







生成式 AI 技术正在引发一波新的创新浪潮,许多公司纷纷采用生成式 AI 技术来开发基于大型语言模型(LLM)的产品。
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI 和亚马逊云科技技术等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的人工智能构建生成式 AI 应用程序所需的一系列广泛功能。使用 Amazon Bedrock,客户无需管理任何基础设施,并且可以使用已经熟悉的亚马逊云科技服务将生成式 AI 功能安全地集成和部署到应用程序中。

Amazon Bedrock
扫码查看
由于 LLM 是生成式 AI 产品中的核心组件,当 LLM 调用过程中发生任何故障时,这些产品或功能将变得不可用,因此 LLM APIs(服务)的可用性变得至关重要。为了确保这些基于 LLM 的生成式 AI 的产品能够持续为最终用户提供出色的用户体验,构建更高的可用性和健壮性至关重要,以防止 LLM 服务出现问题时对生成式 AI 产品造成影响。
本文从生成式 AI 应用的多个维度进行了分析,提出了一种综合考虑了复杂程度、成本和可用性目标的高可用性解决方案。客户可以根据自身的业务场景、需求和资源情况,直接应用该解决方案或者对其进行定制化调整,以达到自身的业务目标。
技术分析

生成式 AI 产品技术栈
本文提及的客户(AnyCompany)基于生成式 AI 的应用服务端系统,部署在亚马逊云科技上海外的 Amazon Elastic Kubernetes Service(EKS)集群上。它有一个 LLM API 集成模块(下文称 AI 网关),用于构建、发送和处理对 Amazon Bedrock API 的 API 请求。
AI 网关模块还包含预处理过程(如参数验证)和后处理过程(如数据转换)。AI 网关模块有一个 HTTP 端点,可供 Kubernetes 集群外部的应用程序和服务调用。需要说明的是本解决方案并不局限于使用 Amazon EKS 部署生成式 AI 应用的客户,使用 Amazon EC2、Amazon ECS、 或 Amazon Lambda 部署生成式 AI 应用的客户也可以使用本解决方案来提升应用的可用性和健壮性。
使用 LLM APIs 时面临的可用性挑战分析:
账户限制:亚马逊云科技账户中的 Amazon Bedrock 服务在每个 Amazon Bedrock 提供服务的区域(region)都有一些如每分钟请求数(Request Processed Per Minute)或每分钟处理 token 数(Token Processed Per Minute)的限制。当流量高峰的 RPM 或 TPM 超过亚马逊云科技账户在该区域的 Amazon Bedrock 限制上限时,Amazon Bedrock APIs 接口会返回 ThrottlingException。
Amazon Bedrock 配置错误:由于 Amazon Bedrock 服务配置错误(如未允许某个模型的访问),导致的 Amazon Bedrock APIs 返回异常。
“吵闹的邻居”:在 On-demand 模式下,由于全部用户在同一时间发起请求总数和使用输入/输出 tokens 总数非常多,导致的 Amazon Bedrock APIs 响应在短时间内变慢。

