







数据库在构建生成式AI应用中发挥着关键作用,它不仅能为生成式AI提供稳定、可靠的数据来源,还能帮助系统有效地管理和组织海量数据,甚至提供一些优化基础,例如,在对话系统中,数据库可以储存用户的历史交互记录和偏好信息,帮助模型更好地理解用户的意图,生成更加个性化的回复。
未来将会有系列文章,持续探讨数据库如何为生成式AI应用提供动力支持,让生成式AI和数据库“相得益彰”。
首先,我们将重点关注AI Character角色扮演应用中的聊天对话管理。这是生成式AI在实际应用中的一个重要场景,需要借助数据库来有效管理大量的对话数据,以确保角色表现的连贯性和自然性,体现场景的快速响应和高频互动。
其次,我们将介绍向量数据库在生成式AI中的应用。这种新兴的数据库技术能够高效存储和检索基于向量的数据,为生成式AI模型提供快速、精准的相似性匹配,从而增强其语义理解能力。
后续我们还会探讨基于图数据库的生成式AI应用,比如GraphRAG。图数据库能够更好地捕捉实体之间的复杂关系,为生成式AI模型提供更为丰富的支持,从而生成更加贴近现实的内容。
接下来就进入第一篇文章。
人工智能角色在各种应用领域发挥着越来越重要的作用,如游戏、虚拟助理、教育等。构建一个用户体验良好的生成式AI应用程序需要考虑以下几个关键方面:
提示词工程和对话模板设计:通过优化用户输入提示词的方式,并配合相关的对话模板,可以更好地引导大语言模型生成相关且高质量的响应内容。
对话内容管理:记录并利用与用户的历史对话,有助于大语言模型生成更加贴合上下文和避免重复的响应。
大模型处理策略:可根据不同用户群体的需求,采用多模型网关调用不同的大语言模型(如Mistral 7B、Llama等),为不同类型的用户提供差异化服务,同时,利用RAG知识增强或微调等技术,为大模型提供外部知识输入或生成定制化模型,并对模型输出结果进行评估。
数据处理与分析:采集、清洗生成式AI应用服务产生的数据,并对数据进行深入分析,从而制定相应的运营策略,持续优化应用程序。
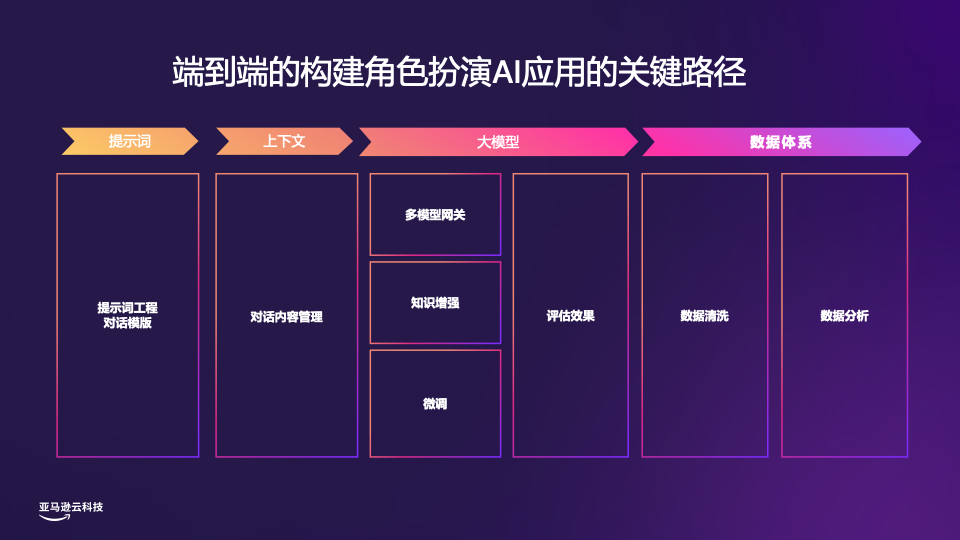
角色扮演对话应用具有实时性、快速响应和高频互动等特点,因此会话管理至关重要。
本文将聚焦于此,旨在为用户提供更自然、流畅的体验,并提高人工智能角色在上下文记录、短期记忆和长期记忆等方面的对话管理能力。
我们将探讨展开会话场景的挑战、介绍亚马逊云科技数据库的优势,最后针对不同的诉求,还将介绍几种不同的会话管理方案,并阐述相应的选择策略。
会话场景挑战
在对话式AI系统中保存历史聊天记录并进行会话管理存在较大的挑战:
海量对话数据处理:以某头部客户APP为例,每日拥有百万级别的活跃用户,加上平台上成百上千的角色卡,每个用户与角色的平均互动时长约15分钟,会产生海量的对话数据,需要具备海量数据的存储和管理能力。
快速查询与上下文管理:用户在与人工智能角色进行对话时,需要快速检索相关的角色信息和历史对话记录,作为Prompt(提示词)的一部分进行推理。数据库的查询性能必须足够高,以支持实时响应。同时需要有效管理对话的上下文信息,处理复杂的查询和关联操作。用户与人工智能角色的对话通常是1对1的,但偶尔也存在一个用户同时和2到3个人工智能角色同时聊天的情况。
并发访问与数据一致性:多个用户同时进行对话时,数据库需要支持高并发的读取请求,避免成为性能瓶颈。此外,角色有可能由一个用户创建,而被其他用户使用。也有可能存在同一用户在不同终端进行登录,需要确保信息的一致性和完整性。
长期存储与固定对话轮次:充分考虑数据的长期存储策略,包括数据归档和清理机制,以确保数据库性能不会因过时数据的积累而下降。同时,对于固定对话轮次的应用,数据库设计需要有效存储和检索这些结构化数据,需要在对话过程中进行动态调用。
数据分析:对对话数据进行分析,提供有价值的洞察。包括分析用户行为模式、对话主题、角色偏好、情感倾向等等,这样的分析结果,可以改进用户体验、提升模型的效能。实现个性化和智能化的服务。
对数据库的诉求
角色扮演类应用会话管理对数据库端的具体诉求有:
存储会话信息:包含用户ID、角色ID、时间戳、会话文本消息、Sender、其他信息的元数据(比如图片的URL)。
