






目录
Redis 是典型的 NoSQL 数据库。
redis官网:Download | Redis
Redis 是一个开源的 key-value 存储系统。
和 Memcached 类似,它支持存储的 value 类型相对更多,包括 string、list、set、zset、sorted set、hash。
这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,Redis 支持各种不同方式的排序。
与 memcached一样,为了保证效率,数据都是缓存在内存中。
区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
并且在此基础上实现了master-slave (主从)同步。
单线程 + IO 多路复用。
NoSQL数据库
-
解决 CPU 及内存压力

-
解决 IO 压力

NoSQL( NoSQL = Not Only SQL ),意即不仅仅是 SQL,泛指非关系型的数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的 key-value 模式存储。因此大大的增加了数据库的扩展能力。
- 不遵循 SQL 标准。
- 不支持 ACID。
- 远超于 SQL 的性能。
适用于的场景
- 对数据高并发的读写;
- 海量数据的读写;
- 对数据高可扩展性的。
不适用的场景
- 需要事务支持;
- 基于 sql 的结构化查询存储,处理复杂的关系,需要即席查询。
常见的 NoSQL 数据库
- Redis
- MongoDB
大数据时代常用的数据库类型
-
行式数据库
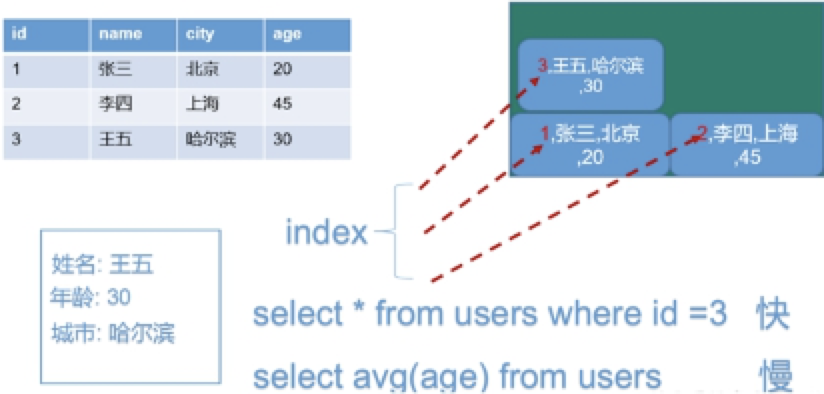
-
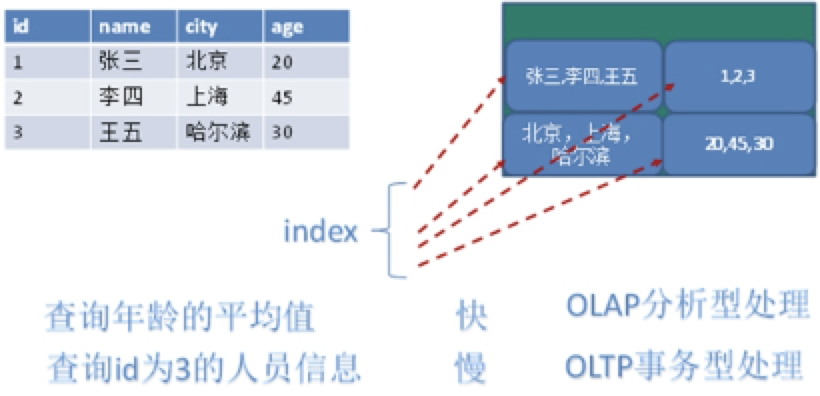
列式数据库
配置文件
redis.conf
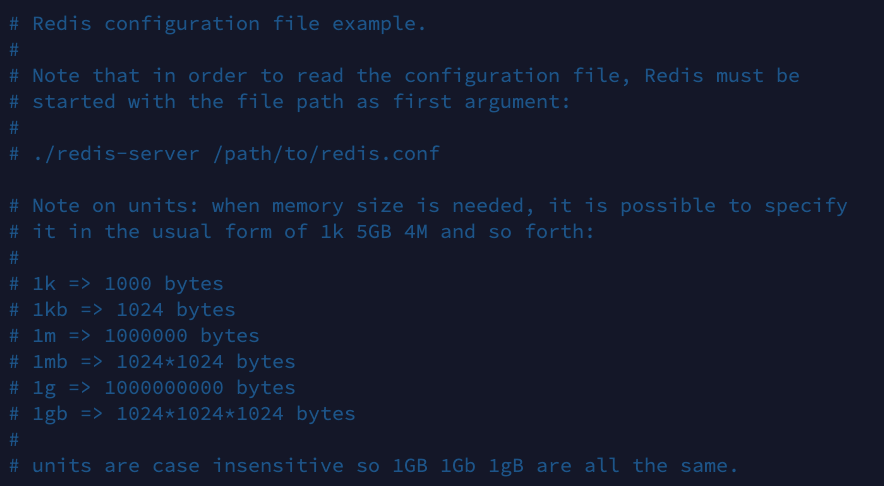
Units
单位,配置大小单位,开头定义了一些基本的度量单位,只支持 bytes,不支持 bit。
大小写不敏感。
INCLUDES
包含,多实例的情况可以把公用的配置文件提取出来。