ThrottlingException
扫码查看
解决方案设计时考虑的关键因素:
模型可用性:对于 Amazon Bedrock APIs 可用性的提升,最大化保证 Amazon Bedrock APIs 在前面所列的多种情况下的可用性,从而降低对业务产生的影响,同时尽可能保证对终端用户透明。
亚马逊云科技账户中的 Amazon Bedrock 的区域配额:主要为各区域中每分钟请求数(RPM)或每分钟处理 token 数(TPM)的配额。
延迟(latencies):用于决定跨区域使用 Amazon Bedrock APIs 时,额外的延迟是否能够达到业务的要求,以及决定不同区域在配置中的优先级。
路由策略及其阈值:针对业务需求制定路由策略的灵活性,和各种阈值设置的灵活性。
成本:包含研发成本、运维成本、和云服务成本。设计方案的原则是尽量不额外增加客户现有的成本。
复杂度:方案的复杂度会影响成本。较高的复杂度会增加开发以及未来维护的难度,从而增加额外成本。
理解生成式 AI 应用与 LLM 的延迟
与传统 Web 应用相比,基于 LLM 推理的应用对延迟(latency)的要求不同,这是由 LLM 推理的性质决定的,通常使用参数量越大的 LLM 或执行相对复杂任务的延迟都会比传统 Web 应用大很多。
因此,尽管较低的延迟仍然是首选,客户和最终用户通常可接受基于 LLM 推理的功能具有相对较高的延迟。这一新趋势使得出于提高可用性和健壮性目的,在临近的亚马逊云科技区域使用 Amazon Bedrock APIs 成为可能。
为了评估亚马逊云科技区域之间的延迟,客户可以使用 Amazon Network Manager 中的基础设施性能(Infrastructure Performance)仪表板来监控源亚马逊云科技源区域和目标区域之间延迟的历史数据。然后,客户可以确定如何为其生成式 AI 工作负载设置跨多个区域 Amazon Bedrock 端点(endpoint)的权重列表。

