







图片搜索可以提高零售业务和电子商务中的客户参与度,尤其是对服装类(衣服、裤子、鞋、服装饰品等)零售商而言。服装类是在图片搜索中最重要的产品类型。调研报告显示有36%的消费者曾经使用过图片搜索,有74%的消费者认为传统的文字搜索很难帮助他们找到正确的产品。
由于行业的特性,服装类大多具有非常高的相似度,比如运动鞋和衣服,大多数鞋的形状和风格非常类似,需要通过非常细粒度的特征来进行识别。比如下面不一样型号的鞋子,会非常相似。

本篇文章将介绍如何从头构建一个鞋服类的垂直模型,从而实现低延迟,高精度的图片搜索解决方案。该方案主要集成Amazon SageMaker、关系数据库Amazon Aurora MySQL以及向量数据存储服务Amazon OpenSearch。
业务需求分解
基于对象的高效搜索:当用户输入的图片中同时存在多个商品或目标时,允许用户在图像中搜索特定的对象或物品,这样他们能够只搜索感兴趣的产品,而不是搜索整个图像。这种功能可以提高搜索效率,让用户更快地找到所需内容。
自动产品识别:系统能够自动识别图像中的产品。将来,这项功能可以与电子商务平台集成,根据识别出的产品向用户推荐相关商品,促进销售。
搜索准确性:用户搜索的图片和索引库中待比对的图片在不同角度、不同光线条件下拍摄,系统在万级别品类下,Top5的召回也能够达到85%以上的准确率,将产品与相关图像正确匹配,这是基于对图像视觉特征的分析。高准确度可以确保搜索结果的相关性。
安全和隐私:系统可以进行私有化部署,并确保符合相关的隐私法规和合规要求。
索引和存储:系统需要高效地索引和存储超过100万张图像数据,以及相关的元数据,如标签、描述和其他相关信息,以支持快速搜索和检索。
整体方案
方案步骤
离线处理:
启动一个Notebook读取Amazon S3里面的所有的图片。
调用Amazon Bedrock进行图片打标处理,用于过滤用来训练的数据。
打完标记的结果放到Amazon Aurora Mysql里面保存。
启动Amazon Sagemaker的模型训练节点,使用过滤后的训练数据进行训练。将训练完后的embedding模型部署到Amazon Sagemaker。
调用embedding模型对现有的所有产品图片进行embedding,结果存入Amazon OpenSearch。
实时处理:
前端通过Amazon Cloudfront加载页面和产品图片。
Amazon Cloudfront读取Amazon S3中的静态数据。
当上传图片的时候,Amazon Cloudfront会将请求转发到Amazon API Gateway。
Amazon API Gateway请求转发到Amazon EC2。
Amazon EC2将图片发送Amazon Lambda。
Amazon Lambda将图片发送到GroundingDINO进行目标检测。如果图片中没有任何目标物品,则返回前端;如果有多个目标物品,则将检测到的目标物品的坐标返回给前端,以允许用户进行物品选择;如果只有一个目标物品,或者用户已经选择了目标物品,则根据GroundingDINO返回的长方形框剪切出目标图片,进入下一步。
将剪切出目标图片通过Amazon Lambda。
Amazon Lambda调用embedding模型获取向量。
通过向量查询Amazon OpenSearch获取top5的产品代码。
通过产品代码查询Amazon Aurora MySQL,得到产品详细数据并返回前端。
技术难点以及解决思路
图像预处理
技术难点:
存在不适合训练的图片:某些图片可能只显示产品的部分视角(如鞋底),这对于训练模型来说可能不太合适。
图片质量不一致,角度不同:由于图像来源的多样性,图像质量和拍摄角度可能存在差异,这会影响模型的训练效果。
解决方案:
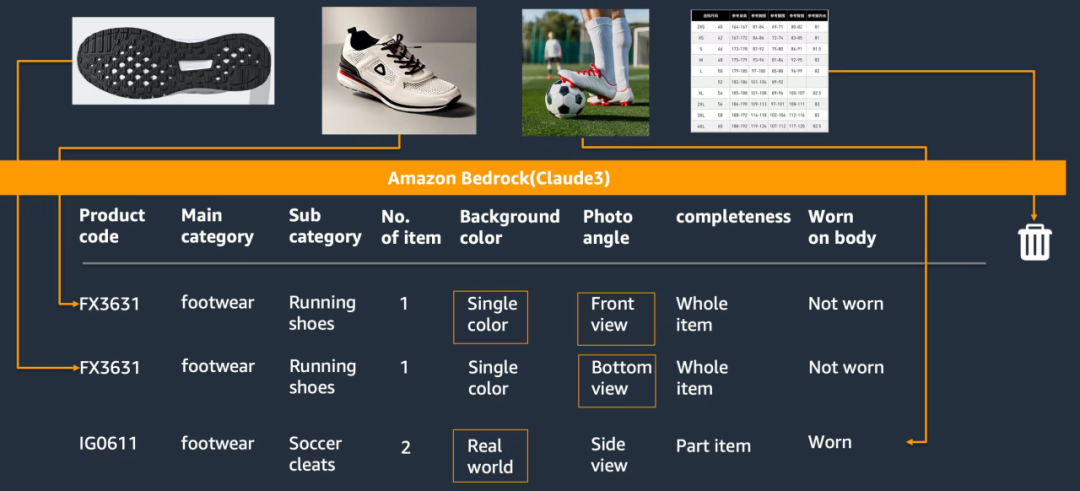
参照下图,我们利用大语言模型最新的多模态功能,输入图片,让模型对图片的进行图片标注。
在我们的场景中,我们设计了如下标签体系。“是否出现模特”,“模特人数”,“是否真实世界的场景”,“是否穿在模特身上”,“拍摄角度”,“局部还是整体”等,通过这些图片,我们可以过滤掉比如鞋底这类对训练和搜索都没有帮助的图片。