NETWORK
网络相关配置。
bind
默认情况
bind=127.0.0.1只能接受本机的访问请求。不写的情况下,无限制接受任何 ip 地址的访问。
生产环境肯定要写你应用服务器的地址,服务器是需要远程访问的,所以需要将其注释掉。
如果开启了protected-mode,那么在没有设定 bind ip 且没有设密码的情况下,Redis 只允许接受本机的响应。
protected-mode
将本机访问保护模式设置 no。
port
端口号,默认 6379。
tcp-backlog
设置 tcp 的 backlog,backlog 其实是一个连接队列,backlog 队列总和 $=$ 未完成三次握手队列 $+$ 已经完成三次握手队列。
在高并发环境下你需要一个高 backlog 值来避免慢客户端连接问题。
timeout
一个空闲的客户端维持多少秒会关闭,0 表示关闭该功能。即永不关闭。
tcp-keepalive
对访问客户端的一种心跳检测,每个 n 秒检测一次。
单位为秒,如果设置为 0,则不会进行 Keepalive 检测,建议设置成 60。

GENERAL
通用。
daemonize
是否为后台进程,设置为 yes。
守护进程,后台启动。
pidfile
存放 pid 文件的位置,每个实例会产生一个不同的 pid 文件。
loglevel
指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 notice。
logfile
日志文件名称。
database
设定库的数量 默认16,默认数据库为 0,可以使用
SELECT <dbid>命令在连接上指定数据库 id。

SECURITY
安全。
访问密码的查看、设置和取消。
在命令中设置密码,只是临时的。重启 redis 服务器,密码就还原了。
永久设置,需要在配置文件中进行设置。
LIMITS
限制。
maxclients
设置 redis 同时可以与多少个客户端进行连接。
默认情况下为 10000 个客户端。
如果达到了此限制,redis 则会拒绝新的连接请求,并且向这些连接请求方发出 max number of clients reached 以作回应。
maxmemory
建议必须设置,否则,将内存占满,造成服务器宕机。
设置 redis 可以使用的内存量。一旦到达内存使用上限,redis 将会试图移除内部数据,移除规则可以通过 maxmemory-policy 来指定。
如果 redis 无法根据移除规则来移除内存中的数据,或者设置了不允许移除,那么 redis 则会针对那些需要申请内存的指令返回错误信息,比如 SET、LPUSH 等。
但是对于无内存申请的指令,仍然会正常响应,比如 GET 等。如果你的 redis 是主 redis( 说明你的 redis 有从 redis ),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
maxmemory-policy
volatile-lru:使用 LRU 算法移除 key,只对设置了过期时间的键(最近最少使用)。
allkeys-lru:在所有集合 key 中,使用 LRU 算法移除 key。
volatile-random:在过期集合中移除随机的 key,只对设置了过期时间的键。
allkeys-random:在所有集合 key 中,移除随机的 key。
volatile-ttl:移除那些 TTL 值最小的 key,即那些最近要过期的 key。
noeviction:不进行移除。针对写操作,只是返回错误信息。
maxmemory-samples
设置样本数量,LRU 算法和最小 TTL 算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis 默认会检查这么多个 key 并选择其中 LRU 的那个。
一般设置 3 到 7 的数字,数值越小样本越不准确,但性能消耗越小。