Amazon Network Manager
扫码了解更多

基础设施性能
(Infrastructure Performance)
扫码了解更多
左右滑动查看更多
下面的示例显示了 us-west-2(俄勒冈)区域和 us-east-1(北弗吉尼亚)区域之间的延迟:
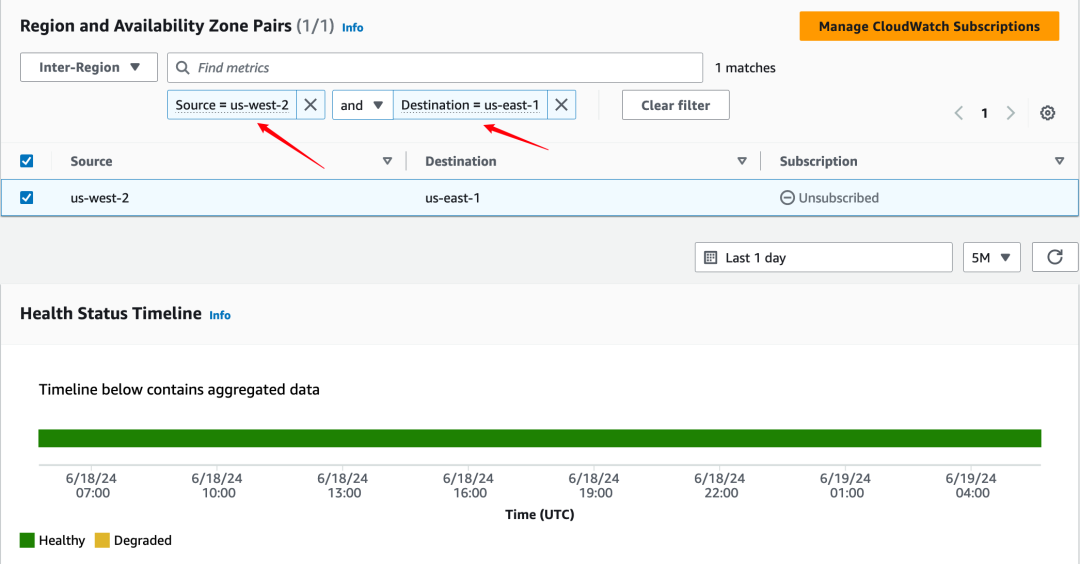
图 1 – 基础设施性能页面(Amazon Network Manager)
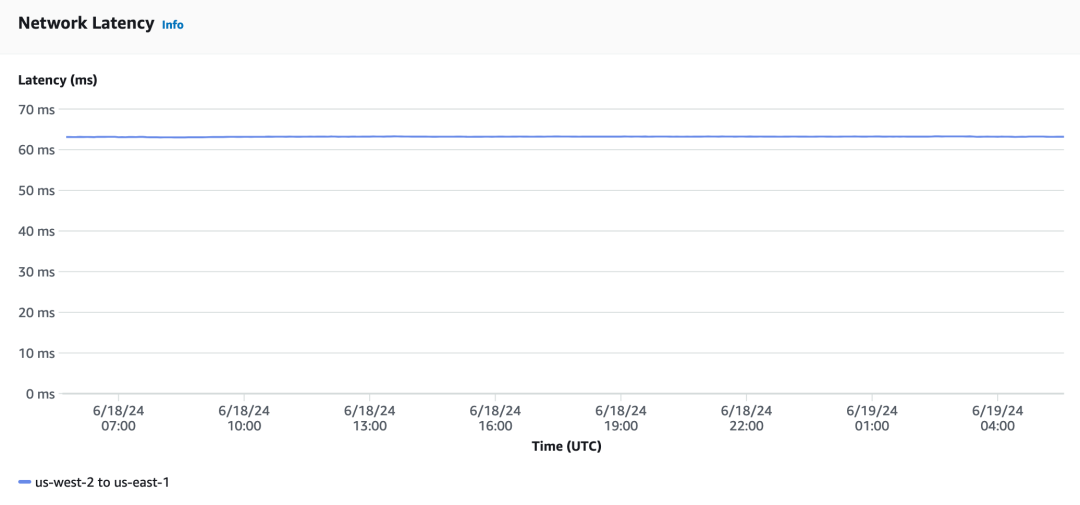
图 2 – us-west-2 和 us-east-1 之间的延迟数据
解决方案
动态跨区域路由模块
由于目前 LLM 迭代速度很快,APIs 可能会出现新增输入参数或新增附加输出字段,所以目前的最佳实践是使用 Amazon SDK 来开发 LLM 相关的 API 集成,这样可以简化开发的复杂度且提升代码的健壮性。在进行 Amazon Bedrock APIs 集成时,推荐使用 Amazon SDK。Amazon SDK for Python(boto3)提供了调用 Amazon Bedrock APIs 时的重试机制(retry mechanism)。
本解决方案将重试机制进一步扩展——在 AI 网关中添加动态跨区域路由模块(Dynamic Cross-Region Routing ),通过最小化代码更改的方式,实现对终端用户透明的跨区域自动重试机制,以提升生成式 AI 应用的可用性和健壮性。
需要注意:您的亚马逊云科技账户使用区域的 Amazon Bedrock 服务 RPM 和 TPM 配额必须足够充足,以满足该解决方案的目的。详情请查看 Amazon Bedrock 的配额。

