






 本文深入探讨了推荐系统中召回阶段的策略、特征选择及实时性问题。召回阶段分为单路召回、多路召回、逐策略召回等不同范式,依据业务场景和用户类型来决定是否需要排序和重排阶段。召回策略涉及用户、物品、上下文特征,而特征使用上,排序阶段和召回阶段有所不同。实时召回和离线召回各有优劣,需要根据业务需求平衡选择。评价召回策略好坏通常依赖线上AB测试。最后,召回阶段的重要性不容忽视,不应因复杂排序模型而妥协。
本文深入探讨了推荐系统中召回阶段的策略、特征选择及实时性问题。召回阶段分为单路召回、多路召回、逐策略召回等不同范式,依据业务场景和用户类型来决定是否需要排序和重排阶段。召回策略涉及用户、物品、上下文特征,而特征使用上,排序阶段和召回阶段有所不同。实时召回和离线召回各有优劣,需要根据业务需求平衡选择。评价召回策略好坏通常依赖线上AB测试。最后,召回阶段的重要性不容忽视,不应因复杂排序模型而妥协。

前言
在当今信息化高速发展的时代,推荐系统是一个热门的话题和技术领域,一些云厂商也提供了推荐系统的SaaS服务比如亚马逊云科技的Amazon Personalize来解决客户从无到有迅速构建推荐系统的痛点和难点。
之前在推荐系统系列精讲(第一讲):推荐系统概览(上) 中我们概览了推荐系统,相信大家已经对推荐系统的各个环节有了一定的认知。为了讨论方便,在本文中我们同样假设只用一种个性化推荐方法(而不是分区混合推荐方法),其他方法都作为个性化推荐的召回策略。
系列文章详见:
https://github.com/yuhuiaws/ML-study/tree/main/
01
针对当前某个具体业务场景,是否需要
召回,排序,重排三阶段?
首先,我们要从本质上看清楚这三个阶段:
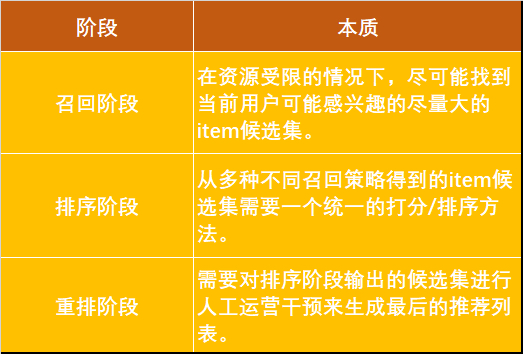
对于召回阶段,或者在线上的时候直接读取保存在 NoSQL 中的离线预先计算好的结果,或者使用高性能的线上item向量相似度检索库来获取 Topk 的结果,所以把整个物品池 item pool 作为输入是可以的也正是我们所想要的,而物品池的物品可能有几百万甚至上千万。
排序阶段一般使用传统机器学习模型或者深度学习模型,为了让模型在有限的时间内能处理完,需要排序阶段的输入 item 数量也就是召回的候选集总数量不能很大(一般是千级别)。
重排阶段最后会生成推荐列表,推荐列表一般不会太长,所以这里的输入 item 数量也就是排序后取的 topK 的 K 数量一般是百级别(这里的输入 item 数量指的是从排序的结果集中选择多少,重排阶段的输入源除了排序后的结果集,在首页推荐场景下,一般还有优选物品集以及需要探索的那些长尾物品集和冷启动物品集)。
如果物品池包括的物品个数是千级别,并且排序模型对全量物品能在要求的处理延迟内处理完,那么根本不需要召回阶段了,直接全量物品排序后接着重排就可以了。从更好的终端用户体验来看,重排阶段任何时候都应该有。
而是否有排序阶段,情况比较复杂,和具体的场景以及是否是长尾用户/冷启动用户有关,具体可以参考如下:
#
对于首页推荐场景的话,一般会有完整的召回,排序,重排三个阶段,首页推荐的时候由于没有办法获得用户当前的意图,一般会使用尽可能多的召回策略,对于长尾用户和冷启动的用户,可能走单独的链路效果更好;对于长尾的用户和冷启动的用户经过召回阶段后,可能不走排序阶段会更好,在重排阶段对召回的结果进行编排以及做探索。
对于详情页推荐或者类似的场景,这个时候用户有了明显的意图,因此相对首页推荐场景来说详情页推荐不会有太多召回策略。如果只有一路召回并且不考虑个性化,这个情况下可以不需要排序阶段。
如果只有一路召回但要考虑个性化,则需要一个复杂的算法/模型引入相关的特征来对单路召回的 topK 的排序结果重新打分排序,这个时候就需要排序阶段。
如果使用了多路召回,对于长尾用户和冷启动用户来说,可能不走排序阶段会更好,使用重排阶段对多路召回的结果进行编排,对于非长尾和冷启动的用户,走排序阶段。
在详情页推荐场景下,冷启动的物品可能通过某种召回策略召回了,可能也不适合走排序阶段,使用重排阶段在某些固定位置给召回的冷启动物品更多的一些曝光机会的效果可能更好。在详情页推荐的场景下,一般不会在重排阶段使用探索方式。
#
小结
不是每个推荐系统的业务场景都需要召回,排序,重排三个阶段!需要根据具体业务场景来判断是否需要召回,排序,重排的任意一个阶段。
02
召回的范式有哪些?