同时,我们也利用这些标签进行训练集和测试集的划分。真实世界场景的图片都被划分到测试集。
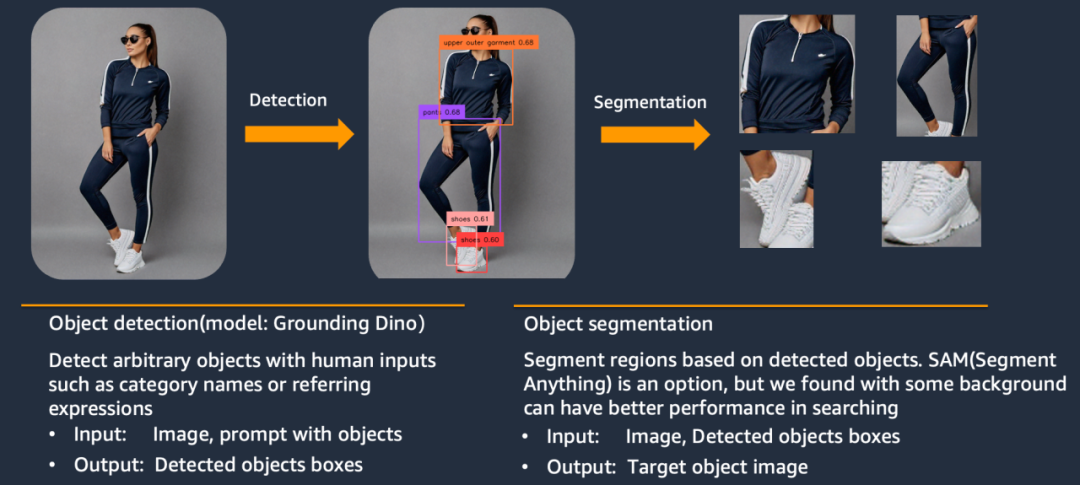
目标检测和分割
技术难点:
用户使用的搜索图片无法做预先的限定,会出现不包含任何产品和包含多个产品的情况。如何确定图像中的目标是否为公司销售的产品类别:需要一种方法来识别图像中的目标是否属于公司销售的产品范围。
如果检测到多个产品,需要用户选择:当图像中包含多个产品时,需要提供一种机制让用户选择感兴趣的产品。
解决方案:
使用Grounding DINO对鞋子、帽子、裤子等进行目标检测。然后直接使用代码剪切出对应的长方形块(这里保留了长方形块里面的所有元素,包括背景。最后没有使用SAM切割出不规则的物品,原因是我们发现,仅对目标图片做方框的截取即可,使用SAM做像素级分割,反而降低了模型的效果 )。
首先我们先构建模型压缩包,并上传至Amazon S3存储桶中,如下图所示:
import boto3
import sagemaker
from sagemaker import serializers, deserializers
from sagemaker.pytorch.model import PyTorchModel, PyTorchPredictor
role = sagemaker.get_execution_role() # execution role for the endpoint
sess = sagemaker.session.Session() # sagemaker session for interacting with different AWS APIs
bucket = sess.default_bucket() # bucket to house artifacts
region = sess._region_name # region name of the current SageMaker Studio environment
account_id = sess.account_id() # account_id of the current SageMaker Studio environment
s3_model_prefix = "east-ai-models/grounded-sam"左右滑动查看完整示意
!touch dummy
!rm -f model.tar.gz
!tar czvf model.tar.gz dummy
s3_model_artifact = sess.upload_data("model.tar.gz", bucket, s3_model_prefix)
print(f"S3 Code or Model tar uploaded to --- > {s3_model_artifact}")
!rm -f dummy左右滑动查看完整示意
接下来我们准备创建模型所需要的代码,以下代码均在本地“code”路径下:
endpoint_name ="grounded-sam"
#%%
framework_version = '2.3.0'
py_version = 'py311'
instance_type = "ml.g4dn.xlarge"
endpoint_name ="grounded-sam"
model = PyTorchModel(
model_data = s3_model_artifact,
entry_point = 'inference.py',
source_dir = "./code/",
role = role,
framework_version = framework_version,
py_version = py_version,
)
print("模型部署过程大约需要 7~8 分钟,请等待" + "."*20)
model.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
)
print("模型部署已完成,可以继续执行后续步骤" + "."*20)左右滑动查看完整示意
准备自定义推理脚本clip_inference.py。我们在model_fn中进行模型加载,在predict_fn定义推理逻辑,核心代码如下:
