







MongoDB聚合查询概述
MongoDB 高效的文档数据库,可以用于存储类似于
在使用find查询数据时我们可以拼接过滤条件,以返回符合条件的数据,但通常这些数据都不能直接拿来使用或传递,
需要后台再次加工后返回给前端应用。比如我们查询一个用户所有的博文就是类似的操作,通常个人信息和博文信息是分为两张表进行存储的,如果你想知道指定用户的博文时就需要进行表关联查询,如果你了解关系型数据库,那么就能更好的理解这种操作,因为这种表关联查询操作在日常开发中太常见了~
在Mongo中Aggregate命令是用于聚合查询的方法,在不增加任何参数的情况下等同于find方法,他的格式如下
collection.aggregate([阶段1,阶段2,……,阶段N])
阶段指令有 用于筛选数据的 m a t c h 、 用 于 字 段 相 关 的 match、用于字段相关的 match、用于字段相关的project、用于分组的 g r o u p 、 用 于 拆 分 数 据 的 group、用于拆分数据的 group、用于拆分数据的unwind、用于关联表的$lookup
筛选数据
db.getCollection('example_user').aggregate([
{"$match":{
"name":"姜大牛",
"id":{"$lt":2}
}}
])
$match的参数与find的第一个参数是一样,可以使用字段匹配或者使用范围匹配
调整字段
db.getCollection('example_user').aggregate([
{"$project":{
"_id":0, //隐藏_id
"id":"$id", //引用自定义id
"名字":"$address", //修改字段名称
"work":"作家", //追加字段
"isLogin":{"$literal":1}, //默认值为1或0
"hello":{"$literal":"$美元"} //默认值带有$
}}
])
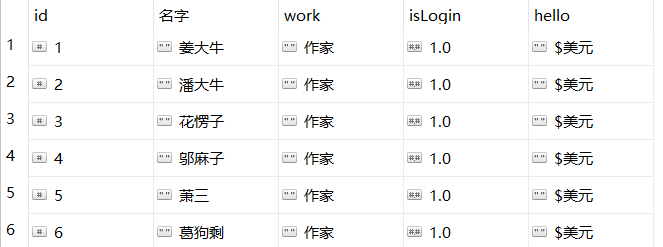
project的参数与find的第二个参数类似,只不过具有更多的操作可选,可以追加或修改原有字段,也可以追加子文档的字段。当结果中需要使用‘
’
或
者
1
、
0
作
为
默
认
值
时
,
可
以
使
用
’或者1、0作为默认值时,可以使用
’或者1、0作为默认值时,可以使用literal进行标注,防止与mongo的语法冲突。
数据分组
分组函数
db.getCollection('example_data').aggregate([
{"$group":{
"_id":"$name"
}}
])

去重函数
db.getCollection('example_data').distinct("name")

