







 本文详细探讨了Hive数据库的优化策略,涉及建表优化、存储压缩、Job层面的参数调整、以及HQL层面的列裁剪、CBO优化等,帮助完善知识体系并提升查询效率。
本文详细探讨了Hive数据库的优化策略,涉及建表优化、存储压缩、Job层面的参数调整、以及HQL层面的列裁剪、CBO优化等,帮助完善知识体系并提升查询效率。
工作中涉及到优化部分不多,下面的一些方案可能会缺少实际项目支撑,这里主要是为了完备一下知识体系。
参考的hive参数管理文档地址:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
对于Hive优化,可以从下面几个角度出发:
一、建表优化
根据业务选择合适的分区表或分桶表,分区在HDFS上的表现就是分文件夹,分桶就是分文件,这样在进行数据查询分析时可以避免全表扫描,直接读取目标分区或分桶。
二、存储压缩优化
1.存储
存储主要分为列式存储与行式存储,hive支持的主要存储方式有:
TextFile:行式,也是hive默认的存储格式,数据以纯文本格式存储,可直接文本编辑器打开查看。
Sequence File:行式,序列化为二进制存储,可以被MR高效读写,但因为行式所以不适合SQL分析,因此当某些需要MR处理但不需要进行SQL分析的可以选择。
ORC File:列式,RCFile的升级版,对hadoop生态的原生支持比较好,Hive 0.11版本及之后引入。支持ACID事务和行级别的更新。
Parquet File:列式,兼容性比较好,包括hadoop生态和很多非hadoop生态系统。
hive中,往往是基于大数据量对某些指标进行分析计算,只需要处理某几个特定的字段就行了,因此一般选择列式存储,可以提升读的效率。
2.压缩
压缩可以从3个角度来说,分别是map输出结果的压缩,reduce最终输出结果的压缩,和同一个job中不同MR之间中间结果数据的压缩。压缩会一定程度的增加CPU开销,但是降低了磁盘IO和网络传输IO。
开发中常用的方案:ORC/Parquet + Snappy
三、Job层面优化
1.合理控制map&reduce个数
MR中,一个map或者一个reduce就是一个进程,进程的创建启动开销大,如对于小文件问题,会造成为每个小文件都启动一个map任务,浪费资源。可以通过参数设置在map任务执行前对小文件进行合并。或者是,input的文件很大,处理逻辑又复杂,就会导致单个map的负载过重,造成整体任务缓慢,这种情况可以通过减小每个map可以读取的数据量最大值来增加map数量,提高并行计算的能力。
对于reduce的个数,可以通过调整每个reduce处理的数据量进而调整reduce的个数,或者是通过参数直接指定具体个数。但要注意reduce个数太少可能会导致单个任务处理缓慢,过多可能会导致reduce任务启动开销的浪费和输出小文件过多的问题。一般来说,让hive自己选择就好。
2.JVM重用
原因同上,默认情况下,每个map或reduce任务都会启动一个JVM进程,通过参数设置JVM重用就是为了减少进程的频繁创建启动,当通过参数指定每个JVM进程处理的任务数后,JVM实例只有在处理完指定的任务数量之后才会销毁。需要注意的是,设置JVM重用并不会影响启动的JVM个数,区别只是在于执行完任务后是直接执行下一个任务,还是销毁进程,重新启动一个JVM
去执行下个任务。可以通过在hadoop的mapred-site.xml配置文件中设置 mapreduce.job.jvm.numtasks参数(在一些低版本的hadoop中参数可能为mapred.job.reuse.jvm.num.tasks)为JVM设置可重复运行的任务个数。