import os
import io
from PIL import Image
import numpy as np
import torch
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict
from groundingdino.util.inference import predict
import groundingdino.datasets.transforms as T
from huggingface_hub import hf_hub_download
import json
import boto3
import uuid
import math
def get_detection_boxes(image_source: Image, model: dict, prompt: str = "clothes . pants . hats . shoes") -> (
list, list, list):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
box_treshold = 0.3
text_treshold = 0.25
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image_transformed, _ = transform(image_source, None)
try:
boxes, logits, phrases = predict(
model=model['dino'],
image=image_transformed,
caption=prompt,
box_threshold=box_treshold,
text_threshold=text_treshold,
device='cuda'
)
except Exception as e:
print(e)
return
boxes_list = boxes.numpy().tolist()
logits_list = logits.numpy().tolist()
return boxes_list, logits_list, phrases
def load_model_hf(repo_id, filename, ckpt_config_filename, device='cpu'):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
args = SLConfig.fromfile(cache_config_file)
model = build_model(args)
args.device = device
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
checkpoint = torch.load(cache_file, map_location=device)
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
model.cuda()
_ = model.eval()
return model
def model_fn(model_dir):
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "groundingdino_swint_ogc.pth"
ckpt_config_filename = "GroundingDINO_SwinT_OGC.cfg.py"
model = load_model_hf(ckpt_repo_id, ckpt_filenmae, ckpt_config_filename)
model_dic = {'dino': model, 'sam': ''}
return model_dic
def save_file_to_s3(mask_image, file_extension, output_mask_image_dir: str):
# 图片存储到s3
......