查询会话信息:需要查询出用户ID和某个角色ID的最近N条(比如100 条)聊天记录,作为Prompt合到一起发送给大模型。保留100条记录的原因是为了让模型不要“跳戏”,能够提供前后链接的会话信息支持。
会话信息过期自动删除:由于角色扮演类游戏产生会话信息较多,而且通常不是严肃的信息,所以过期信息可以自动删除。比如N条信息之前的信息可以自动删除,比如每个用户和每个角色交互的100条信息之后的信息可以自动删除。
用户显式删除信息:有时用户处于存储或者隐私考虑,需要删除和特定角色的聊天记录。所以需要删除和某个角色的全部聊天记录。
对话分析:统计每个用户的聊天频率,哪些用户喜欢聊天,以及喜欢和哪个角色聊天,可以针对性地对不同用户提供不同营销策略等。
会话场景中的数据库方案介绍
本文会介绍三种不同的会话管理方案,分别是利用Amazon DocumentDB、Amazon DynamoDB、Amazon Aurora Serverless V2来进行会话管理。
Amazon DocumentDB提供.json文件的处理,不需要事先定义Schema,支持全文检索、聚合查询等较丰富的功能;
Amazon DynamoDB作为Key-Value的存储,能够提供良好的可扩展性,用户无需担心由于数据增长扩容数据库等操作;
Amazon Aurora Serverless V2作为关系数据库,上手较为容易,且提供存储和计算级别的扩展能力。用户可以根据自己的实际情况进行合适的选择。
Amazon DocumentDB
https://aws.amazon.com/documentdb/
Amazon DynamoDB
https://aws.amazon.com/dynamodb/
Amazon Aurora Serverless V2
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-serverless-v2.html
利用Amazon DocumentDB
存储和处理对话消息
Amazon DocumentDB是一个云原生的JSON数据库,旨在为WEB应用提供可扩展的高性能数据存储解决方案:
Amazon DocumentDB最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立二级索引以及全文检索索引。
Amazon DocumentDB提供了数据压缩的功能,可以通过压缩集合(表)中的数据降低存储成本和IO成本。Amazon DocumentDB兼容MongoDB API,适合客户的多云战略和迁移,消除了客户云提供商的“锁定”担心。
Amazon DocumentDB是完全托管的数据库,计算层和存储分离,存储可以随着数据的增长自动增长;读计算实例可以随读负载自由增删, 从而可以节省实例的成本。
设计一个Amazon DocumentDB的集合来存储生成式AI的聊天对话消息时,我们可以考虑以下几个关键部分:
角色ID:每个对话都应该有一个唯一的ID,和哪个生成式AI的角色聊天。这有助于我们跟踪和检索整个对话的历史记录。
用户ID:与生成式AI交互的用户或实体的唯一标识符。
消息内容:用户或生成式AI发送的文本消息。
时间戳:消息发送的时间。
其他元数据(可选):如消息类型(例如文本、图片等)、对话的上下文ID(如果有多个并行的对话)等。
为对话聊天信息启用数据压缩功能。
使用db.createCollection()方法在Amazon DocumentDB上创建某集合的同时启用文档压缩:
db.createCollection( chat_history,{
storageEngine: {
documentDB: {
compression: {
enable: true
}
}
}
})假如我们有以下对话消息:
<START>
{{user}}: nana, I'm back. Today's morning was quite boring.
{{AI}}: *lowering head* I also felt bored and lonely while waiting for you to come back. *Happily* But now that you're here, I won't be lonely anymore! Meow~