常用的召回策略在推荐系统概览一文中已经有详细的介绍,这里不再赘述。我们这里来介绍召回的范式,需要从三个维度来考虑:召回策略的数量;单个召回策略下是否有粒度更细分的子策略;召回策略是否分优先级,如果分优先级的话,如何对多个召回策略做融合。
按照上面的三个维度,召回的范式有如下的可组合的选择:单路无子策略召回;单路多个子策略逐层召回;多路无子策略召回;多路多个子策略逐层召回;逐策略无子策略召回;逐策略多个子策略逐层召回。
有些业务场景下,某个召回策略是有多个子策略的。比如对于基于地理位置的应用,可能有一路召回策略是基于地理位置的召回,子策略可以是附近召回、当前商圈召回、当前城市召回等等,子策略需要根据业务场景来设置优先级。这种情况下,按照业务逻辑来说,先做附近召回,如果附近召回的item数量不够再考虑做当前商圈召回,以此类推。
对于逐策略来说,也是给每个不同的召回策略分配了不同的优先级。召回的时候,优先对最高优先级的策略做召回,如果召回的item数量达到要求就结束召回过程,否则剩下还需要召回的 item 数量用第二高优先级的策略来做,以此类推。
单路无子策略召回可以用于详情页推荐的场景中。多路多个子策略逐层召回或多路无子策略召回以及逐策略多个子策略逐层召回或逐策略无子策略召回则常用于首页推荐的场景中(当然,详情页推荐用多路召回也是可以的)。
对于多路召回,在总的召回item数量确定的情况下需要给每一路分配多少 item 数量:
不显示区分策略优先级,给每个召回策略分配相同的 item 数量(比如总的需要召回的 item 候选集是1万,可以给每个召回策略分配都是1万,最终通过一个简单的打分粗排模型来选择 top 1万的打分结果)。这种方法需要用一个模型比如LR逻辑回归模型来学习每路的重要性权重,来对各路召回的结果集打分,最终选择 topk 的打分结果集送入下游的排序模型。
对这个模型建模的时候,特征就是一共比如30路的 multi-hot 特征,对于某个 item 的多个路的召回,那么对应的这些路就是1,其他路就是0,label 就是这个item最后是否被点击/感兴趣。在推理时候,多路召回的 item 走一边模型,看最后多路召回的所有不重复 item 的打分,取分数高的就可以。
在给LR模型积累样本的阶段,如果下游的排序模型已经上线,假设总的需要召回的item 候选集是1万,并且一共是10路召回策略,那么这个阶段给每路策略固定1000个item 数量(如果考虑有重复的 item 被召回,那么每路策略可以分配比1000更多一些);如果排序模型还没有上线(可能在推荐系统起步阶段),那么假设最后的推荐列表是100个,一共10路召回策略,那么可以给每路策略分配10个 item(如果考虑有重复的item被召回,那么每路策略可以分配比10更多一些)。
显示设定每个策略的优先级以及每个策略分配的可召回item的数量。
根据最近一段时间统计的某个指标比如点击的召回归因结果来计算出每一路的召回比率(比如7天内整个大盘点击正样本一共1万,归因到热门召回策略的有5000条,那么热门召回策略的召回比率就是50%),然后用总的召回结果条数相乘就得到每一路召回条数(从这里可以看出,对于每一路的召回策略,设定的召回的item条数是随着时间变化的)。
