







大语言模型(LLM)的兴起改变了自然语言处理(NLP),在文本分类、内容创作和问答等任务中展现出了卓越的能力。然而GPU资源的紧缺,为生产环境中部署这些庞大的模型带来了挑战。这些问题阻碍了LLM的广泛采用,特别是对于计算能力有限的企业。借助亚马逊云科技的自研芯片,可以有效的缓解资源不足的问题。此外vLLM作为主流的推理框架,也将Amazon EC2 Inf2实例添加到了功能清单,我们将借助vLLM强大的推理能力,在Amazon EC2 Inf2上搭建推理服务。
关于Amazon EC2 Inf2
Amazon EC2 Inf2实例由最多12个Inferentia2芯片提供支持,为部署大语言模型和其他生成式AI工作负载提供了经济高效、高性能的解决方案。
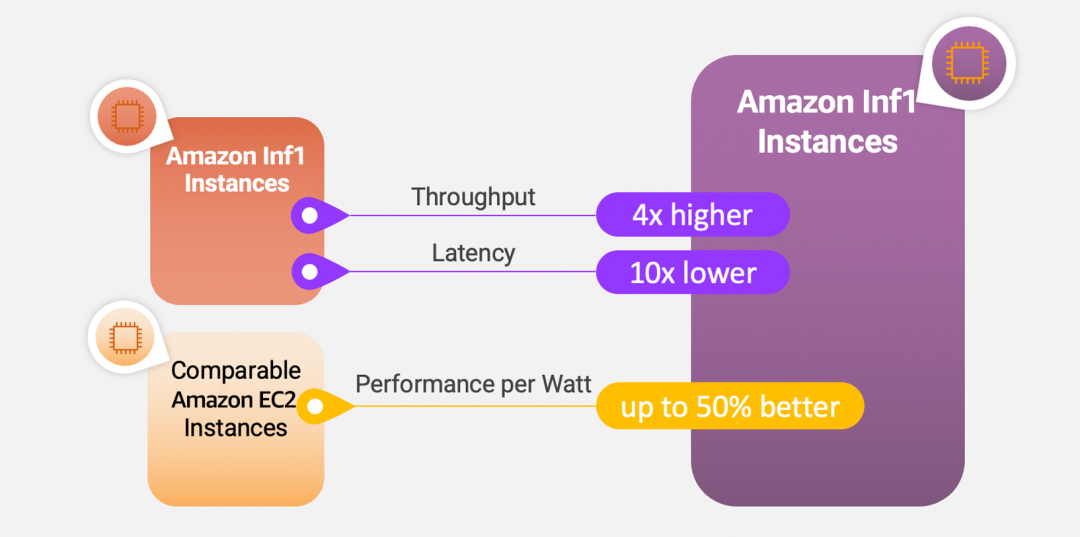
借助高达2.3PetaFLOPS的计算能力和384GB的总加速器内存,以及9.8TB/秒的总内存带宽,Amazon EC2 Inf2实例比其他可比的Amazon EC2实例的性价比高出40%。为了实现加速器之间的快速通信,Amazon EC2 Inf2实例支持192GB/秒的NeuronLink,可实现高性能的集群通信操作。这允许跨多个Inferentia2设备分片大型模型(例如通过张量并行),从而优化延迟和吞吐量。
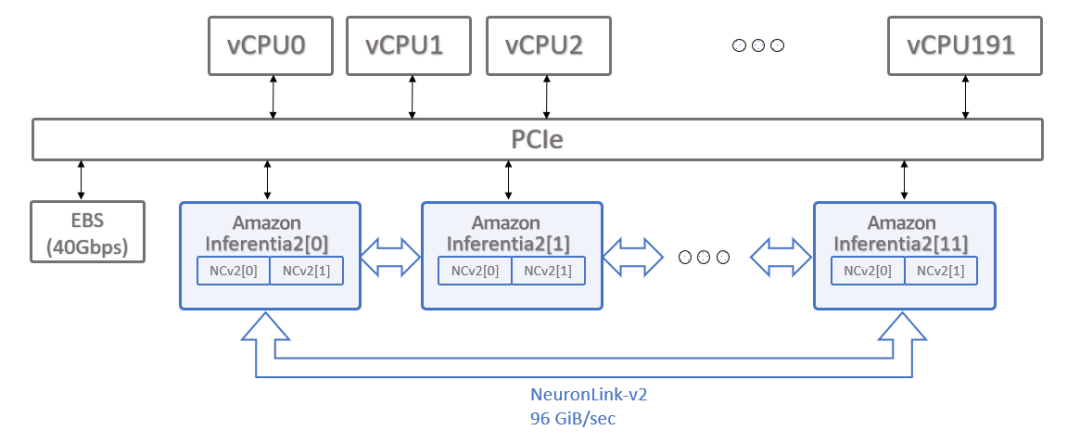
目前,Amazon EC2 Inf2提供四种实例类型,其中最大的实例规格(Inf2.48xlarge)能够部署高达1,750亿参数的模型。
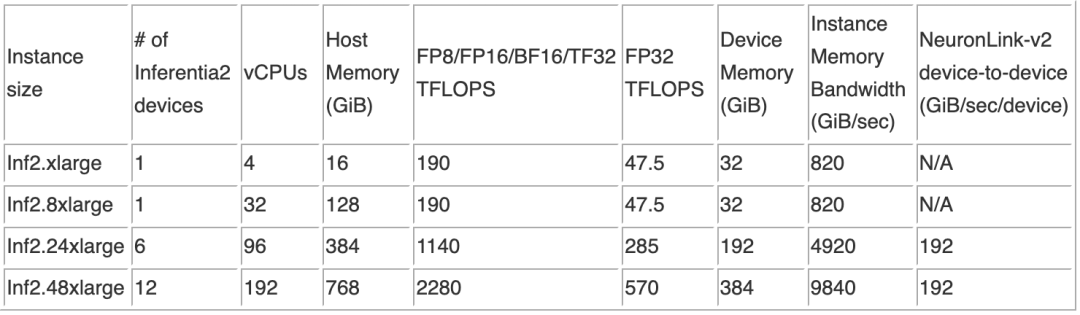
https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/arch/neuron-hardware/inf2-arch.html
Amazon Neuron
Amazon Neuron是一个用于在Amazon Inferentia和Amazon Trainium基础实例上运行深度学习工作负载的开发工具包(SDK)。Amazon Neuron原生集成了TensorFlow、PyTorch和Apache MXNet等主流深度学习框架。提供了一套完整的工具链,包括深度学习编译器、运行时和相关工具。并为Hugging Face等热门模型库中的模型实现开箱即用的性能优化。通过使用Amazon Neuron,可以在亚马逊云科技平台上快速构建、训练和部署高性能的深度学习模型。借助Amazon Neuron SDK,可以在Amazon EC2 Inf2实例上部署模型。