Amazon Bedrock 配额
扫码查看
动态跨区域路由模块组成
Amazon Bedrock 端点配置文件
Amazon Bedrock 端点配置应该是一个按权重降序排列的列表,其中包含每个 Amazon Bedrock 端点的值及其下一个可用时间(时间戳)。较高的权重值表示更优先使用。例如:

Amazon Bedrock 端点
扫码查看
"bedrock-runtime.us-west-2.amazonaws.com": 1715362643左右滑动查看完整示意
配置文件应通过 Amazon EFS(或与之类似的 NFS 文件系统)在所有 AI 网关 Kubernetes Pods(或其他部署方式,如 Amazon EC2 实例)之间共享。每个部署 AI 网关的区域都应该有其特定的配置文件,以便管理对该区域使用其他区域 Amazon Bedrock APIs 的网络延迟对业务带来的影响。

Amazon EFS
扫码查看
Amazon Bedrock 端点配置示例
使用 HTTP endpoint 请求版本:
[
{
"bedrock-runtime.us-west-2.amazonaws.com": 0
},
{
"bedrock-runtime.us-east-1.amazonaws.com": 0
},
{
"bedrock-runtime.eu-west-3.amazonaws.com": 1715362643
},
{
"bedrock-runtime.ap-southeast-2.amazonaws.com": 0
}
]左右滑动查看完整示意
关键配置
请求 Amazon Bedrock APIs 最多可重试的次数:应用发起一次 Amazon Bedrock APIs 请求,最多可重试的次数。建议值为 3 – 5 次。
是否多区域重试:如果 Amazon Bedrock APIs 暂时没有返回正常响应,则是否在多个区域重试 Amazon Bedrock APIs 请求。
切换到下一个区域前的最大重试次数:在尝试其他区域之前,在每个区域内的最多重试次数。每个区域内的最大重试次数之和不能超过总的最大重试次数。
