









 本文介绍了Lucene如何利用倒排索引实现全文检索的加速。倒排索引通过将文档内容拆分成词条并建立词条与文档编号的关系,解决了大数据量下检索效率问题。分词在索引和检索过程中的正确应用对于提高检索效果至关重要。讨论了分词不匹配情况下可能影响倒排索引的效果,并指出索引与检索阶段的分词一致性对于充分发挥倒排索引优势的作用。
本文介绍了Lucene如何利用倒排索引实现全文检索的加速。倒排索引通过将文档内容拆分成词条并建立词条与文档编号的关系,解决了大数据量下检索效率问题。分词在索引和检索过程中的正确应用对于提高检索效果至关重要。讨论了分词不匹配情况下可能影响倒排索引的效果,并指出索引与检索阶段的分词一致性对于充分发挥倒排索引优势的作用。
Lucene 是基于倒排索引来实现快速的全文检索的,那么倒排索引是什么概念呢?
![]()
![]()
![]()
![]()
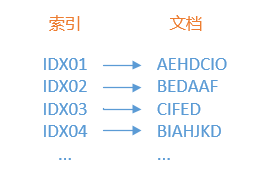
首先来看看普通索引是怎样建立的,请参考下图。
图中,我们为右侧的每一个文档都建立了一个索引编号,当我们知道这个编号时,就可以查询到对应的文档,而如果我们还对这些索引编号进行排序,那检索的速度就会更快。但是,当我们需要检索包含“F”的文档时,普通索引就完全不能发挥作用了,因为我们不得不遍历每一个文档,并试图筛选出那些包含了“F”的文档,而这样的检索性能在大数据量的情况就可想而之了。
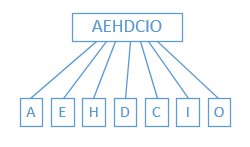
再来看看倒排索引是怎样解决全文检索性能问题的,答案当然还是建立索引,只是这次的索引不是编号,而是词条。试想一下全文检索的场景,我们要实现的无非是输入一个词条(如上例中的“F”),然后检索出包含这个词条的文档。那么,如果我们预先知道要检索的是哪些词条,就可以从文档中提取出这些词条并建立词条与文档之间的关系。为了避免直接引用文档内容,词条引用的将是前述文档的索引编号。建立倒排索引可分为两个步骤,首先从文档中拆分出词条,这个过程就是分词。
图中,我们将文档内容“AEHDCIO”按照字母分拆为多个词条,这些词条都与被拆分的文档关联。注意,对文档内容进行怎样的拆分完全由需求决定,不良好的分词方法,可能会导致非常糟糕的检索体验,甚至完全检索不到内容。在 Lucene 中执行从文档中拆分出词条任务的是
Tokenizer 类型。接下来,就是要建立词条与文档之间的联系。
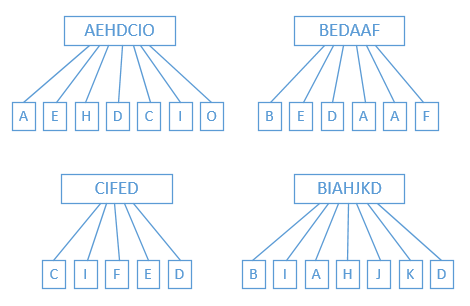
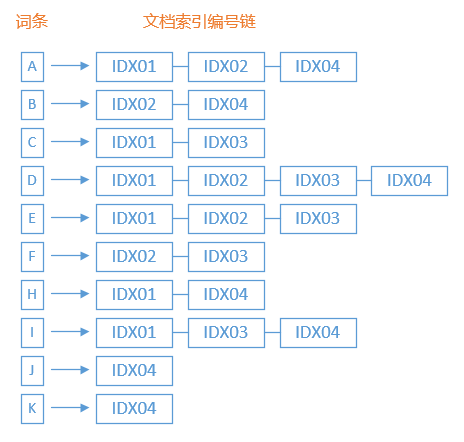
图中,我们将四个示例中的文档全部都按照字母分拆为多个词条,然后以每个词条为基础,建立这个词条与所有包含这个词条的文档之间的关联。如此就形成了如下的倒排索引结构,这个结构中,词条被单独索引并且排序,而词条关联的文档的编号也被组织成一个被排序的链表,可以很方便的对文档编号进行遍历。
从倒排索引的结构上就可以发现,现在我们能够以更好的性能来实现前述的全文检索需求了。比如,当我们需要检索包含“F”的文档时,只需在词条索引中先找到“F”词条,然后再取出“F”词条对应的文档编号就行,更进一步的分页、获取文档内容等操作就与普通数据库无异了。通过倒排索引,我们还可以实现更多复杂逻辑的检索方式,比如要检索同时包含“D”和“F”且不包含“A”的文档,只需要先把“D”和“F”词条关联的文档编号取出来求并集,得到“IDX02”和“IDX03”两个文档,然后再排除“A”词条关联的文档编号,最后得到“IDX03”这个文档。
既然倒排索引这么强大,是不是就可以解决所有全文检索的问题了呢?这当然不是,就以前述示例中建立的倒排索引为例,当用户以“CI”为检索请求内容时,如果检索系统把“CI”看作是一个词条(即在检索过程中未对检索内容分词),则不会检索出任何文档,因为在倒排索引中根本就找不到“IO”这个词条;而如果检索系统把“CI”按照文档索引时的方法来分词后再进行检索,并默认检索请求中词条之间为逻辑与关系,则会检索出“IDX01”和“IDX03”两个文档。这说明,倒排索引为我们进行快速全文检索奠定了数据结构的基础,而分词则在文档的索引和检索过程中都要发挥应有的作用,如果索引过程与检索过程的分词不配合,则不可能发挥出倒排索引的优势来。通常来说,索引过程与检索过程的分词方案是一致,但在某些特殊需求下,也会有不一致的情况发生。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