常用五大基本数据类型
key操作
keys *:查看当前库所有 key
exists key:判断某个 key 是否存在
type key:查看你的 key 是什么类型
del key :删除指定的 key 数据
unlink key:根据 value 选择非阻塞删除,仅将 keys 从 keyspace 元数据中删除,真正的删除会在后续异步操作
expire key 10 :为给定的 key 设置过期时间
ttl key:查看还有多少秒过期,-1表示永不过期,-2表示已过期
select:命令切换数据库
dbsize:查看当前数据库的 key 的数量
flushdb:清空当前库
flushall:通杀全部库字符串(String)
String 类型是二进制安全的。意味着 Redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。
String 类型是 Redis 最基本的数据类型,一个 Redis 中字符串 value 最多可以是 512M。
set <key><value>:添加键值对
get <key>:查询对应键值
append <key><value>:将给定的 <value> 追加到原值的末尾
strlen <key>:获得值的长度
setnx <key><value>:只有在 key 不存在时,设置 key 的值
incr <key>:将 key 中储存的数字值增 1,只能对数字值操作,如果为空,新增值为 1(**具有原子性**)
decr <key>:将 key 中储存的数字值减 1,只能对数字值操作,如果为空,新增值为 -1
incrby/decrby <key><步长>:将 key 中储存的数字值增减。自定义步长
mset <key1><value1><key2><value2> :同时设置一个或多个 key-value 对
mget <key1><key2><key3>...:同时获取一个或多个 value
msetnx <key1><value1><key2><value2>... :同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在
getrange <key><起始位置><结束位置>:获得值的范围
setrange <key><起始位置><value>:用 <value> 覆写 <key> 所储存的字符串值
setex <key><过期时间><value>:设置键值的同时,设置过期时间,单位秒。
getset <key><value>:以新换旧,设置了新值同时获得旧值。原子性
所谓 原子 操作是指不会被线程调度机制打断的操作;
这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
-
在单线程中, 能够在单条指令中完成的操作都可以认为是”原子操作”,因为中断只能发生于指令之间。
-
在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis 单命令的原子性主要得益于 Redis 的单线程。
数据结构
内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

列表(List)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

lpush/rpush <key><value1><value2><value3> ....: 从左边/右边插入一个或多个值。例如:
lpush k1 v1 v2 v3
lrange k1 0 -1
输出:v3 v2 v1
----
rpush k1 v1 v2 v3
rrange k1 0 -1
输出:v1 v2 v3
lpop/rpop <key>:从左边/右边吐出一个值。值在键在,值光键亡。
rpoplpush <key1><key2>:从 <key1> 列表右边吐出一个值,插到 <key2> 列表左边。
lrange <key><start><stop>:按照索引下标获得元素(从左到右)
lrange mylist 0 -1 0:左边第一个,-1右边第一个,(0 -1表示获取所有)
lindex <key><index>:按照索引下标获得元素(从左到右)
llen <key>:获得列表长度
linsert <key> before/after <value><newvalue>:在 <value> 的前面/后面插入 <newvalue> 插入值
lrem <key><n><value>:从左边删除 n 个 value(从左到右)
ltrim <key><start><end>:按照索引截取下标元素(从左到右)
lset<key><index><value>:将列表 key 下标为 index 的值替换成 value数据结构
List 的数据结构为快速链表 quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成 quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next。
Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。