下一个可用时间前的持续时间:当发送到某一个区域的 Amazon Bedrock API 请求暂时异常时,添加到当前时间的时间窗口(以秒为单位),以设置失败端点下次可用的时间。
动态跨区域重试逻辑概述
动态跨区域重试逻辑应该能够读取 Amazon Bedrock 端点配置文件,并根据下一个可用时间过滤端点,以选择具有最高权重的可用 Amazon Bedrock 端点。
当 APIs 请求失败时,动态跨区域重试逻辑应该将被调用的端点记录下来——以便在后处理过程中为其设置一个新的”下一可用时间”,并更新到 Amazon Bedrock 配置文件。记录完成后,它应从剩余端点列表中选择下一个权重最高的可用端点,来发送重试 API 请求。
重复该过程,直到 AI 网关收到正确的 Amazon Bedrock APIs 响应,或达到配置的最大重试次数或超时时间。
工作流程
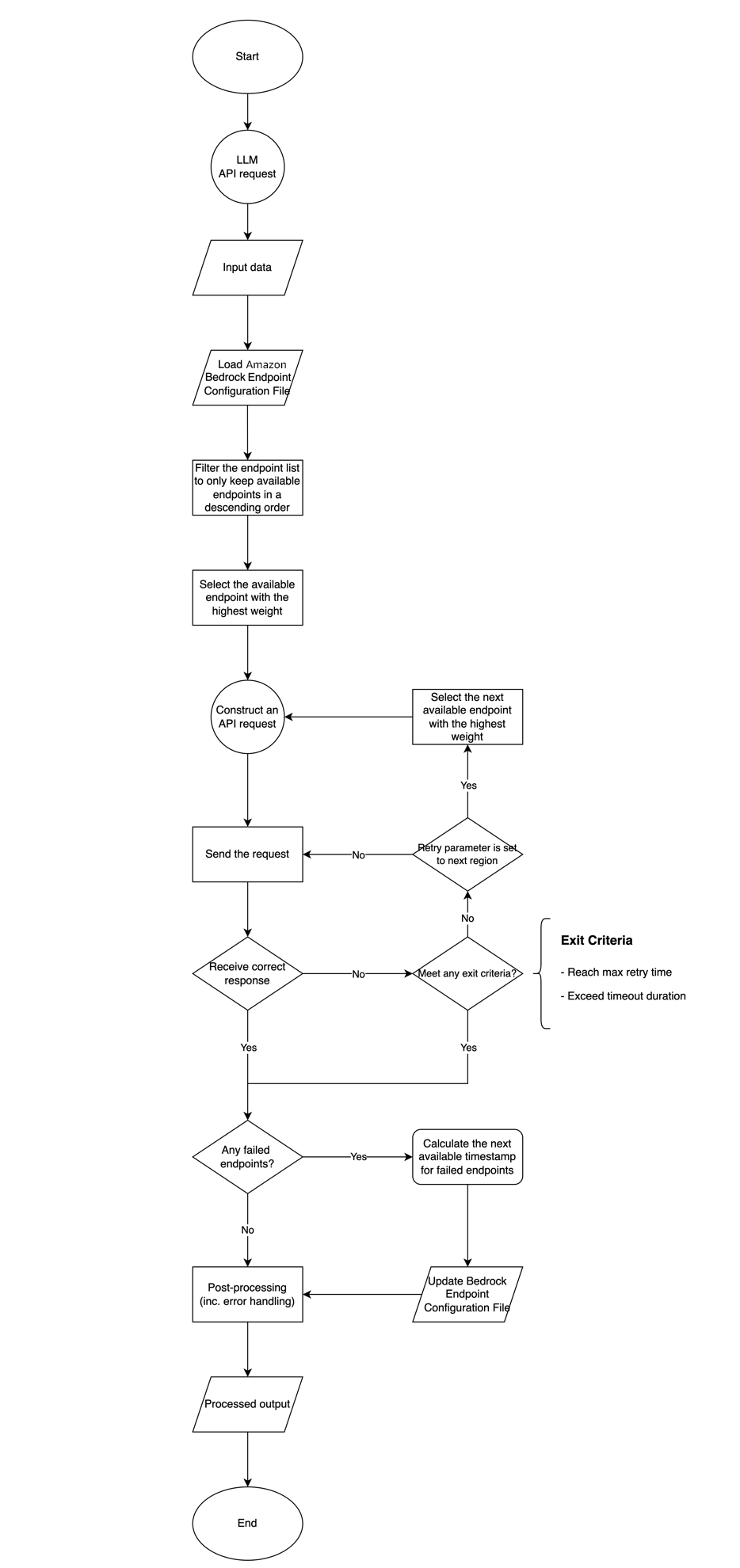
图 3 – 解决方案工作流程图
工作流说明
生成式 AI 应用发起 Amazon Bedrock API 请求:工作流程从 AI 网关模块开始发送 Amazon Bedrock APIs 请求的过程开始。
加载 Amazon Bedrock 端点配置文件:加载包含可用 Amazon Bedrock 端点列表的 Amazon Bedrock 端点配置文件(如 .conf )。
过滤端点列表:根据每个端点的下一个可用时间,过滤端点列表。如果一个端点的“下一个可用时间”大于当前时间,则将该端点从可用端点列表中删除,最终仅保留按降序排列的可用端点。
启动 APIs 发送过程:启动 APIs 发送流程。
选择具有最高权重的可用端点:从过滤后的端点列表中,选择具有最高权重或优先级的可用端点。
构建 APIs 请求:使用所选端点和所需参数构建 Amazon Bedrock APIs 请求。
发送请求:将构建的 APIs 请求发送到所选 Amazon Bedrock 端点。
是否收到正确响应:发送请求后,检查是否从发送的请求中收到正确响应。如果收到正确响应,则继续执行“后处理”步骤。如果未收到正确响应,则进入“重试参数检查”决策点。