参考:https://hadoop.apache.org/docs/r2.5.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
3.Fetch抓取
hive读取HDFS数据有两种方式:
1)通过MR读取。
2)直接读取。
开启fetch机制后,特定条件下的查询不会转换成MR任务,而是直接从HDFS中读取数据,从而提升效率。
通过参数hive.fetch.task.conversion设置,值允许为none, minimal , more。
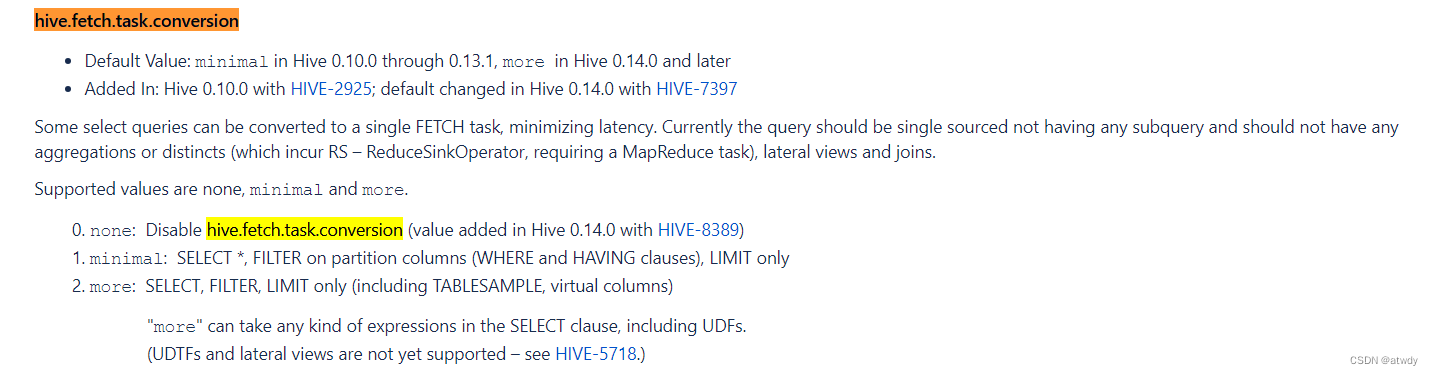
在Hive 0.14.0及之后默认值为more,当涉及到简单的select全局查找或字段查找,where过滤或者limit查找时不走MR。这就要求当前的查询不能出现分组、聚合、关联等类似操作,很好理解,因为涉及到后面的操作时必须启动MR计算,而不是简单的将数据原样读取返回即可。
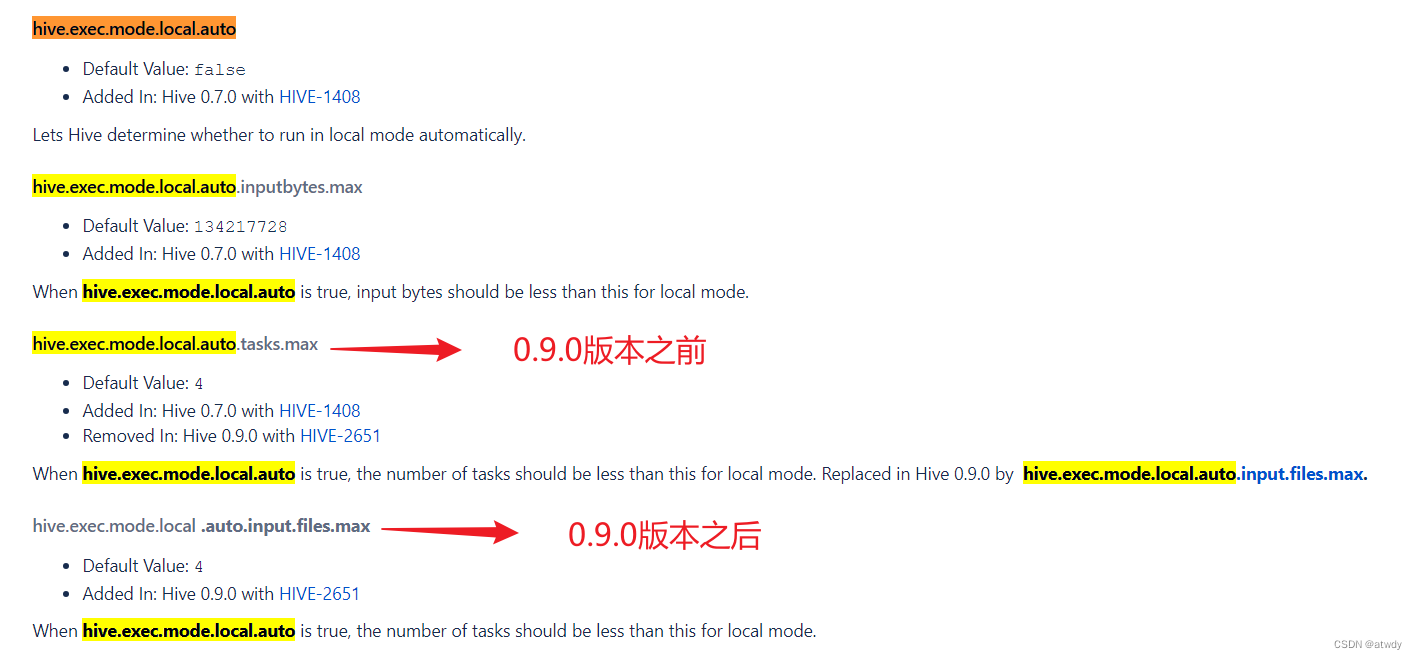
4.本地模式
这点主要是针对小数据量的任务而言的。也就是对于小数据量的任务,不提交到集群执行,而是在集群的某个单一节点上执行。好处是避免了集群间不必要的资源协调调度和跨节点数据传输。可通过下面参数开启配置:
5.并行执行
一个HiveSQL可能会转化为多个stage阶段,如果这些阶段之间没有依赖关系是可以并行执行的,最大化利用集群资源。类似于(A) union all (B),此时AB是可以并行执行的。可以通过下面参数设置:

