






最近被公司优化,闲暇之际研究了下java的爬虫,恰好有个朋友需要帮忙,于是使用java语言采用maven配置管理,使用htmlunit,tess4j,opencv,相结合抓取了一个网站的数据。这个网站的数据是公开的,不过查询需要输入验证码,所以写了一个爬虫软件,下面简单讲述一下这个项目。
1.项目系统环境:
电脑系统:windows
java版本:open jdk 17
开发的ide:eclipse
项目模版:maven Project
2.maven的配置
在这里插入代码片
<dependency>
<groupId>org.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.11.0</version>
</dependency>
<dependency>
<groupId>org.openpnp</groupId>
<artifactId>opencv</artifactId>
<version>4.9.0-0</version>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20240303</version>
</dependency>
3.项目的思路
3.1使用htmlunit解析网站的页面,和执行js,实例代码
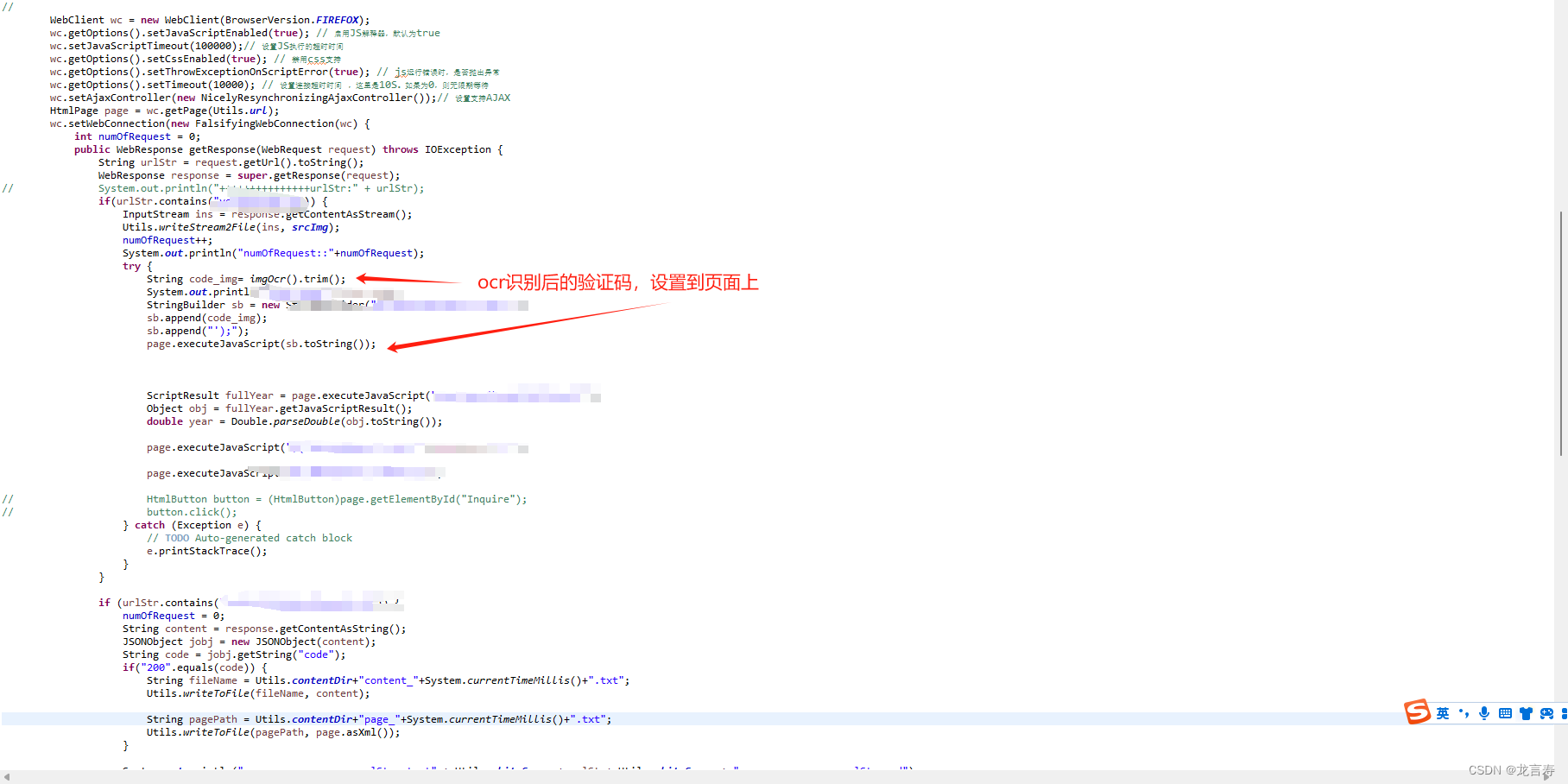
3.2使用tess4j进行验证码识别

3.3为了提高对验证码的识别率, 用opencv对验证码图片进行灰度化处理

开发的过程主要工作是对html页面的分析,关于htmlunit,tess4j,opencv的使用方法请自行百度,有不懂的可以私信,不过希望大家不要使用爬虫技术进行违反法律的活动。















 2010
2010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