退出条件检查:如果未收到正确响应,则评估退出条件,包括达到最大重试时间、超过超时持续时间或其他自定义条件。如果满足退出条件,则继续执行“后处理”步骤进行错误处理。否则,进入“重试参数检查”决策点。
重试参数检查:如果需要重试请求,则流程回到重试过程。如果“多区域重试”参数设置为 True,则流程将选择具有最高权重的下一个可用端点,构建新请求,并循环回到“构建 API 请求”。如果“多区域重试”参数设置为 False,则流程将回到步骤 7 “发送请求”,再次向同一 Amazon Bedrock 端点发送请求。
检查失败的端点:当收到正确响应或满足任何退出条件时,检查前面过程中是否有任何端点失败。如果有端点失败则计算其下一次可用时间戳,以便将其临时从可用端点列表中移除,直到达到“下一次可用时间”再进行重新向其发送请求。
后处理:执行任何必需的后处理任务,如数据转换和错误处理。
更新 Amazon Bedrock 端点配置文件:将新的下一个可用时间戳更新 Amazon Bedrock 端点配置文件。
APIs 响应:将最终 APIs 响应返回给请求者。
该工作流程确保了与 Amazon Bedrock 服务的 API 请求能够通过优先使用可用端点、实现重试机制和根据故障更新端点配置,从而得到高效可靠的处理。该过程旨在为与 Amazon Bedrock APIs 的交互提供一种健壮且高可用的方法。
架构图
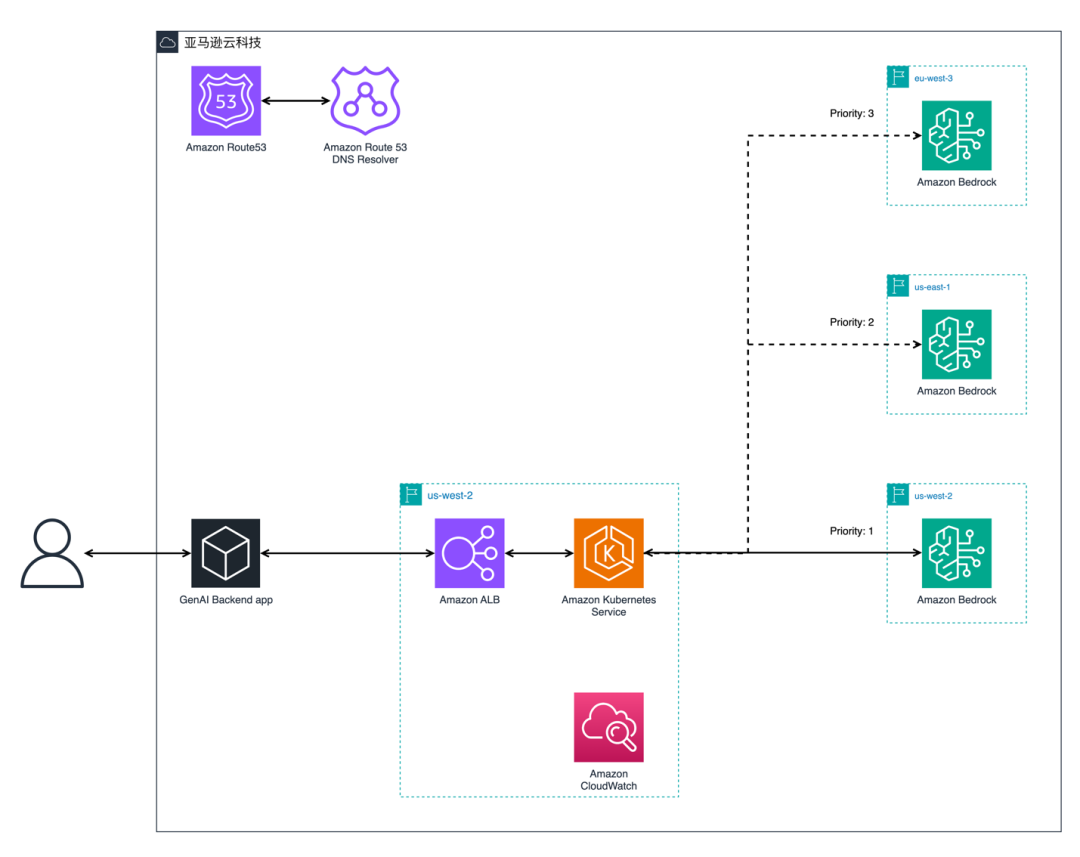
图 4 – 解决方案架构图
本解决方案基于 Python Boto3 的代码实现示例
前置工作:
一个有效的亚马逊云科技账户。
在多个区域开通 Amazon Bedrock 模型的使用。
在 Amazon IAM 中创建 IAM role 并授予 role 足够的权限来访问 Amazon Bedrock APIs。如果通过 IAM user 访问 Amazon Bedrock APIs,则创建对应的 IAM user,并获取该 user 的 Access Key 和 Secret。本示例采用 IAM Role 的方式。
在您运行代码的环境中,安装 boto3(Linux)。