召回归因复杂的地方是,从多路策略或者逐策略召回了相同的itemid,这个 itemid最后归属于哪个策略的问题,可选的有两种方法:一种是多路召回了相同的itemid,那么这个itemid的点击归因到多路上。这种方法的好处是简单直接,直觉上也是合理的。
一种是根据每个策略的历史表现来确定优先级,然后重复出现的itemid会分配给高优先级的那个。
那每个策略的历史表现又是如何计算的?比如可以使用上面提到的方法,也就是不显示区分策略优先级,给每个召回策略分配相同的item数量,然后用一个模型比如LR逻辑回归模型来学习每路的重要性权重。
等这个LR模型训练完以后,就得到了每路策略的重要性权重,从而可以确定每路的优先级。
实际做多路召回的时候,需要考虑在召回的结果不足量(包括因为去重导致的结果不足量)的情况下用高召回率的那路来补足结果。
因此,实际落地的时候一般每一路都会尽量比要求的结果多召回一些,目的是在可能需要补足的时候不用进行二次召回。
而对于逐策略召回的话,不需要考虑给每一路分配多少item的困扰。至于选择多路召回还是逐策略召回,需要具体情况具体分析。这两种方法各有优缺点,逐策略召回不用考虑每路分配多少条结果的问题,而多路召回相对来说对每路召回更公平一点,也就是可能召回效果更好(多路召回更多见一些)。两种范式的具体效果如何,最好还是做线上AB test来对比。
另外,这里会涉到一个相关的问题,即总的召回结果的item条数如何确定:这个没有什么特别的规定,确定的时候最好参考下面的两个因素,如果是做线上召回,那么线上召回的latency是否能满足要求;下游的线上排序模型是否可以在latency容许的范围内处理完这么多的 item。宗旨是只要上面的两个限定条件能满足,设定的总的召回结果的 item 条数就应该尽可能多。
一般来说,召回的结果去重后需要进行过滤然后再送给排序阶段:因为存在比如用户把某个item加入黑名单或者显式“踩“过某个物品,为了更好的用户体验,需要维护一个这样的列表,当召回结果去重以后把命中这个 list 的item 也去掉。
另外,还可以有一个用户最近一段时间发生过行为的 item 列表,比如一个小时内点击过的 item 列表,这样当过滤掉最近发生过行为的item后,客户体验会更好。实践中可能采用 bloom filter 相关的算法来进行过滤,这样的性能更高。
03
召回阶段应该使用哪些种类的特征?
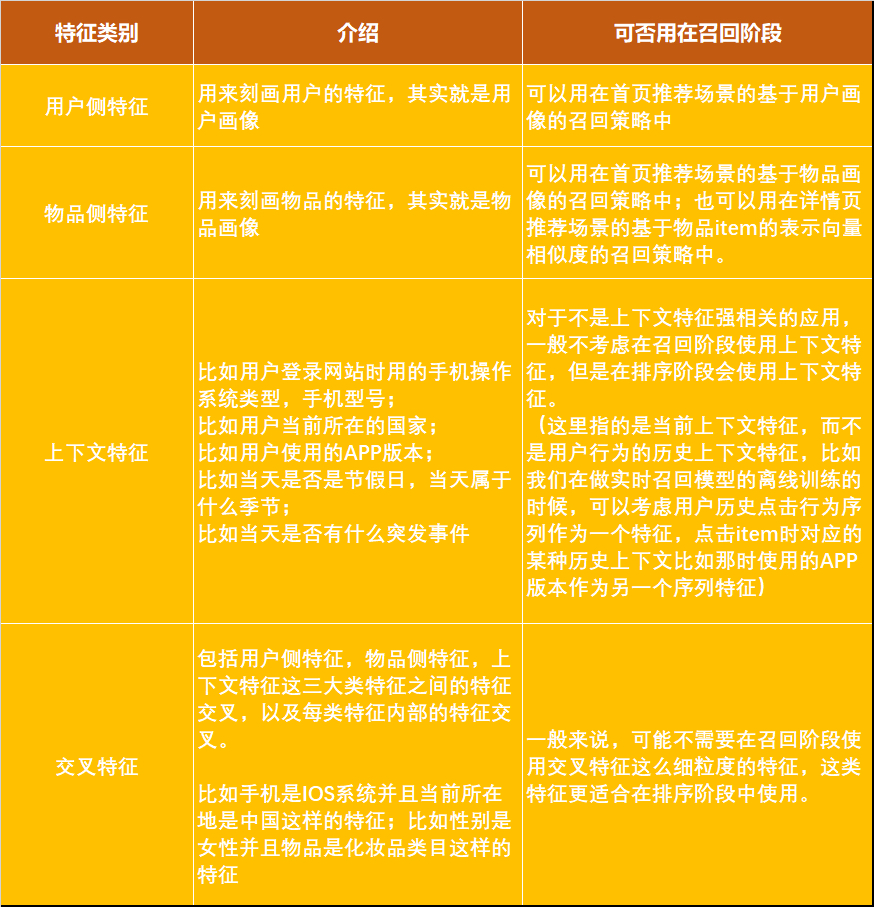
在推荐系统中,我们经常会谈到四大类特征:用户侧特征,物品侧特征,上下文特征,交叉特征 。那是否这四大类特征都适用于召回阶段呢?(这里我们不考虑那些和上下文特征比如地理位置特征强相关的应用,这些应用的召回阶段肯定是需要考虑上下文特征的)
从下面的表格也能看出来,之所以要区分召回阶段和排序阶段,除了之前提到的他们的输入的item集合的量级差别很大之外,他们使用到的特征也是不同的。
04
采用离线的召回结果还是做实时召回?
