







利用MySQL数据库如何解决大数据量存储问题?
暂时可以先考虑用infobright 这是mysql的数据仓库解决方案
如果这都满足不了需求 再考虑hadoop
好吧,你的检索SQL是怎么样的?
每张表每天几千万,对于写入性能的要求也就很高了。10000000/3600/24,每秒要写入115条记录。
而且你的数据属于归档类数据, 可以用mongodb来存储,写入速度和查询速度比MYSQL都要好很多 。
提问:如何设计或优化千万级别的大表?此外无其他信息,个人觉得这个话题有点范,就只好简单说下该如何做,对于一个存储设计,必须考虑业务特点,收集的信息如下:
1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节;
2.数据项:是否有大字段,那些字段的值是否经常被更新;
3.数据查询SQL条件:哪些数据项的列名称经常出现在WHERE、GROUP BY、ORDER BY子句中等;
4.数据更新类SQL条件:有多少列经常出现UPDATE或DELETE 的WHERE子句中;
5.SQL量的统计比,如:SELECT:UPDATE+DELETE:INSERT=多少?
6.预计大表及相关联的SQL,每天总的执行量在何数量级?
7.表中的数据:更新为主的业务 还是 查询为主的业务
8.打算采用什么数据库物理服务器,以及数据库服务器架构?
9.并发如何?
10.存储引擎选择InnoDB还是MyISAM?
大致明白以上10个问题,至于如何设计此类的大表,应该什么都清楚了!
至于优化若是指创建好的表,不能变动表结构的话,那建议InnoDB引擎,多利用点内存,减轻磁盘IO负载,因为IO往往是数据库服务器的瓶颈
另外对优化索引结构去解决性能问题的话,建议优先考虑修改类SQL语句,使他们更快些,不得已只靠索引组织结构的方式,当然此话前提是,
索引已经创建的非常好,若是读为主,可以考虑打开query_cache,
以及调整一些参数值:sort_buffer_size,read_buffer_size,read_rnd_buffer_size,join_buffer_size
更多信息参见:
MySQL数据库服务器端核心参数详解和推荐配置
http://www.mysqlops.com/2011/10/26/mysql-variables-one.html
您好,主要是检索某段时间内的模拟量值(select * from table where datatime between t1 and t2 ),目前打算使用分表,分区的方式解决
不纸上谈兵,说一下我的思路以及我的解决,抛砖引玉了
我最近正在解决这个问题
我现在的公司有三张表,是5亿的数据,每天张表每天的增量是100w
每张表大概在10个columns左右
下面是我做的测试和对比
1.首先看engine,在大数据量情况下,在没有做分区的情况下
mysiam比innodb在只读的情况下,效率要高13%左右
2.在做了partition之后,你可以去读一下mysql的官方文档,其实对于partition,专门是对myisam做的优化,对于innodb,所有的数据是存在ibdata里面的,所以即使你可以看到schema变了,其实没有本质的变化
在分区出于同一个physical disk下面的情况下,提升大概只有1%
在 分区在不同的physical disk下,我分到了三个不同的disks下,提升大概在3%,其实所谓的吞吐量,由很多因素决定的,比如你的explain parition时候可以看到,record在那一个分区,如果每个分区都有,其实本质上没有解决读的问题,这样只会提升写的效率。
另外一个问题在于,分区,你怎么分,如果一张表,有三个column都是经常被用于做查询条件的,其实是一件很悲惨的事情,因为你没有办法对所有的sql做针对性的分区,如果你只是如mysql官方文档上说的,只对时间做一个分区,而且你也只用时间查询的话,恭喜你