return mask_image_output
def crop_images_from_boxes(image_source: Image, boxes: list, scale_factor: float = 1.0, target_size: int = 400) -> list:
cropped_images = []
width, height = image_source.size
for box in boxes:
cx, cy, w, h = [coord * scale_factor for coord in box]
# 计算边界框的左上角和右下角坐标
x1 = max(0, math.floor((cx - w / 2) * width))
y1 = max(0, math.floor((cy - h / 2) * height))
x2 = min(width, math.ceil((cx + w / 2) * width))
y2 = min(height, math.ceil((cy + h / 2) * height))
# 如果边界框在图像范围内,则裁剪图像
if x2 > x1 and y2 > y1:
cropped_image = image_source.crop((x1, y1, x2, y2))
# 调整裁剪后图像的大小
cropped_width, cropped_height = cropped_image.size
# 等比例调整到目标尺寸
scale = min(target_size / cropped_width, target_size / cropped_height)
new_width = int(cropped_width * scale)
new_height = int(cropped_height * scale)
cropped_image = cropped_image.resize((new_width, new_height), resample=Image.BICUBIC)
cropped_images.append(cropped_image)
return cropped_images
def predict_fn(input_data, model):
print("=================Dino detect start=================")
try:
file_extension = os.path.splitext(input_data['input_image'])[1][1:].lower()
dir_lst = input_data['input_image'].split('/')
s3_client = boto3.client('s3')
s3_response_object = s3_client.get_object(Bucket=dir_lst[2], Key='/'.join(dir_lst[3:]))
img_bytes = s3_response_object['Body'].read()
image_source = Image.open(io.BytesIO(img_bytes)).convert("RGB")
if 'boxes' not in input_data:
prompt = input_data['prompt']
boxes, logits, phrases = get_detection_boxes(image_source, model, prompt)
if len(boxes) == 0:
return {"error_message": "The image does not contain any object needed"}
elif len(boxes) > 1:
return {"boxes": boxes, "file_type": file_extension, "logits": logits, "phrases": phrases}
boxes = [input_data['boxes']] if 'boxes' in input_data else boxes
cropped_images = crop_images_from_boxes(image_source, boxes)
mask_image_output = save_file_to_s3(cropped_images[0], file_extension, input_data['output_mask_image_dir'])
return {"mask_image_output": mask_image_output}
except Exception as e:
print(e)左右滑动查看完整示意
Embedding 模型
技术难点:
传统的图片Embedding模型在用作向量召回时往往存在如下问题:
缺乏标注的图片:训练模型需要大量已标注的图像数据,但获取这些标注成本过高,可能存在困难。
模型需要高精度以进行细粒度比较:为了准确匹配相似产品,嵌入模型需要具有足够的精度来捕捉细微的差异。
模型输出的Embedding的鲁棒性不足:会受到背景,衣物形变,拍摄角度,光线等因素的较大影响。
需要私有部署选项以保证安全和隐私:出于安全和隐私考虑,可能需要在本地私有环境中部署模型。
模型应该可定制和可扩展:为了满足不同的需求,模型应该具有一定的定制和扩展能力。
解决方案:
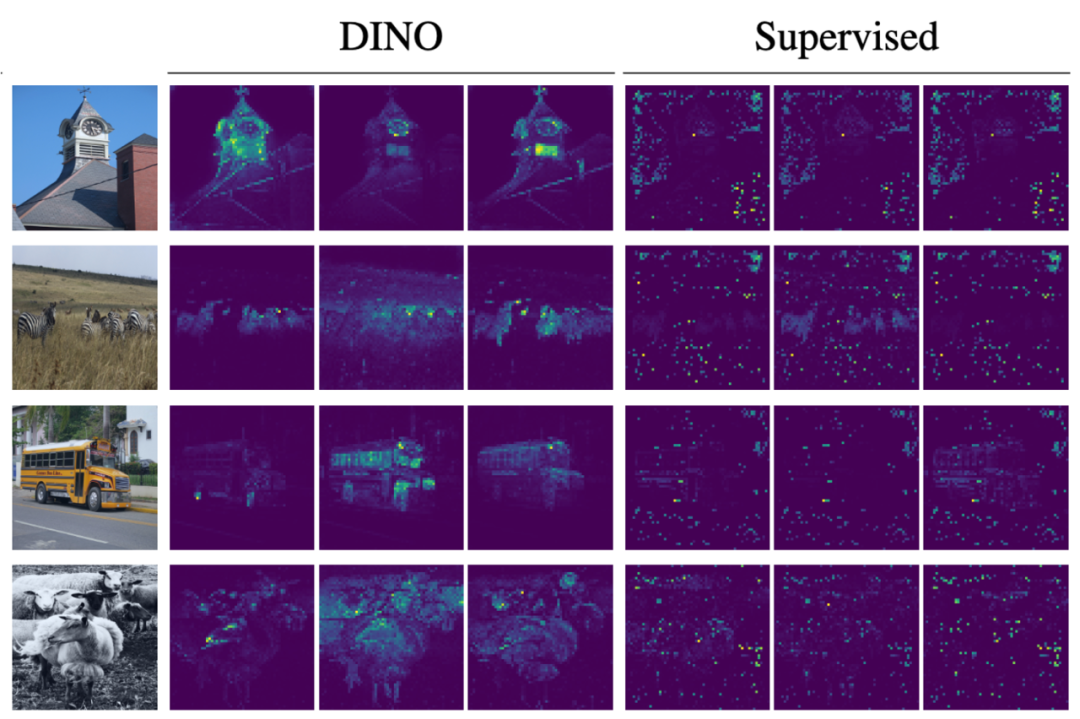
先用基于DINO+VIT的模型在私有产品图片数据上进行预训练,这个阶段无需进行标注,DINO就可以自行关注到图片中的主体,而不容易受到背景的干扰。
在第二阶段,我们采用对比学习或者分类的方式对模型进行Finetune从而进一步提升召回能力。下图可视化了DINO模型的注意力层,展示其相对于传统模型的优点,我们可以看到DINO这一列中展示的模型注意力可以剥离背景的干扰因素,而传统的有监督算法的注意力没有准确的捕捉到图片中的主体。
在具体的算法开发过程中,我们评估了DINO和DINO V2,Triplet Loss和Cross Entropy Loss,也对比了VIT和CNN,在大量实验的基础上,得到的最终的结论如下:
Triplet loss,目前看下来经济性远不如cross entropy loss,同样的训练轮次完全不收敛(个位数的mAP),原因是cross entropy loss训练过程中一次梯度更新优化的是整个样本分布,而triplet loss一次梯度更新仅仅是优化采样到的正负样本,训练效率完全不是一个等级,但是triplet loss这种直接优化特征的模式其实更加适配向量匹配任务,可能需要更大的batch size或者更细致的超参数调节,加上更完备的难负样本挖掘。