亚马逊云科技账户
扫码了解更多

Amazon Bedrock 模型
扫码查看

Amazon IAM
扫码查看

IAM role
扫码查看
左右滑动查看更多
python3 -m pip install boto3 --upgrade左右滑动查看完整示意
定义 Amazon Bedrock 端点列表配置文件 bedrock_endpoints.conf
本例中设置 4 个可用的 Amazon Bedrock 端点:
[
{
"region": "us-west-2",
"next_available_time": 0
},
{
"region": "us-east-1",
"next_available_time": 0
},
{
"region": "eu-west-3",
"next_available_time": 0
},
{
"region": "ap-southeast-2",
"next_available_time": 0
}
]左右滑动查看完整示意
导入所需类库:
import json
import time
import os
import fcntl
import boto3
import botocore左右滑动查看完整示意
定义全局配置:
MAX_RETRY_TIME = 5
NEXT_RETRY_TIME_WINDOW = 3600
MULTI_REGION_RETRY = True
MAX_RETRY_TIMES_FOR_EACH_REGION = 2
if MULTI_REGION_RETRY:
config_retry_times = 0
else:
MAX_RETRY_TIMES_FOR_EACH_REGION = MAX_RETRY_TIME
config = botocore.config.Config(
read_timeout=900,
connect_timeout=900,
retries={"max_attempts": 0}
)左右滑动查看完整示意
定义过滤端点列表的方法:
def get_validate_regions_from_conf(region_configs):
validate_regions = []
for regional_conf in region_configs:
if regional_conf['next_available_time'] <= current_time:
validate_regions.append(regional_conf['region'])
return validate_regions左右滑动查看完整示意
定义动态跨区域路由请求 Amazon Bedrock APIs 的方法:
def bedrock_invoke_model_message_with_retry(request_data, model_id, validate_regions, max_retry_time):
if len(validate_regions) == 0:
return False
retry_time = 0
accept = 'application/json'
content_type = 'application/json'
for region_name in validate_regions:
if region_name is not None and retry_time < max_retry_time:
bedrock = boto3.client('bedrock-runtime', region_name=region_name, config=config)
for one_region_retry_time in range(MAX_RETRY_TIMES_FOR_EACH_REGION):
if retry_time < max_retry_time:
try:
response = bedrock.invoke_model(body=request_data, modelId=model_id, accept=accept, contentType=content_type)
if response:
return response
else:
if one_region_retry_time == 0:
failed_regions.append(region_name) # Add the region to the failed region list
retry_time += 1
continue
except (botocore.exceptions.ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
if one_region_retry_time == 0:
failed_regions.append(region_name) # Add the region to the failed region list
retry_time += 1
continue
else:
break
else:
break
return False左右滑动查看完整示意
定义更新 Amazon Bedrock 端点配置的方法:
def disable_region_in_conf(raw_region_configs, disable_regions):
# Calcuate failed endpoints' next available time
next_timestamp = current_time + NEXT_RETRY_TIME_WINDOW
disable_count = len(disable_regions)
for region_data in raw_region_configs:
if region_data['region'] in disable_regions:
region_data['next_available_time'] = next_timestamp
return raw_region_configs左右滑动查看完整示意
定义更新 Amazon Bedrock_endpoints.conf 端点列表的方法:
def write_json_to_file_with_lock(file_path, data):
# Convert the Python dictionary to a JSON string
json_data = json.dumps(data)