3. 表主要用来读还是写,其实这个问题是不充分的,应该这样问,你在写入的时候,同时并发的查询多么?我的问题还比较简单,因为mongodb的 shredding支持不能,在crush之后,还是回到mysql,所以在通常情况下,9am-9pm,写入的情况很多,这个时候我会做一个 view,view是基于最近被插入或者经常被查询的,通过做view来分离读取,就是说写是在table上的,读在进行逻辑判断前是在view上操作 的
4做一些archive table,比如先对这些大表做很多已有的统计分析,然后通过已有的分析+增量来解决
5如果你用mysiam,还有一个问题你要注意,如果你的.configure的时候,加了一个max index length参数的时候,当你的record数大于制定长度的时候,这个index会被disable
6
照你的需求来看,可以有两种方式,一种是分表,另一种是分区
首先是分表,就像你自己所说的,可以按月分表,可以按用户ID分表等等,至于采用哪种方式分表,要看你的业务逻辑了,分表不好的地方就是查询有时候需要跨多个表。
然后是分区,分区可以将表分离在若干不同的表空间上,用分而治之的方法来支撑无限膨胀的大表,给大表在物理一级的可管理性。将大表分割成较小的分区可以改善表的维护、备份、恢复、事务及查询性能。分区的好处是分区的优点:
1 增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍然可以使用;
2 减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,故能比整个大表修复花的时间更少;
3 维护轻松:如果需要重建表,独立管理每个分区比管理单个大表要轻松得多;
4 均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能;
5 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快;
6 分区对用户透明,最终用户感觉不到分区的存在。
如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与 插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。 但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还 是需要使用关系性数据库。
虽然关系型数据库在海量数据中逊色于NoSQL数据库,但是如果你操作正确,它的性能还是会满足你的需求的。针对数据的不同操作,其优化方向也是不尽相 同。对于数据移植,查询和插入等操作,可以从不同的方向去考虑。而在优化的时候还需要考虑其他相关操作是否会产生影响。就比如你可以通过创建索引提高查询 性能,但是这会导致插入数据的时候因为要建立更新索引导致插入性能降低,你是否可以接受这一降低那。所以,对数据库的优化是要考虑多个方向,寻找一个折衷 的最佳方案。
一:查询优化
1:创建索引。
最简单也是最常用的优化就是查询。因为对于CRUD操作,read操作是占据了绝大部分的比例,所以read的性能基本上决定了应用的性能。对于查询性能 最常用的就是创建索引。经过测试,2000万条记录,每条记录200字节两列varchar类型的。当不使用索引的时候查询一条记录需要一分钟,而当创建 了索引的时候查询时间可以忽略。但是,当你在已有数据上添加索引的时候,则需要耗费非常大的时间。我插入2000万条记录之后,再创建索引大约话费了几十 分钟的样子。
创建索引的弊端和场合。虽然创建索引可以很大程度上优化查询的速度,但是弊端也是很明显的。一个是在插入数据的时候,创建索引也需要消耗部分的时间,这就 使得插入性能在一定程度上降低;另一个很明显的是数据文件变的更大。在列上创建索引的时候,每条索引的长度是和你创建列的时候制定的长度相同的。比如你创 建varchar(100),当你在该列上创建索引,那么索引的长度则是102字节,因为长度超过64字节则会额外增加2字节记录索引的长度。
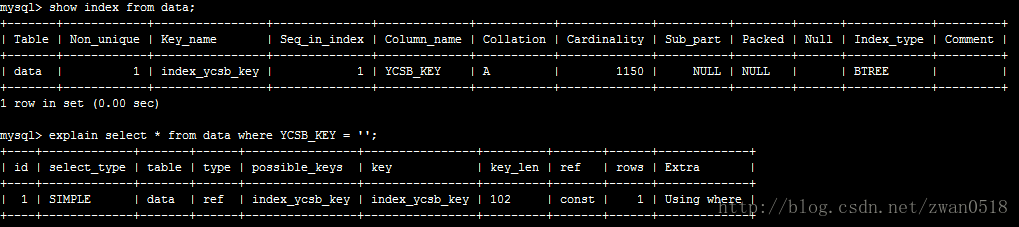