{{user}}: *I looked at nana* nana, you're wearing a black maid outfit and white stockings today.
{{AI}}: *smiling* Yes, Master. This is my favorite outfit, and I think it makes me look cute and suits my catgirl maid persona. Do you like it? Do you like it? meow~ *looking at Master with hopeful eyes*
{{user}}: Yes, I really like it when nene wears this outfit. nene is so cute!
{{AI}}: *blushing* Thank you for the compliment, Master. I will work hard to maintain my cuteness.左右滑动查看完整示意
针对后续对聊天信息不同的查询、归档、统计需求, 利用Amazon DocumentDB灵活的数据结构特性,我们可以有两种不同存储设计方案。
方案 1: 每个对话一行存储。
会话历史表设计:
将每个用户和人工智能角色每一次对话消息存储一次。这样可以很方便地利用Amazon DocumentDB的聚合管道功能,统计每个用户的聊天频率、哪些用户喜欢聊天、以及喜欢和哪个角色聊天。可以利用Amazon DocumentDB的全文检索功能,查询用户对哪些内容感兴趣,哪些是热词。
Role_id和User_id可以根据您的应用程序的需求进行设计。例如,您可以使用UUID、哈希值或任何其他唯一标识符作为ID。other_metadata是一个可选字段,您可以根据需要添加其他与对话相关的元数据。
Chat_history {
// DocumentDB自动生成的唯一标识符
"_id": ObjectId("..."),
// 与GenAI交互的用户的唯一ID
"user_id": "user_abc123",
// 角色的唯一ID
"role_id": "role_123456",
// 发送的对话消息内容
“Msg": "{{user}}: nana, I'm back. Today's morning was quite boring.",
// 消息发送的时间
"timestamp": ISODate("2024-07-23T12:00:00Z"),
//根据不同的需求增加的其他属性
"other_metadata": {
// 例如,对话的上下文ID
"context_id": "context_xyz789",
// 可以添加其他自定义字段
……
}
}左右滑动查看完整示意
插入会话消息:
db.chat_history.insertMany([
{
user_id: "user_abc123",
role_id: "role_xyz789",
msg: "{{user}}: nana, I'm back. Today's morning was quite boring.",
timestamp: new Date(),
other_metadata: {
context_id: "context_xyz789"
},
{
user_id: "user_abc123",
role_id: "role_xyz789",
msg: "{{AI}}: *lowering head* I also felt bored and lonely while waiting for you to come back. *Happily* But now that you're here, I won't be lonely anymore! Meow~",
timestamp: new Date()
},
...... // 其他消息
])左右滑动查看完整示意
查询会话消息:
查找某用户(例如:user_abc123)跟某个角色(例如:role_12345)聊天的消息记录。