实时召回指的是在线上服务时对于每一个访问的用户进行重新计算来召回 topK 的 item 集合,支持做实时召回的模型一般需要把用户的最近的行为建模进去,这样该模型基于用户最新的行为可以计算得到一个新的用户的 embedding 向量(实时召回是用在首页推荐场景的),而那些item 向量则是离线用同一个模型计算后并保存在某个高速向量检索库中比如Faiss。
而离线的召回结果指的是离线把每个用户召回的topK 的 item 集合预计算出来保存到某个 NoSQL中,线上服务的时候直接从 NoSQL中取当前用户的 topK 的 item 集合。
据我所知,实时召回的流行是从Youtube DNN召回模型(2016年,如下图所示)发布以后开始的,但是其实类似的工作微软在2013年的 DSSM模型中就有。
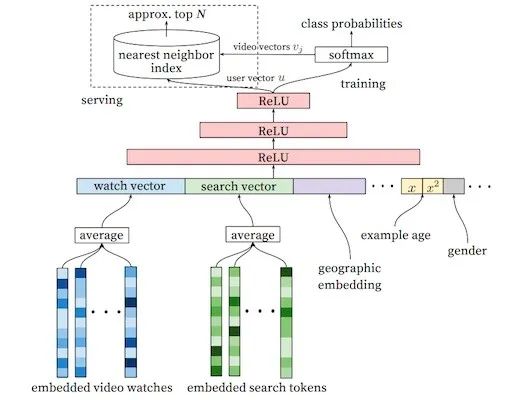
YoutubeDNN召回模型在离线训练完以后,作者建议把最后一个全连接层的权重矩阵[hiden_unit, item_count] 做转置后得到的矩阵的每行对应一个video的output embedding,并把这些video embedding存入到一个近邻索引库中比如Faiss,而user embedding则是在线上根据最新的用户行为特征走一遍模型的前向计算取最后一个全连接层的输出的激活值作为他的 embedding。
Example age(样本年龄)在训练的时候可能指的是这条样本对应的用户当前这次行为发生的时间离当前训练时间的间隔(paper中作者没有对这个特征讲的很清楚,说加上这个特征模型的效果很好),在线上召回的时候该特征需要设置为0。
至于采用离线的召回结果还是做实时召回,需要根据业务场景来权衡。对于实时召回,需要更复杂的系统架构支撑,比如需要通过一个流式处理引擎来实时获得用户最近的点击序列来更新该用户的点击序列特征并喂给模型。
对于离线的召回,线上系统架构实现简单,缺点是时效性没有实时召回那么好。对于某些业务场景来说 ,可能用户的行为没有那么的频繁,那么用小时级别更新的离线的召回方法就比较适合。实际项目中,经常是有一路是实时召回比如 YoutubeDNN 召回模型,其他的是多路的离线召回。
05
所有的用户都走这些召回策略吗?