从上图可以看到我在YCSB_KEY这一列(长度100)上创建了一个名字为index_ycsb_key的索引,每条索引长度都为102,想象一下当数 据变的巨大无比的时候,索引的大小也是不可以小觑的。而且从这也可以看出,索引的长度和列类型的长度还不同,比如varchar它是变长的字符类型(请看MySQL数据类型分析),实际存储长度是是实际字符的大小,但是索引却是你声明的长度的大小。你创建列的时候声明100字节,那么索引长度就是这个字节再加上2,它不管你实际存储是多大。
除了创建索引需要消耗时间,索引文件体积会变的越来越大之外,创建索引也需要看的你存储数据的特征。当你存储数据很大一部分都是重复记录,那这个时候创建索引是百害而无一利。请先查看MySQL索引介绍。所以,当很多数据重复的时候,索引带来的查询提升的效果是可以直接忽略的,但是这个时候你还要承受插入数据的时候创建索引带来的性能消耗。
2:缓存的配置。
在MySQL中有多种多样的缓存,有的缓存负责缓存查询语句,也有的负责缓存查询数据。这些缓存内容客户端无法操作,是由server端来维护的。它会随着你查询与修改等相应不同操作进行不断更新。通过其配置文件我们可以看到在MySQL中的缓存:
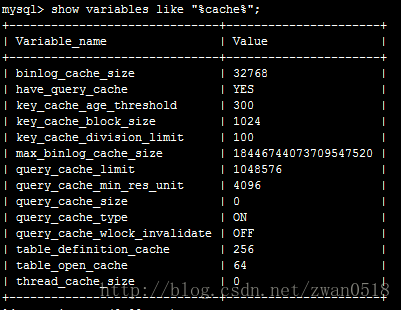
在这里主要分析query cache,它是主要用来缓存查询数据。当你想使用该cache,必须把query_cache_size大小设置为非0。当设置大小为非0的时 候,server会就会缓存每次查询返回的结果,到下次相同查询server就直接从缓存获取数据,而不是再执行查询。能缓存的数据量就和你的size大 小设置有关,所以当你设置的足够大,数据可以完全缓存到内存,速度就会非常之快。
但是,query cache也有它的弊端。当你对数据表做任何的更新操作(update/insert/delete)等操作,server为了保证缓存与数据库的一致 性,会强制刷新缓存数据,导致缓存数据全部失效。所以,当一个表格的更新数据表操作非常多的话,query cache是不会起到查询提升的性能,还会影响其他操作的性能。
3:slow_query_log分析。
其实对于查询性能提升,最重要也是最根本的手段也是slow_query的设置。
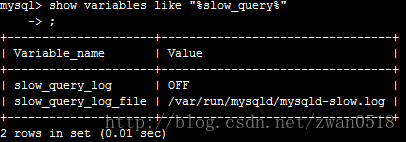
当你设置slow_query_log为on的时候,server端会对每次的查询进行记录,当超过你设置的慢查询时间 (long_query_time)的时候就把该条查询记录到日志。而你对性能进行优化的时候,就可以分析慢查询日志,对慢查询的查询语句进行有目的的优 化。可以通过创建各种索引,可以通过分表等操作。那为什么要分库分表那,当不分库分表的时候那个地方是限制性能的地方啊。下面我们就简单介绍。
4:分库分表
分库分表应该算是查询优化的杀手锏了。上述各种措施在数据量达到一定等级之后,能起到优化的作用已经不明显了。这个时候就必须对数据量进行分流。分流一般有分库与分表两种措施。而分表又有垂直切分与水平切分两种方式。下面我们就针对每一种方式简单介绍。
对于mysql,其数据文件是以文件形式存储在磁盘上的。当一个数据文件过大的时候,操作系统对大文件的操作就会比较麻烦与耗时,而且有的操作系统就不支 持大文件,所以这个时候就必须分表了。另外对于mysql常用的存储引擎是Innodb,它的底层数据结构是B+树。当其数据文件过大的时候,B+树就会 从层次和节点上比较多,当查询一个节点的时候可能会查询很多层次,而这必定会导致多次IO操作进行装载进内存,肯定会耗时的。除此之外还有Innodb对 于B+树的锁机制。对每个节点进行加锁,那么当更改表结构的时候,这时候就会树进行加锁,当表文件大的时候,这可以认为是不可实现的。
所以综上我们就必须进行分表与分库的操作。
二:数据转移
当数据量达到一定等级之后,那么移库将是一个非常慎重又危险的工作。在移库中保证前后数据的一致性,各种突发情况的处理,移库过程中数据的变迁,每一个都是一个非常困难的问题。
2.1:插入数据
待补充。。。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