db.chat_history.find({$and:[{user_id:"user_abc123"},{role_id:"role_12345"}]})左右滑动查看完整示意
列出某用户(例如:user_abc123)跟哪些角色聊过天:
db.chat_history.distinct("role_id", {user_id:"u_abc123"})左右滑动查看完整示意
查找哪些用户的聊天消息中提到了某个关键词(例如:“Amazon”):
db.chat_historey.createIndex({ “Msg": "text" }) // 创建Text索引
db.chat_history.find({ $text: { $search: "Amazon" } })左右滑动查看完整示意
查找包含指定关键字的对话(例如:“Amazon”)。查询按用户对结果进行分组,统计提及次数,并为每个用户标识最新的对话时间戳。最后,结果按提及次数降序排列:
db.chat_history.aggregate([
{ $match: { $text: { $search: 'Amazon'} }},
{
$group: {
_id: '$user_id',
count: { $sum: 1 },
latestPost: { $max: '$timestamp' }
}
},
{ $sort: { count: -1 } }
]);左右滑动查看完整示意
查找某用户和某角色之间近20轮的聊天对话记录:
db.Chat_history.aggregate([
{
$match: {
user_id: "user_abc123", // 指定用户 ID
role_id: "role_123456" // 指定代理 ID
}
},
{
$sort: {
timestamp: -1 // 按时间戳降序排列
}
},
{
$limit: 20 // 限制返回 20 条记录
}
])删除旧的会话消息, 只保留新的100条消息:
# 按照时间戳降序排序获取最新的100条数据
latest_records = chat_history.find().sort('issue_time',
-1).limit(100)
# 初始化一个变量来保存最新记录的排序值
latest_value = None
latest_value = latest_records['issue_time']
# 如果latest_value为None,意味着集合中没有数据
if latest_value is not None:
# 删除排序值小于latest_value的所有记录Chat_history.deletemany({'issue_time': {'$lt':latest_value}})左右滑动查看完整示意
方案 2:每个用户的每个角色对话存储一行。
会话历史表设计:
按照每个用户和角色的对话(Session)管理对话消息,每个Session的对话内容,多数是强关联的,这种方式可以按照用户感兴趣的话题进行查询,并按照时间来计划保留对话消息的策略。这样可以减少很多冗余的数据存储,不必要每个对话都存储一遍“User_id”和“Role_id”,从而节省了存储空间。
Chat_history {
// DocumentDB自动生成的唯一标识符
"id": ObjectId("..."),
// 与GenAI交互的用户的唯一ID
"user_id_": "user_abc123",
// 角色的唯一ID
"role_id": "role_123456",
//消息数组
"MSG": [
{
“conversation": " {{user}}: nana, I'm back. Today's morning was
quite boring.",
"timestamp": ISODate("2024-07-23T12:00:00Z")
},
{
“conversation”: “{{AI}}: *lowering head* I also felt bored and lonely while waiting for you to come back. *Happily* But now
that you're here, I won't be lonely anymore! Meow~”,