DINOv2(即加入了MAE损失的DINO)在此场景下毫无意外地比DINO差,甚至large和giant版本的VIT-dinov2都比不过Base的VIT-dino,目前的猜测是由于重建类的损失(MAE损失)并不适配判别场景,此种场景下还是判别损失(Cross Entorpy Loss)更加合适,关注的特征也更加低频,提取到的特征更加适合做判别任务。
DINOv1是目前最适合做向量搜索的预训练算法,这种预训练方法甚至可以一定程度上弥补模型参数量的差距。
有条件的话可以用DINO的训练框架预训练更大的VIT模型。
将训练好的DINO模型部署在Amazon SageMaker上,需要提供推理脚本文件inference.py。其中的主要代码如下:
...
def predict_fn(single_data, model):
"""
Predict a result using a single data
:param single_data: a single numpy array for an image
:type single_data: numpy.array
:param model: the loaded model
:type model:
:return:an object with prediction value
:rtype: object
"""
imsize = 648
transform = pth_transforms.Compose(
[
pth_transforms.Resize((imsize, imsize), interpolation=3),
pth_transforms.ToTensor(),
pth_transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
]
)
image = transform(single_data)
try:
output = model(image[None].cuda())
# First, move the tensor to CPU
cpu_tensor = output.cpu()
# Then convert to NumPy array
numpy_array = cpu_tensor.detach().numpy()
return numpy_array[0]
except Exception as e:
raise e
def input_fn(input_data, request_content_type):
# The request_body is coming 1 by 1
"""An input_fn that loads a pickled tensor"""
if request_content_type == "application/json":
try:
json_request = json.loads(input_data)
file_byte_string = s3_client.get_object(
Bucket=json_request["bucket"], Key=json_request["file_name"]
)["Body"].read()
im = Image.open(io.BytesIO(file_byte_string))
im = im.convert("RGB")
return im
except Exception as e:
raise e
elif request_content_type == "application/x-image":
im = Image.open(BytesIO(input_data))
im = im.convert("RGB")
return im
else:
# Handle other content-types here or raise an Exception
# if the content type is not supported.
raise Exception("Unsupported content type")
def model_fn(model_dir):
pretrained_weights = os.path.join(model_dir, "checkpoint.pth")
print(os.path.abspath(os.path.join(model_dir, "config.json")))
# Open the file and load its contents
config_path = os.path.join(model_dir, "config.json")
with open(config_path, "r") as config_file:
model_config = json.load(config_file)
print("loading model info: %s", model_config)
# load pretrained weights
if os.path.isfile(pretrained_weights):
model = vits.__dict__[model_config["arch"]](
patch_size=model_config["patch_size"],
drop_path_rate=model_config["drop_path_rate"], # stochastic depth
)
state_dict = torch.load(pretrained_weights, map_location="cpu")
state_dict = {k.replace("backbone.", ""): v for k, v in state_dict.items()}
msg = model.load_state_dict(state_dict, strict=False)
print(
"Pretrained weights found at {} and loaded with msg: {}".format(
pretrained_weights, msg
)
)
else:
print(
"Since no pretrained weights have been provided, we load pretrained DINO weights on Google Landmark v2."