try:
with open(file_path, 'w') as f:
fcntl.flock(f, fcntl.LOCK_EX)
f.write(json_data)
f.flush()
fcntl.flock(f, fcntl.LOCK_UN)
return True
except IOError as e:
print(f"Error writing to file: {e}")
return False左右滑动查看完整示意
流程测试代码:
# An example of the workflow
current_time = round(time.time())
failed_regions = []
filename = 'bedrock_endpoints.conf'
with open(filename) as f:
endpoint_config = f.read()
raw_region_configs = json.loads(endpoint_config)
print('# CONFIG:', raw_region_configs)
validate_regions = get_validate_regions_from_conf(raw_region_configs)
system_prompt = ''
prompt = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Say Hello",
}
]
}
]
request_body = {"messages": prompt,
"system": system_prompt,
"max_tokens": 2000,
"temperature":0.01,
"top_k":250,
"top_p":0.5,
"anthropic_version": "bedrock-2023-05-31",
"stop_sequences": ["</result>"]
}
body = json.dumps(request_body)
model_id = "anthropic.claude-3-haiku-20240307-v1:0"
response = bedrock_invoke_model_message_with_retry(body, model_id, validate_regions, MAX_RETRY_TIME)
print('# BEDROCK RESPONSE:', response)
if response:
output = json.loads(response.get('body').read())
print('# BEDROCK OUTPUT:', output['content'][0]['text'])
if len(failed_regions) > 0:
new_config = disable_region_in_conf(raw_region_configs, failed_regions)
conf_save_result = write_json_to_file_with_lock(filename, new_config)左右滑动查看完整示意
当成功执行工作流测试代码后,如果 Amazon Bedrock 端点配置正确且至少有一个端点可用,则输出 APIs 正确响应“Hello!”。当 Amazon Bedrock 端点在流程中有请求失败时,配置文件 bedrock_endpoints.conf 的配置内容将会被更新。
总结
本解决方案确保了生成式 AI 应用与 Amazon Bedrock 服务的 APIs 请求能够通过优先使用延迟低且可用的端点、实现重试机制和根据故障更新端点配置,从而 APIs 请求能够得到高效可靠的处理。该过程通过最小化代码修改且“零”额外成本的方式,为与 Amazon Bedrock APIs 的交互提供一种健壮且高可用的方法,提升了生成式 AI 应用在一个区域的可用性及健壮性,保证了业务稳定。
本解决方案的优点为:
复杂度低:整体方案只涉及少量代码修改和配置,部署后无需额外维护,实现简单。
高度可定制化的路由策略:通过代码修改可以实现高度可自定义的路由策略。
即时故障转移:在向客户端返回数据前,即时触发多区域重试机制来避免某一个或几个区域 Amazon Bedrock APIs 异常响应导致的业务不可用。
对最终用户透明:整个重试/故障转移过程对终端用户透明,保证了用户体验。
可控的代码更改:代码修改量小,对整体应用带来的代码变更小。
低维护:路由策略确定以及代码开发和部署完成后,只需要根据业务需求更新 Amazon Bedrock 端点配置文件,无需代码维护。
低成本:利用生成式 AI 现有的云资源,无需额外的云资源来运行该模块。
后续工作
考虑到目前动态跨区域路由模块能够有效地针对单个区域的 APIs 问题提升可用性及健壮性,同时很多生成式 AI 产品采用全球化部署的方式来提升分布在全球各地终端用户的用户体验。因此,后续工作可以聚焦于构建具有自动跨区域路由功能的动态全球 AI 网关。
全球 AI 网关解决方案可以使用 Amazon Route 53 根据 APIs 请求发起者的地理位置将流量路由到部署了 AI 网关的最近区域,并具有健康检查和故障转移机制,以最大程度地提高 AI 网关的可用性和健壮性。
该方案可以结合本文的解决方案,以提供针对 Amazon Bedrock 服务的自动跨区域故障转移功能。
本篇作者

马競斌
亚马逊云科技资深解决方案架构师,致力于帮助客户构建具有优良架构的产品和应用,以及帮助国内客户出海和海外用户进入中国。在互联网行业有十多年产品研发经验和多年技术管理经验,在海外工作多年,是 Serverless 和 Infrastructure as Code 的爱好者。2023 年初开始聚焦生成式 AI,已帮助多个国内知名 IT 公司成功落地了多个生成式 AI 项目。

朱珊
亚马逊云科技客户解决方案经理,目前在亚马逊云科技主要支持泛娱乐行业的客户。通过运用包括云相关解决方案,帮助客户在迁移到亚马逊云科技上运维期间实现自身的业务价值,助力客户成功。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9467
9467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