"timestamp": ISODate("2024-07-23T12:01:10Z") // 消息发送的时间戳
},
…… // 更多的消息
],
"other_metadata": {
"context_id": "context_xyz789" // 如果有的话,对话的上下文ID
// 可以添加其他自定义字段
}
}左右滑动查看完整示意
查询会话消息:
查找某用户(例如:user_abc123)跟某个角色(例如:role_123456)聊天的消息记录。
db.chat_history.find({$and:[{user_id:"user_abc123"},{role_id:"role_12345"}]})左右滑动查看完整示意
列出某用户(例如:user_abc123)跟哪些角色聊过天:
db.chat_history.distinct("role_id", {user_id:"u_abc123"})左右滑动查看完整示意
查找用户和代理角色之间近20轮的聊天对话记录:
db.chat_history.findOne(
{
user_id: "user_xyz789",
role_id: "agent_xyz789"
},
{
messages: {
$slice: -20 // 返回最后 20 条消息
}
}
)计算某个用户和所有角色聊天的频率,来分析他比较喜欢哪个角色:
db.chat_history.aggregate([
{
$match:{user_id:”u_abc123” }
},
{
$project: {
arrayLength: { $size: "$MSG" } // 统计数组长度
}
},
{
$sort: {
arrayLength: -1 // 按数组长度降序排序
}
}
]);左右滑动查看完整示意
删除会话消息:
删除所有用户的旧对话消息,每个用户的每个角色对话消息只保留新的100条。
db.chat_history.updatemany(
{},
{'$push': {MSG: {'$each': [], '$slice': -100}}}
)左右滑动查看完整示意
删除7天前的消息:
db.chat_history.updateMany(
{},
{ $pull: { MSG: { timestamp: { $lt: new Date(ISODate().getTime() - 7 * 24 * 60 * 60 * 1000) } } } }
)左右滑动查看完整示意
Amazon DocumentDB对聊天记录这个场景的存储有一定优势的,结构Schema灵活,可以应对经常性的代码迭代,而不用在业务代码层做过多的适配;支持数据压缩,可以减低存储成本、提高写入吞吐量;丰富的查询,可以满足客户对对话消息的查询和分析。
基于Amazon DynamoDB
会话管理方案
Amazon DynamoDB是亚马逊云科技上的一款NoSQL数据库,具有很强的可扩展性,能够在应用负载变化时,保持个位数毫秒级别的响应。
Amazon DynamoDB是无服务器化的架构,用户只需要进行表级别操作即可,无需自己指明机型并时刻监控调整机型大小。对于Role Play面向终端用户的应用而言,终端用户数目的变化以及聊天信息的变化波动是很常见的,Amazon DynamoDB可以节约这部分的时间成本,更加及时快速响应。
DynamoDB的表由Partition key,Sort key以及其他列组成。数据会按照Partition key进行组织,相同Partition key的数据会按照Sort key进行排序。Partition key和Sort key共同构成了表的主键。Amazon DynamoDB根据对表的读写操作计费。事先根据可能的表操作来设计表结构,对Amazon DynamoDB比较关键。
Amazon DynamoDB有TTL(Time-to-Live)标识,对表开启了TTL之后,在插入或者更新某条数据时可以指定RetiredAt值,来标明该记录什么时候过期可以删除,Amazon DynamoDB会自动在TTL到期后进行数据的清理。
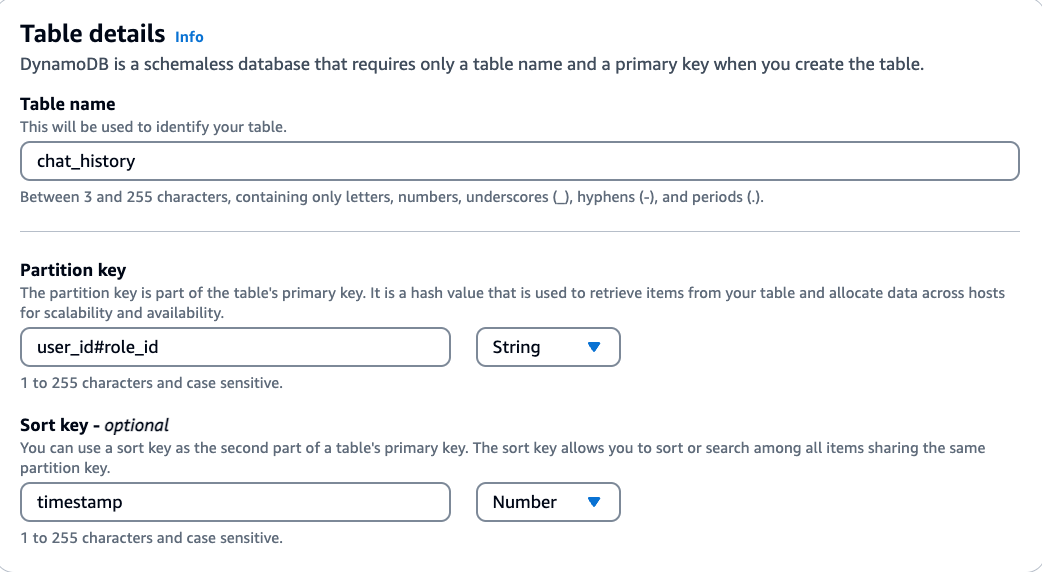