vLLM
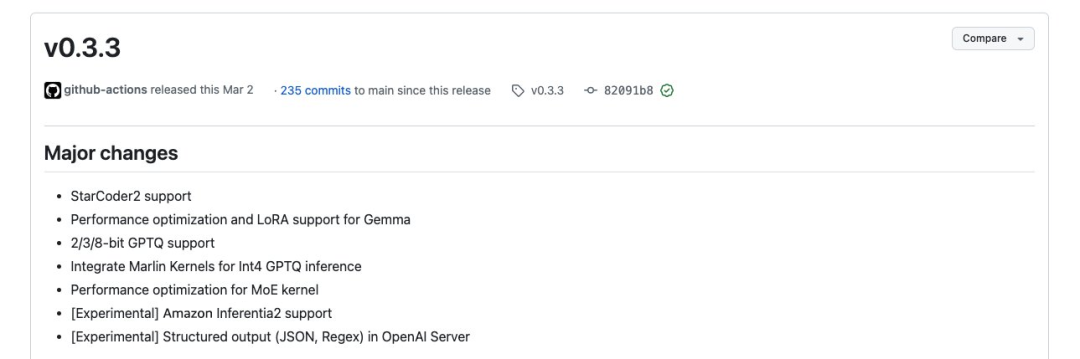
vLLM是一个由加州大学伯克利分校的研究人员开发的开源库,旨在加速大语言模型(LLM)的推理和服务。vLLM引入了创新的算法和优化,显著提高了LLM推理和服务的速度和效率。Hugging Face Transformers(HF)和Hugging Face Text Generation Inference(TGI)的基准测试显示,vLLM实现了高达24倍于HF和3.5倍于TGI的吞吐量。vLLM从版本0.3.3开始,vLLM加了对Amazon Inferentia2的实验性支持。
使用vLLM在Amazon EC2 Inf2
进行Mistral模型的推理
环境说明
将使用以下步骤在Amazon EC2 Inf2上安装vLLM v0.4.8和Neuron Compiler [2.14.213.0],在此基础上运行Mistral 7B v0.3的大模型。
配置Inf2实例
启动Amazon EC2 Inf2实例,选择DeepLearning AMI Neuron (Ubuntu 22.04) 20240708。
在这里将使用预装了Neuron和Ubuntu 22.04的DeepLearning AMI作为运行环境。Neuron Deep Learning AMI是一个预构建的Amazon镜像,预装了经过优化的机器学习框架和库,用于在Amazon Neuron实例上运行深度学习工作负载。极大地简化了环境设置。启动实例后将激活Neuron环境。
source /opt/aws_neuronx_venv_pytorch_2_1/bin/activate左右滑动查看完整示意
您可以通过运行以下命令检查Neuronx的相关版本:
neuronx-cc --version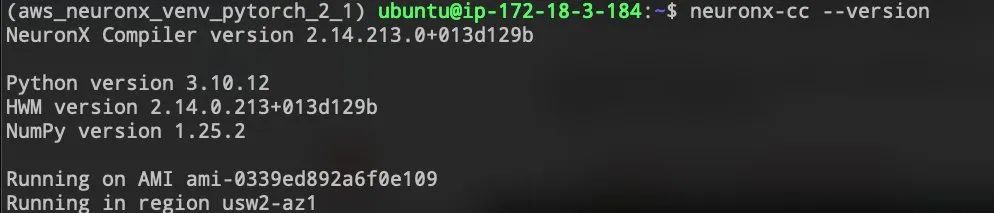
安装vLLM
下载vLLM并安装所需的依赖项:
git clone -b v0.4.3 https://github.com/vllm-project/vllm.git
pip install -U -r requirements-neuron.txt
pip install .左右滑动查看完整示意
安装完成后,可以看到对应的vLLM版本和Neuron版本。

