







HDFS读流程
-
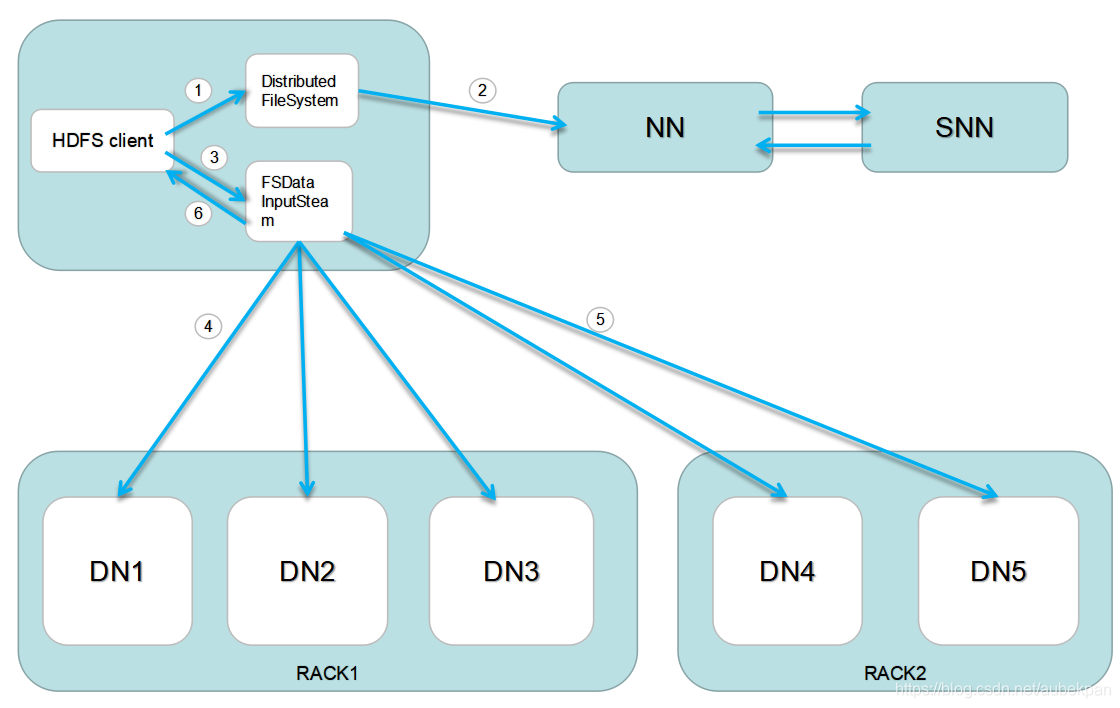
客户端通过分布式FileSystem.open(path)方法,与NameNode之间进行RPC通信,其中open方法会将一个path传递过去,这个path就是我们要查看的文件或文件夹的路径.NameNode会对这个path进行校验,判断是否存在这个路径,以及是否拥有相应的权限去读取。
-
校验完后返回一个FSDataInputStream对象,当要读取client需再次向NameNode发送一次请求,然后NameNode回返回要读取文件的全部或者一部分block列表(有可能一次获取完成不了)
-
客户端调用FSDataInputStream对象的read方法去读取每一个block最近地址的副本(虽然有多个副本,但是并不是要读取全部副本,会根据一个算法来读取离客户端最近节点上的副本),读取完后校验这个block是否损坏,如果没有问题自动关闭当前与DataNode的通信。如果校验失败,会记录下这个受损的block在哪个DataNode节点上,下次不会再读取。
-
依次类推,继续读取下个block,当把block列表里的block都读取完成后,文件还没有结束将继续向NameNode申请下一批block列表
-
最后客户端调用FSDataInputStream的close方法来关闭输入流。
关于HDFS通信:
所有的HDFS通信都基于TCP/IP协议。客户端建立与NameNode通信的端口,它将客户端协议与NameNode进行通信。DataNode使用DataNode协议与NameNode通信。按照架构设计,NameNode永远不会开启任何的RPC,相反,它只响应DataNode或者客户端发送的PRC通信请求。
P.S 原文摘自 The Communication Protocols
https://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html














 8246
8246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









