







一直没有深入去学习,近段时间在看《大型网站技术架构核心原理与案例分析》,作者写的也很通俗易懂,特地记录了一些关键的学习点,分享给大家。
作用
在分布式集群环境中,如果需要动态扩容,增加节点时,保证不停止所有服务器运行、并且不影响大部分缓存数据查询无效,提高缓存命中率。
原理
一致性Hash算法通过一个叫作一致性Hash环的数据结构实现key到分布式缓存服务器的Hash映射。
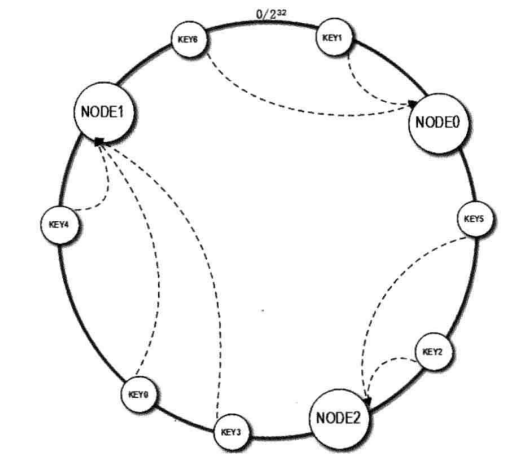
具体的算法过程:先构造一个长度为 232 的整形环(这个环被称为一致性hash环),根据节点名称的hash值(分布范围为【0, 232 -1】),将缓存服务器节点放置在这个hash环上。然后根据需要缓存的数据key值计算得到hash值(分布范围同样为【0, 232 -1】),然后在hash环上顺时针查找距离这个key的hash值最近的缓存服务器节点,完成key到缓存服务器的hash映射查找。
例如上图中,假设NODE1的hash值为3,594,963,423,NODE2的hash值为1,845,328,979,而KEY0的hash值为2,534,256,785,那么KEY0在环上顺时针查找,找到最近的节点就是NODE1。
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(NODE3)的hash值放入一致性Hash环中,由于KEY是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一小段,如下图加粗的一段。
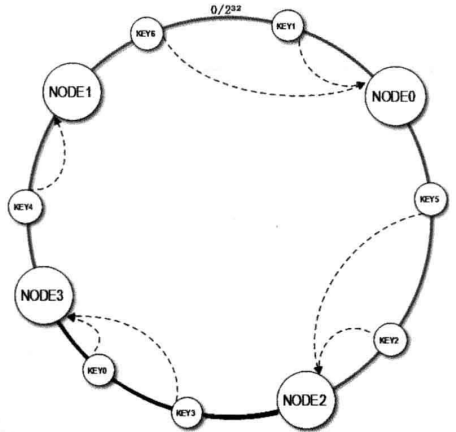
假设NODE3的hash值是2,790,324,235,那么加入NODE3后,KEY0顺时针查找得到的是节点NODE3,而不是原来的NODE1了。
加入新的节点NODE3后,原来的KEY大部分还能继续计算到原来的节点,只有KEY3、KEY0从原来的NODE1重新计算到NODE3。这样就能保证大部分被缓存的数据还可以继续命中。3台服务器扩容到3台服务器,可以继续命中原有的缓存数据的概率是75%,随着集群的规模越大,继续命中原有缓存数据的概念也就逐渐增大,100台服务器扩容增加一台服务器,继续命中率为99%。虽然仍有小部分数据缓存在服务器不能被读到,但是这个比例足够小,通过访问数据主加或者其它方式获取也不会对数据库造成致命的负载压力。
具体应用中,这个长度为 232 的一致性hash环通常使用二叉查找树实现,hash查找过程实际是在二叉查找树 查找不小于查找数据的最小值。当然这个二叉数的最右边叶子节点和最左边的叶子节点相连接,构成环。
参考文献:
[1]: http://pan.baidu.com/s/1o6Mak1k [大型网站技术架构(核心原理与案例分析)]















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