)
model = torch.hub.load(
"facebookresearch/xcit:main", "vit_small", pretrained=False
)
model.load_state_dict(
torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/dino/dino_vitsmall16_googlelandmark_pretrain/dino_vitsmall16_googlelandmark_pretrain.pth"
)
)
model = model.cuda()
model.eval()
return model
...
Python左右滑动查看完整示意
向量搜索
技术难点:
用于产品召回,而非图像召回:最终目标是根据图像找到相应的产品,而不是简单地找到相似图像。
需要支持从向量存储中高效检索向量:向量数据库需要能够支撑百万级的快速向量检索,且搜索结果应该能够提供产品的唯一标识符(如产品代码)。
解决方案:
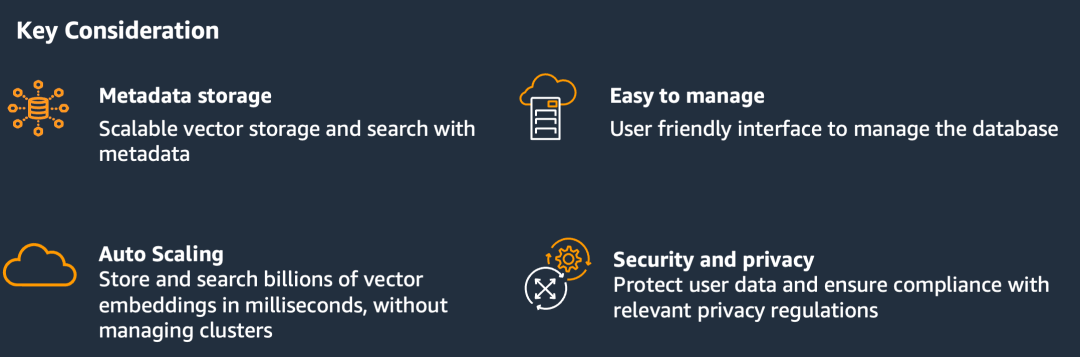
使用Amazon OpenSearch同时存储图片的向量数据和产品的代码,这样在做向量相似度对比后,可以同时获取产品代码。同时使用Faiss-HNSW算法作为检索算法,同时相似度的计算我们使用了和模型Finetune阶段相匹配的Cosine函数。核心的考虑点如下图:
Amazon OpenSearch Service提供了多种算法选择,通过下图的对比,我们最终选择了FAISS-HNSW作为向量索引算法。
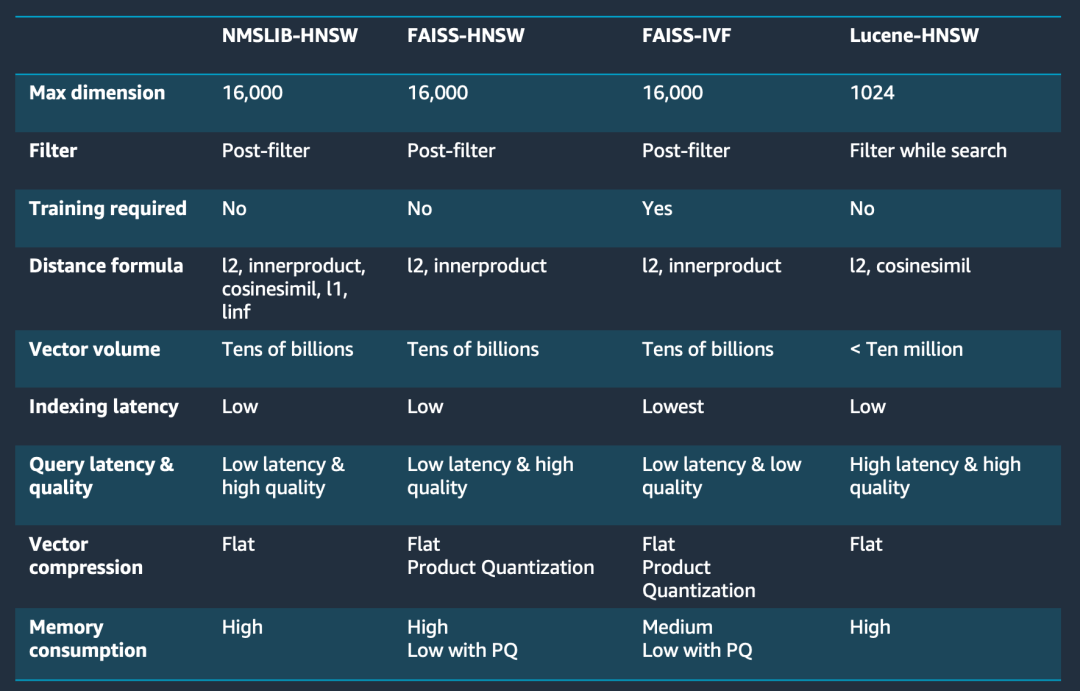
总的来说,这里涉及图像处理、目标检测、图像分割、embedding和向量搜索等多个方面,需要解决数据、模型精度、部署环境和搜索结果等多个挑战。通过合理的数据预处理、模型选择和系统设计,可以构建一个高效的基于图像的产品检索系统。
实验测试结果
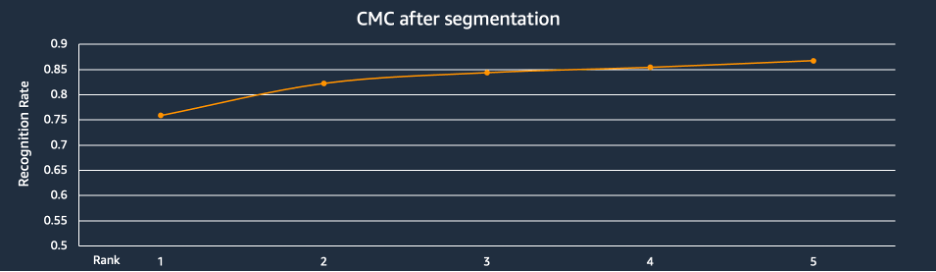