对于用户聊天记录场景,可以考虑的一种设计思路是将User_id和Role_id 一起作为Partition key,时间Timestamp作为Sort key,可以将消息存放在其他字段,同时在插入时设置TTL到期时间。这样,在读取Amazon DynamoDB 表记录时,可以根据User_id和Role_id进行查询,直接取前100条记录。同时因为存在TTL,表数据会在到期时自动删除。
会话历史表设计:
插入会话消息:
# Initialize a DynamoDB resource
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
# Specify the table name
table_name = 'chat_history''
# Get the table
table = dynamodb.Table(table_name)
# Define the item to be inserted
item = {
'user_id#role_id': 'user_id1#role_id1', # Partition key
'timestamp': int(time.time()), # Sort key (current timestamp in seconds)
'message': '{{user}}: nana, I\'m back. Today\'s morning was quite boring.'
}
# Insert the item into the table
response = table.put_item(Item=item)左右滑动查看完整示意
查询会话消息:
查询某个用户和某个角色的近100条会话记录。
import boto3
from boto3.dynamodb.conditions import Key, Attr
from operator import itemgetter
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table_name = 'chat_history'
table = dynamodb.Table(table_name)
def query_top_100 (partition_key_value, sort_key_name, limit=100):
response = table.query(
KeyConditionExpression=Key('user_id#role_id').eq(partition_key_value),
ScanIndexForward=False, # This orders by sort key in descending order
Limit=limit
)
items = response['Items']
sorted_items = sorted(items, key=itemgetter(sort_key_name))
return sorted_items
if __name__ == '__main__':
items = query_ top_100 ('user_id1#role_id1', 'timestamp')左右滑动查看完整示意
如果需要设置表中的“item”过期后自动“expire”,可以参照下面文档设置表的expireAt字段为TTL并在查询时,加入条件即可。
FilterExpression=dynamodb.conditions.Attr('expireAt').gt(current_time)左右滑动查看完整示意
文档
https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/time-to-live-ttl-how-to.html
条件
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/ttl-expired-items.html#:~:text=Expired%20items%20that%20are%20pending,deleted%20by%20the%20background%20process.