调整vLLM配置
打开文件~/vllm/vllm/engine/arg_utils.py,找到第264行:
parser.add_argument('--block-size',
type=int,
default=EngineArgs.block_size,
choices=[8, 16, 32,128],
help='Token block size for contiguous chunks of '
'tokens.')左右滑动查看完整示意
将block_size设置为等于max_model_len,这里设置为128。
启动模型vLLM通过FastAPI进行推理
vLLM的模型服务可以通过Python脚本在本机或Docker环境中启动。本文将展示使用Python命令的方式加载Mistral-7B模型,并同步启动内置FastAPI的vLLM服务。
python3 -m vllm.entrypoints.api_server \
--model mistralai/Mistral-7B-v0.3 \
--max-num-seqs 8 \
--max-model-len 128 \
--block-size 128 \
--device neuron \
--tensor-parallel-size 2左右滑动查看完整示意
启动后会监听8000端口,接收相关的推理请求。
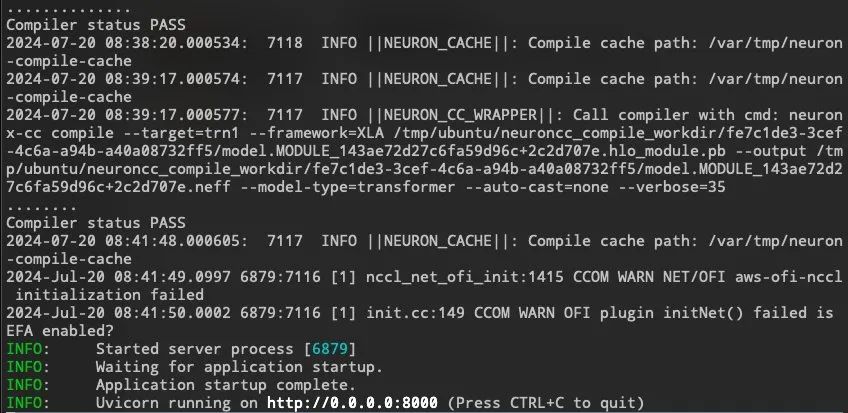
调用推理接口
将通过HTTP POST请求的方式调用vLLM进行推理。
curl -X POST -H "Content-Type: application/json" \
localhost:8000/generate \
-d '{"prompt": "[INST] Hello, my name is [/INST]"}'左右滑动查看完整示意
返回:
{"text":["[INST] Hello my name is[/INST] Dillon and I'm here to share with you what I've learned"]}左右滑动查看完整示意
至此已将Mistral 7B v0.3模型通过vLLM框架部署在Amazon EC2 Inf2实例上,并提供API服务。
总结
Amazon Inferentia2加速芯片为大语言模型的高效部署带来了新的可能性。本文以开源的 Mistral 7B大语言模型为例,详细介绍了如何借助vLLM在Amazon Inferentia2上进行大模型的推理。使用Amazon Inferentia2将极大地解决GPU资源紧缺问题,为大模型推理提供更加多样化的选择。
参考链接
https://github.com/vllm-project/vllm
https://github.com/liangfu/vllm
https://docs.vllm.ai/en/latest/index.html
https://mistral.ai/technology/#deployment
https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html
本篇作者

曹镏
亚马逊云科技解决方案架构师,专注于为企业级客户提供信息化以及生成式AI方案的咨询与设计,在人工智能和机器学习领域具有解决实际问题能力以及落地大模型训练项目的经验。

陈良甫
亚马逊云科技人工智能技术专家,目前专注于通过人工智能加速器提高大语言模型(LLM)推理吞吐量。




星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9458
9458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