首先我们对去重函数和分组函数进行比较可以发现返回值有明显的区别,分组返回数据每行一条,而去重返回的数据在一个数组中。如果我们需要返回更多的字段,如分数信息,平均值等需要统计的数据时,使用分组信息会更适合。我们在对分组信息进行充实一下。
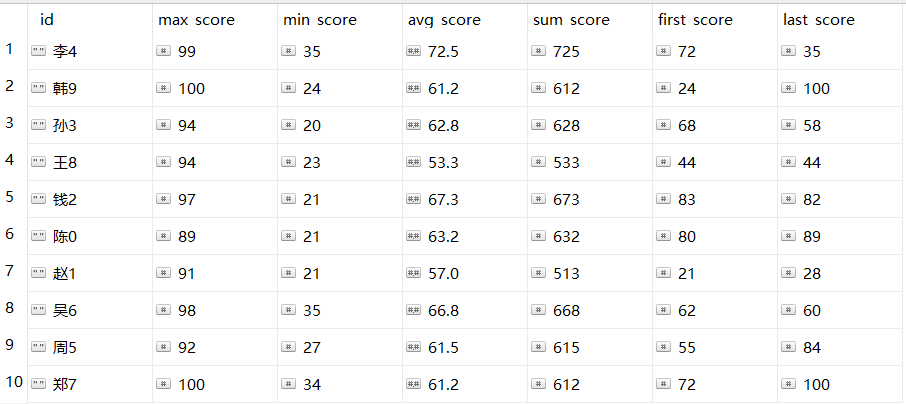
db.getCollection('example_data').aggregate([{
"$group":{
"_id":"$name",
"max_score":{"$max":"$score"}, //获取最大值
"min_score":{"$min":"$score"}, //获取最小值
"avg_score":{"$avg":"$score"}, //获取平均值
"sum_score":{"$sum":"$score"}, //获取总和
"first_score":{"$first":"$score"}, //获取第一个值
"last_score":{"$last":"$score"}, //获取最后一个值
}
}])
拆分数据
当数据中包含数组时,我们需要将数据拆分后在处理
db.getCollection('example_tshirt').aggregate([
{"$unwind":"$size"}
])
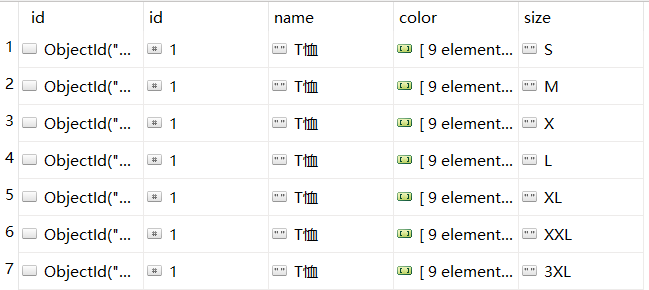
我们也可以拆分多个字段
db.getCollection('example_tshirt').aggregate([
{"$unwind":"$size"},
{"$unwind":"$color"}
])
联集合查询
联集合查询相当于SQL中的联表查询,通过对多个集合的数据进行整合得到我们需要的数据,格式如下
主集合.aggregate([
{"$lookup":{
"from":"关联集合",
"localField":"主集合字段",
"foreignField":"关联集合字段",
"as":"关联集别名"
}}
])
比如我们需要查询用户都写了哪些博文就可以按照如下的格式写
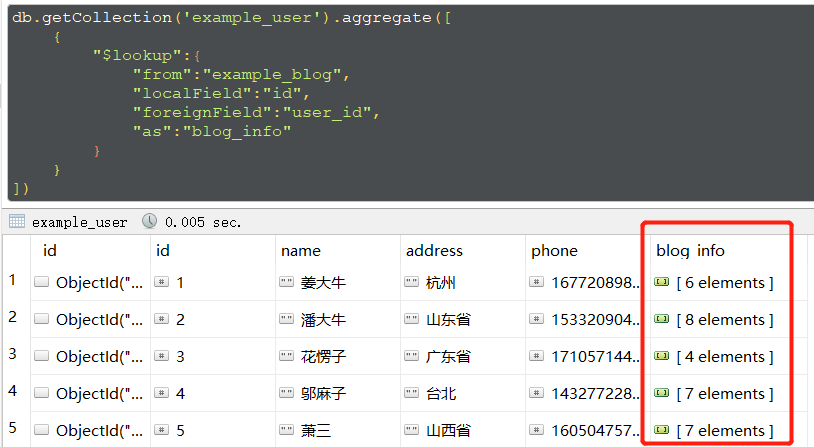
当然这种数据格式对于我们来说还不够,我们可以对数据进行优化
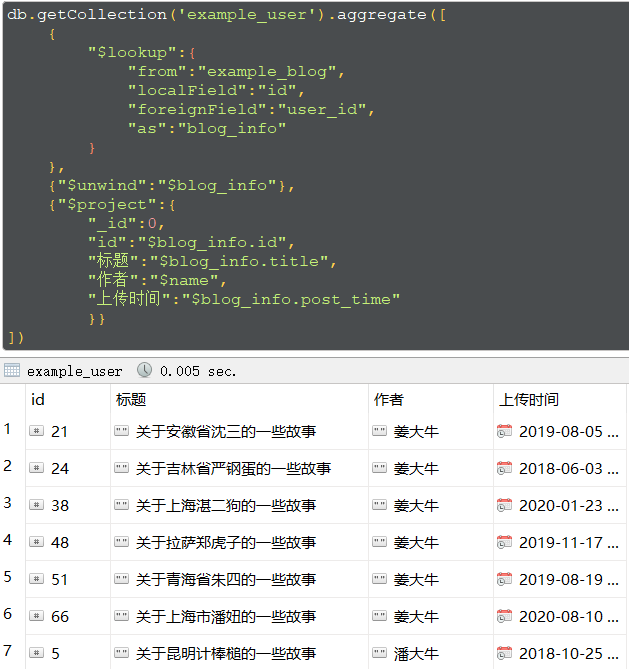
另外
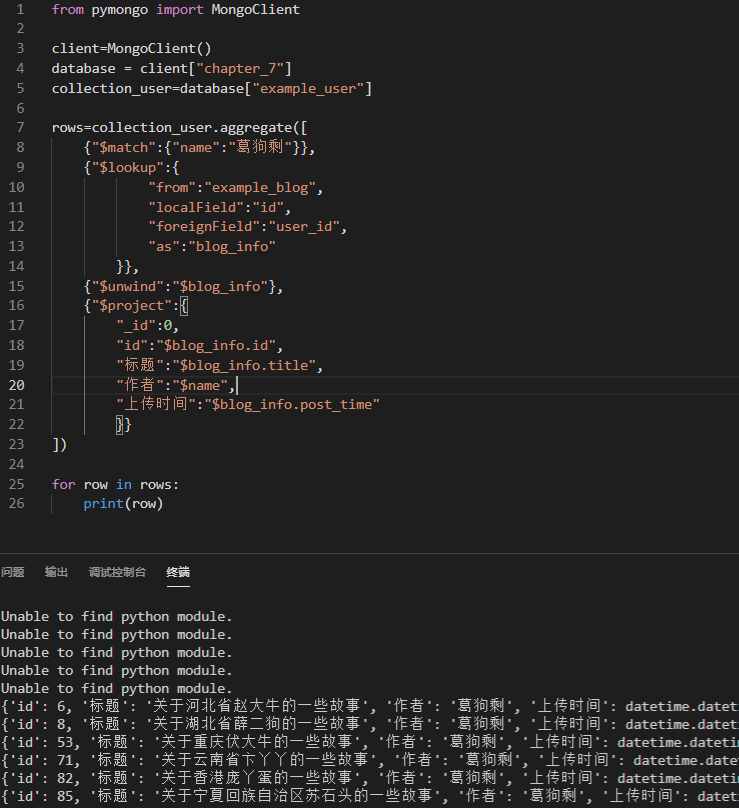
搞完mongo肯定是需要拿来用的,在python中有个pymongo库,几乎可以将mongo指令直接拿来用,这样减少了我们的学习成本,相当给力
















 4294
4294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