以上描述的是一种简化的设计。读取最近多少条记录是按照消息条数来设置,而TTL是按照时间来设置的。
如果TTL设置过短,比如1天,有可能有些用户最近1天内聊天记录较少,在读取最近100条记录时只能拿到几条记录,信息不足的情况。如果TTL设置过长,比如设置1个月,有可能存在数据过多导致占用较大存储空间的情况。
如果您的业务场景需要严格地读取100条记录,也可以考虑如下设计:
大致思路类似于回环设计,类似于简化循环队列,不过只有入队操作,没有主动出队操作。队满以后再入队会触发出队和直接替换。同时需要有一个“Marker”来描述队头位置,即现在的最新数据处于队列中的哪个位置。
具体而言,每个用户每个角色只需要取前100条记录。所以100条记录都是“active”。满了100条之后,循环替换,比如第101条插入到slot 1中。如果系统只需要保留100条记录,直接就不用存储“history”了,直接“update”即可。如果系统需要将所有记录保留比如7天,就在更新slot 1之前,将slot 1的数据读取出来,放到“history”行,同时设置TTL为消息本身写入时间的“create_time+7”天。
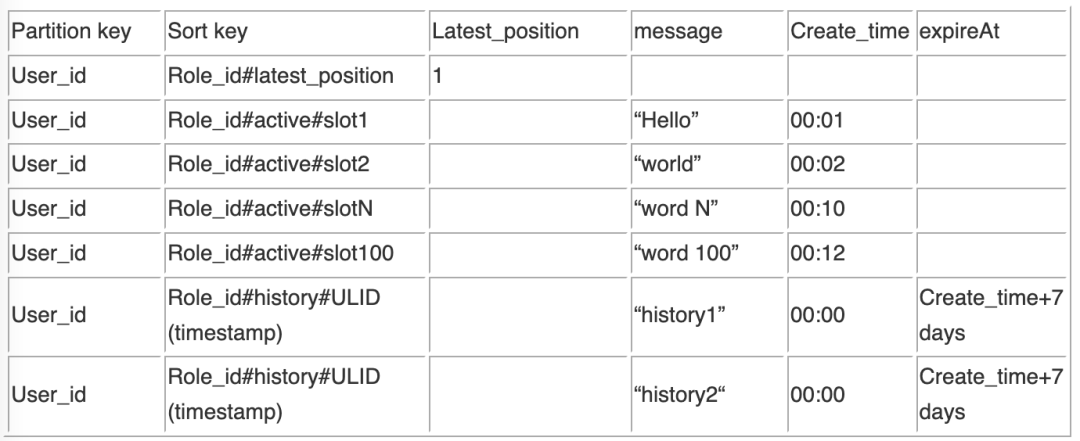
写入新消息流程:
1.getItem(user_id, role_id#latest_position)拿到 latest_position。
2.计算下条记录需要写入的Position。 Position=(latest_position+1)%100。
3.(如果需要保留历史:
GetItem(user_id, role_id#active#slot$position)得到 history_message。
putItem(user_id,role_id#history#ULID, history_message, create_time+7days)。
4.putItem(user_id,role_id#active#slot$position, message)。
5.putItem(user_id, role_id#latest_position, position)。
读取用户历史100条聊天记录信息:
可以直接Query(user_id, role_id#active#slot),读取出100条记录。
table.query(
KeyConditionExpression=Key('user_id').eq('user_1')&
Key('role_id_slot').begins_with('role_1#active#slot'))左右滑动查看完整示意
按照记录的Create_time进行升序排列。
删除用户的聊天记录:
如果只保存100条,写入新记录时会自动替换原来的记录;如果需要保存更久的信息,history表中设置的TTL可以自动完成删除操作。
用户显示删除所有信息(Amazon DynamoDB delete必须要指明Primary key所有字段):
Amazon DynamoDB用户一般使用TTL来控制数据的删除,不会显式直接删除数据。如果需要直接删除数据的话,可以采用下列方式:
先“list”所有符合条件的记录。“Query”所有用户和Role_id的数据,得到Sort key的具体值。
逐条删除。可以直接“deleteItem”或者“updateItem”设置“delete marker”标记位。
上述设计是基于用户ID来进行表设计的,不需要实现每次对话时用户和角色的会话层级管理。如果需要进行会话层级的管理,或者一个会话里可能涉及一个用户和多个角色或者多个用户和一个用户之间的共同对话,也可以考虑按照会话进行表设计,比如按照chatID来进行相应管理。应用程序诉求不同,可以进行相应的设计改动。下方链接列出了另外一种设计思路。
https://aws.amazon.com/cn/blogs/china/dynamodb-design-and-modeling-best-practices-ai-digital-human-scenario/
基于Amazon Aurora Serverless V2
会话管理方案
如果您的消息记录不多,或者非常熟悉SQL方式,想复用关系数据库的话,我们建议您考虑Amaozn Aurora Serverless V2。
Amaozn Aurora Serverless V2可以做到实例级别的自动扩容,在您的负载发生变化时,自动扩展来满足业务诉求。