Set(集合)
Set 对外提供的功能与 List 类似列表的功能,特殊之处在于 Set 是可以 自动排重 的,当需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个成员是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
Redis 的 Set 是 String 类型的无序集合。它底层其实是一个 value 为 null 的 hash 表,所以添加,删除,查找的复杂度都是 ***O(1)***。
一个算法,随着数据的增加,执行时间的长短,如果是 ***O(1)***,数据增加,查找数据的时间不变。
sadd <key><value1><value2> ..... :将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers <key>:取出该集合的所有值。
sismember <key><value>:判断集合 <key> 是否为含有该 <value> 值,有返回 1,没有返回 0
scard<key>:返回该集合的元素个数。
srem <key><value1><value2> ....:删除集合中的某个元素
spop <key>:随机从该集合中吐出一个值
srandmember <key><n>:随机从该集合中取出 n 个值,不会从集合中删除
smove <source><destination>value:把集合中一个值从一个集合移动到另一个集合
sinter <key1><key2>:返回两个集合的交集元素
sunion <key1><key2>:返回两个集合的并集元素
sdiff <key1><key2>:返回两个集合的差集元素(key1 中的,不包含 key2 中的)数据结构
Set 数据结构是字典,字典是用哈希表实现的。
Hash(哈希)
Redis hash 是一个键值对集合。
Redis hash 是一个 String 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
hset <key><field><value>:给 <key> 集合中的 <field> 键赋值 <value>
hget <key1><field>:从 <key1> 集合 <field> 取出 value
hmset <key1><field1><value1><field2><value2>...: 批量设置 hash 的值
hexists <key1><field>:查看哈希表 key 中,给定域 field 是否存在
hkeys <key>:列出该 hash 集合的所有 field
hvals <key>:列出该 hash 集合的所有 value
hincrby <key><field><increment>:为哈希表 key 中的域 field 的值加上增量 1 -1
hsetnx <key><field><value>:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在数据结构
Hash 类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。
当 field-value 长度较短且个数较少时,使用 ziplist,否则使用 hashtable。
Zset(有序集合)
Redis 有序集合 zset 与普通集合 set 非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复的。
因为元素是有序的,所以可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此能够使用有序集合作为一个没有重复成员的智能列表。
zadd <key><score1><value1><score2><value2>…:将一个或多个 member 元素及其 score 值加入到有序集 key 当中
zrange <key><start><stop> [WITHSCORES] :返回有序集 key 中,下标在 <start><stop> 之间的元素
当带 WITHSCORES,可以让分数一起和值返回到结果集
zrangebyscore key min max [withscores] [limit offset count]:返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key max min [withscores] [limit offset count] :同上,改为从大到小排列
zincrby <key><increment><value>:为元素的 score 加上增量
zrem <key><value>:删除该集合下,指定值的元素
zcount <key><min><max>:统计该集合,分数区间内的元素个数
zrank <key><value>:返回该值在集合中的排名,从 0 开始。数据结构
SortedSet(zset)是 Redis 提供的一个非常特别的数据结构,一方面它等价于 Java 的数据结构 ***Map<String, Double>***,可以给每一个元素 value 赋予一个权重 score,另一方面它又类似于 TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名次,还可以通过 score 的范围来获取元素的列表。
zset 底层使用了两个数据结构
-
hash,hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值
-
跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表
Redis的发布与订阅
Redis 发布订阅( pub/sub )是一种消息通信模式:发送者( pub )发送消息,订阅者( sub )接收消息。
Redis 客户端可以订阅任意数量的频道。
- 客户端可以订阅频道
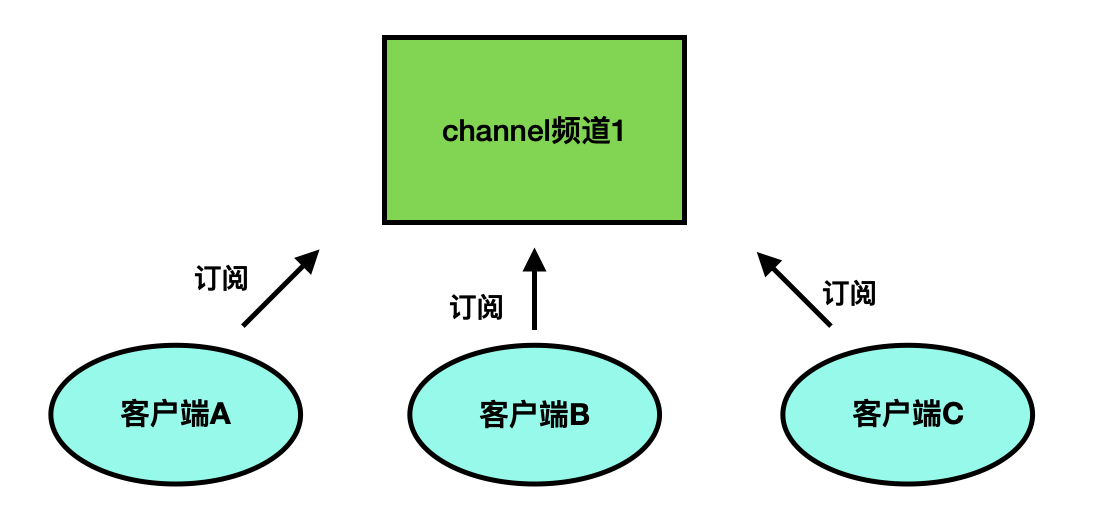
- 当给这个频道发布消息后,消息就会发送给订阅的客户端

subscribe channel # 订阅频道
publish channel hello # 频道发送信息














 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









