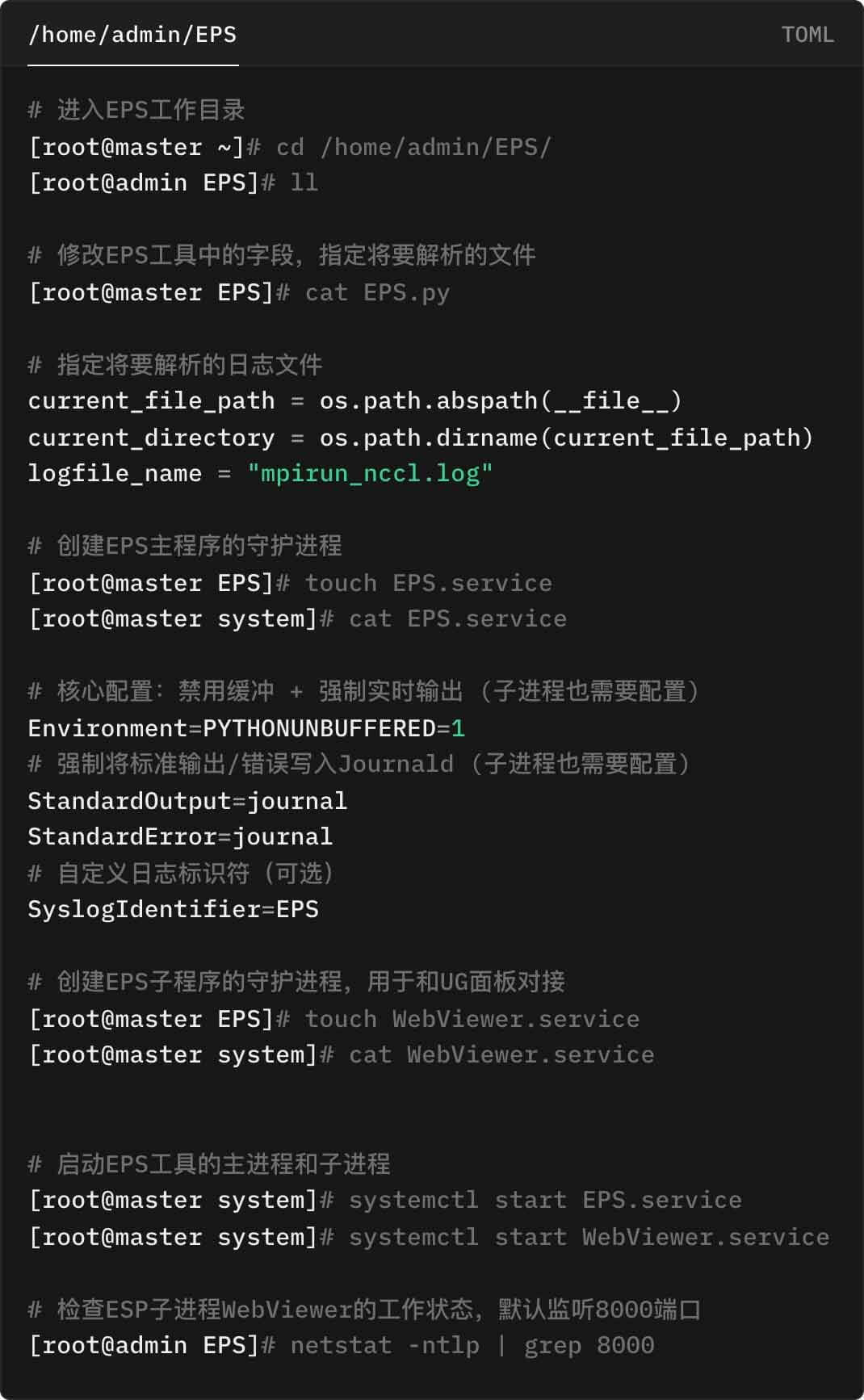
演示环境中的 Master 节点为一台独立的 CentOS 服务器,项目指定的工作目录为 /home/admin/EPS
配置控制面板
演示使用 EasyRoCE Toolkit 内的统一监控面板(UG,Unified Glancer),在此之前需要提前完成该平台的部署,请参阅:一文解读开源开放生态下的RDMA网络监控实践 中的“监控平台配置”部分。
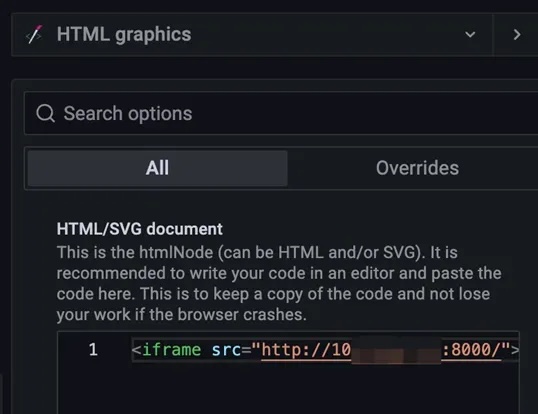
我们只需要为 UG 再添加一个呈现 HTML 的 Pannel,并完成 HTML 源的配置(如下图所示),EPS 解析出来的集合通信环信息就将作为各类 RDMA 网络相关监控指标信息的补充,辅助集群设施调优决策。
完成以上所有步骤,我们就可以在 UG 看到实时更新的集合通信库运行信息,手动更新NCCL 日志文件,可以看到 UG 中呈现的解析信息也同步刷新。
【更多详细内容,请访问星融元官网 开放网络的先行者和推动者- 星融元Asterfusion 官网】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