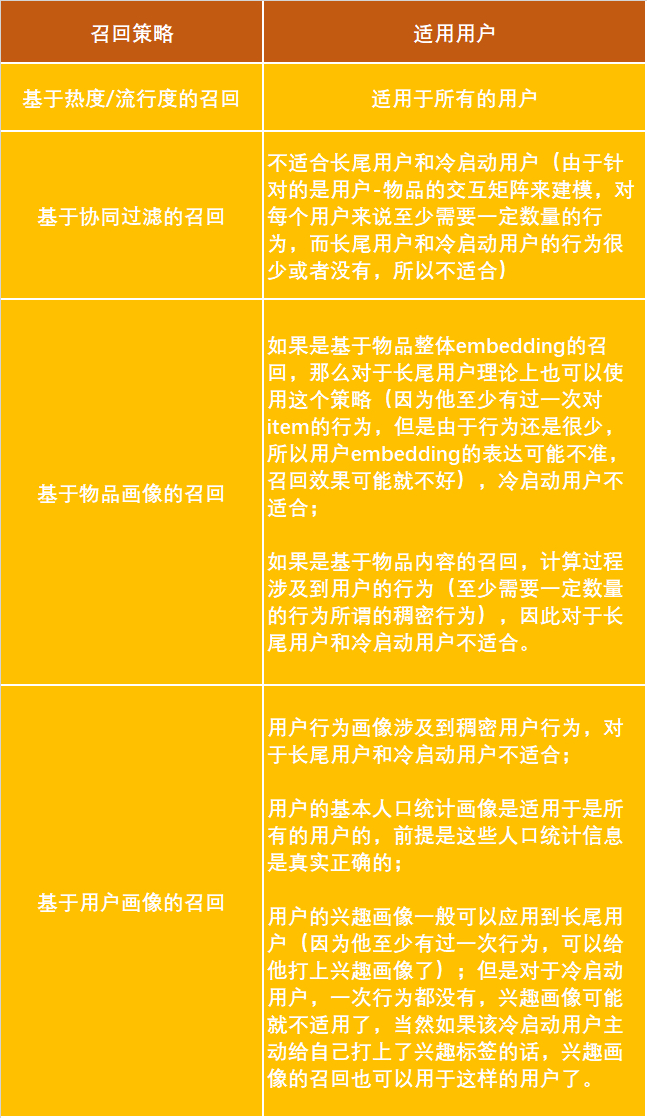
对于详情页推荐,召回策略是以物品item为中心,因此所有用户都可以使用同样的召回策略。
对于首页推荐,如下图:
06
如何评价某个召回策略的好坏?
召回阶段并不是独立存在的,它往往只是整个推荐系统流程的第一步,后面还有排序阶段和重排阶段;而且召回阶段可能还包括多个召回策略。因此对于召回阶段中的某个召回策略没有什么直接的评价,一般也是线上 AB test 看效果。
如果使用机器学习模型来建模的话,对召回策略的评价除了前面提到的线上评价,还包括离线评价(对于比如做实时召回模型的离线评估,一般常用的离线评估指标是AUC)。
07
需要为了将就复杂耗时的排序
模型来削弱召回阶段吗?
一定不可以这样做,不能因为下游的排序模型复杂而反过来削弱召回阶段(比如减少总的召回的 item 的数量)。召回阶段的重要性要大于排序阶段,因此要让排序模型来适配召回阶段,因此不能刻意去追求复杂的大的排序模型。
另外,在计算广告中复杂的大的排序模型可能并不适合在推荐系统中的排序模型用。比如美团的 DPIN深度位置交叉网络模型(用来对位置做 debias 的模型)是用于广告中的排序模型,它是针对召回后的候选集集合以及全部曝光位置联合建模,所以对于推荐系统可能不适合。因为推荐系统的召回后的结果集一般会比较大比如千级别,而广告召回的结果集一般都很小比如不超过100;而且曝光位置的数量他们可能也有数量级的差别。
结语
推荐系统召回阶段的深入探讨到此就讲完了,本文重点讲解了召回的范式,召回阶段使用的特征种类,召回策略适用的用户群体等,相信大家现在已经对召回阶段有了更深刻的理解。我们接下来会进入到排序阶段,介绍排序任务的样本工程和排序模型的调优实践,感谢大家的耐心阅读。
推荐阅读:
推荐系统系列精讲(第二讲):Data-centric AI 之特征工程
本篇作者

梁宇辉
亚马逊云科技
机器学习产品技术专家
负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。

听说,点完下面4个按钮
就不会碰到bug了!


















 9466
9466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