上图是CMC(Cumulative Match Characteristic)的测试结果,横坐标rank n代表检索出的前n个产品,纵坐标是检索出的前n个产品里面有目标产品的概率。我们的测试产品库中包含6000个左右的品类,用户图片都是真实世界场景的图片,可以看到有75%的图片在rank 1的位置召回,86%的正确产品图片都在前5的位置被召回。这个检索的精度,满足了客户要求的前5个产品里面有目标产品的概率达到85%的要求。并且经过业务人员的确认,搜索可以自动忽略背景的影响,对于细节的区别和辨认也已经接近或者达到人类水平。
结论
本文通过使用服装鞋类商品进行模型训练,同时通过GroundingDINO进行目标物品检测和剪切的方式对图片进行搜索。这种方式满足企业级,特别是垂直行业的高精度搜索,有助于更好地提升用户的搜索体验。
该方案也可以拓展到其他的垂直行业使用,如电商、游戏、短视频,医疗、制造业等。
如果您有任何相关的问题或需求,都欢迎随时联系我们进一步交流。
本篇作者

江炳坤
亚马逊云科技资深解决方案架构师。拥有十余年系统架构设计经验。目前专注于将亚马逊云科技云平台技术应用于实际解决方案,为客户实现技术创新和成功的技术落地。

姬军翔
亚马逊云科技资深解决方案架构师,在快速原型团队负责创新场景的端到端设计与实现。

吕浩然
亚马逊云科技应用科学家,长期从事计算机视觉,自然语言处理等领域的研究和开发工作。支持数据实验室项目,在时序预测,目标检测,OCR,自然语言生成等方向有丰富的算法开发以及落地实践经验。

尹振宇
亚马逊云科技解决方案架构师,负责基于亚马逊云科技云平台的解决方案咨询和设计,尤其在无服务器领域和微服务领域有着丰富的实践经验。

洪丹
亚马逊云科技原型解决方案架构师,负责机器学习应用场景的快速构建,为客户提供高效、精准的解决方案,以满足他们独特的业务需求和挑战。

华成
亚马逊云科技客户解决方案经理,目前在亚马逊云科技主要支持泛零售行业的客户。通过运用云相关解决方案等帮助客户在迁移到亚马逊云和云上运维期间实现自身的业务价值,帮助客户成功。





星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9443
9443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