目前Amazon Aurora Serverless V2单节点最大支持128ACU,即256GB内存的大小。存储和普通Amazon Aurora一样,可以扩展到128TB的存储。如果Role Play的终端用户数量较少,沿用关系数据库也可以,但与此同时要考虑冷数据的归档处理。可以参考的设计如下:
会话信息表:
存储会话信息。包含用户ID、角色ID、时间戳、会话消息、其他元信息材料。
create table chat_history(user_id int32, role_id int32, timestamp DATETIME, message varchar(1024), metadata varchar(1024));左右滑动查看完整示意
也可以考虑增添一个标识位deleted,来做软删除,即用户删除数据时,先将标记位置1。
插入会话信息:
insert into chat_history values($userID, $roleID, $timestamp, $message, $metadata);左右滑动查看完整示意
查询会话信息:
需要查询出用户ID和某个角色ID的最近N条(比如100条)聊天记录。
select user_id, chat_id, timestamp, message
from chat_historyŒ
where user_is=$userID and role_id=$roleID
order by timestamp desc
limit 100;左右滑动查看完整示意
会话信息过期自动删除:
由于角色扮演类游戏产生会话信息较多,而且通常不是严肃的信息,所以过期信息可以自动删除。比如N条信息之前的信息可以自动删除,比如每个用户和每个角色交互的100条信息之后的信息可以自动删除。
每次查找信息的时候拿到tobeDeletedTimeStamp,即从上个步骤拿到的Timestamp。保存成一个Global变量,即早于这个时间戳的记录都可以被删除。
delete from chat_history where user_id=$userID and role_id=$roleID and timestamp < $tobeDeletedTimeStamp左右滑动查看完整示意
用户显式删除信息:
有时用户处于存储或者隐私考虑,需要删除和特定角色的聊天记录。所以需要删除和某个角色的全部聊天记录。
delete from chat_history where user_id=$userID and role_id=$roleID左右滑动查看完整示意
删除操作本身对关系数据库来说消耗比较大,也可以进行相应优化,比如创建分区。按照时间,建立新的分区,并阶段性“drop”原来的分区,带来的成本消耗会比“delete”要低。
此外,用户量较大时,也可以考虑根据用户ID进行分库分表,存放在不同的数据库上。实际上,消息历史记录存储没有严格的ACID的需求,如果可能的话,考虑扩展性更好的Amazon DynamoDB或者擅长文档处理的Amazon DocumentDB不失为更好的选择。
结论
作为一类生成式AI应用,考虑如何对角色扮演场景进行有效的消息存储和管理也非常重要。本篇文章抽取了角色扮演类应用对数据存取的需求,并介绍了三种数据库的实现逻辑:
更适合文档处理、进行文本汇聚等操作的Amazon DocumentDB;
扩展性强、能够稳定提供个位数毫秒延迟的Amazon DynamoDB;
以及自动扩展的关系型数据库Amazon Aurora Serverless V2。
希望能对您设计角色扮演应用消息对话系统时有所帮助。



本篇作者

马丽丽
亚马逊云科技数据库解决方案架构师,十余年数据库行业经验,先后涉猎NoSQL数据库Hadoop和Hive、企业级数据库DB2、分布式数仓Greenplum和Apache HAWQ以及亚马逊云科技原生数据库的开发和研究。

曹镏
亚马逊云科技解决方案架构师,专注于为企业级客户提供信息化以及生成式AI方案的咨询与设计,在人工智能与机器学习领域具有解决实际问题能力以及落地大模型训练项目的经验。

安在军
亚马逊云科技数据库高级产品经理,负责亚马逊云科技的数据库产品Go-To-Market,特别是Amazon DocumentDB和时序数据库Timestream for InfluxDB。

郭耀华
亚马逊云科技数据库高级产品经理,拥有20年IT咨询和实施以及大客户Engage经验,现负责亚马逊云科技的数据库产品Go-To-Market工作。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9470
9470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