并行执行受限于集群资源,只有当集群资源充足才会并行执行。同时对于小数据量的sql可能反而导致效率变慢,原因是增加了资源和任务的调度开销,超过了小查询本身执行的时间。
6.推测执行
这主要是针对个别执行过慢的任务的一种优化策略。如果某个任务执行时间明显超过其他同类型任务时,可能是因为执行该任务的节点硬件故障,网络拥堵,或者其他原因。此时hive会重启一个备份任务执行,和原任务谁先执行完就以谁的结果为准。设置参数:

参考:https://hadoop.apache.org/docs/r2.5.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
7.严格模式
严格模式就是不让执行hive认为有“风险”的查询,比如分区表必须使用分区过滤,order by时必须跟着limit子句,限制产生笛卡尔积的查询等。参数设置:

四、HQL层面优化
1.列裁剪&分区裁剪
就是查询时只select需要的字段,对于分区表指定分区查找。
2.谓词下推
就是将where数据过滤尽早的提前到map端过滤,而不是在reduce端对处理后的结果进行过滤。类似于下面这两段SQL:
-- 没有使用谓词下推的sql执行逻辑
select
*
from A join B on A.id = B.id
where A.id<10;
-- 使用谓词下推后的sql执行逻辑
select
*
from (select * from A where id<10) A join B on A.id=B.id;
hive中默认开启此配置:

3.CBO优化
CBO:Cost based Optimizer,基于代价/成本的优化。比如多个表join的时候,如果不考虑CBO优化,往往前面的表作为驱动表被加载进内存,后面的表作为被驱动表进行磁盘扫描。开启CBO优化后,hive会根据统计信息决定最优的表连接顺序,连接算法等。可以通过下面4个参数开启设置:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
在hive1.1.0之后默认开启:

关于hive中CBO优化细节可以查看https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
4.group by优化
group by是对相同key的数据拉取到同一个reduce中处理,如果这个key的数据量很大,就可能导致数据倾斜。可以通过开启map端预聚合,和当出现数据倾斜时开启负载均衡来优化。
负载均衡指的是将原先的一个MR job转换成两个MR job,第一阶段随机打散预聚合,第二阶段对预聚合的结果进行最终聚合。
可通过下面参数开启:
-- 开启map端预聚合
set hive.map.aggr = true;
-- map端预聚合的数据条数
set hive.groupby.mapaggr.checkinterval = 100000;
-- 开启负载均衡
set hive.groupby.skewindata = true;

5.join优化
join优化可分为map join(小表join大表)和SMB join(大表join大表)。
map join
map join是将小表直接分发到各个map任务的进程中,在map进程中完成join,省略了shuffle的过程,也就避免了数据倾斜的可能。
参数设置:
-- 开启map join
set hive.auto.convert.join=true;
-- 小表阈值,单位字节,大约25MB
set hive.mapjoin.smalltable.filesize=25000000;
SMB join
SMB(Sort Merge Bucket Join),这种方式要求两个表都根据关联字段分桶并排序。原理是将两个大表分桶,且两表桶数成倍数关系,那么关联的时候,驱动表的每个桶都只会被驱动表中与自己相关的桶进行连接,避免了全局shuffle,在map阶段就可以完成,所以也不会导致数据倾斜单个任务执行缓慢。同时因为桶内有序,所以连接时可以采用类似归并排序的方式进行连接,提高连接效率。
6.order by+limit
如果排序时不加limit限制,那么就会将所有数据拉取到同一个reduce中进行排序,非常容易导致任务执行缓慢。而+limit限制之后,比如说limit 5,那么会首先在每个reduce中对局部数据进行排序,并从每个reduce中找出局部前5的数据,再将所有reduce的结果进行最终排序,选出全局前5的数据。
7.避免产生笛卡尔积
这里主要就是说,join连接时要指定连接字段,一般开发中也不会犯这种错误。















 2173
2173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









