







企业业务数据呈碎片化分散,数据访问和整合变得复杂,不仅导致企业运营成本增加,而且难以灵活处理数据,最终影响决策。
亚马逊云科技推出Amazon SageMaker Lakehouse,能够整合Amazon S3数据湖与Amazon Redshift数据仓库中的数据,帮助用户基于单一数据即可构建强大的分析和人工智能与机器学习应用程序。
借助Amazon SageMaker Lakehouse,企业能够灵活使用与Apache Iceberg兼容的引擎和工具,就地访问和查询数据,以及通过集中定义并执行细粒度的权限,简化数据共享和协作。
不仅如此,Amazon SageMaker Lakehouse支持无缝访问现有数据湖和数据仓库中的数据,还可利用来自运营数据库和应用程序的zero-ETL功能,提升效率。
开始使用
本演示使用了一个包含多个亚马逊云科技数据源的预配置环境。进入Amazon SageMaker Unified Studio(预览版)控制台,它为您的所有数据和人工智能提供了集成开发体验。使用Amazon SageMaker Unified Studio(预览版),您可以通过Amazon SageMaker Lakehouse无缝访问和查询各种来源的数据,同时使用熟悉的亚马逊云科技服务开展分析和人工智能与机器学习任务。
在此您可以创建和管理作为共享工作区的项目,这些项目支持团队成员进行协作、处理数据并共同开发人工智能模型。创建项目会自动设置Amazon Glue Data Catalog数据库,为Amazon Redshift Managed Storage(RMS)数据建立目录,并提供必要的权限。您可以通过创建新项目或继续使用现有项目开始工作。
如果选择创建一个新项目,点击“创建项目”。
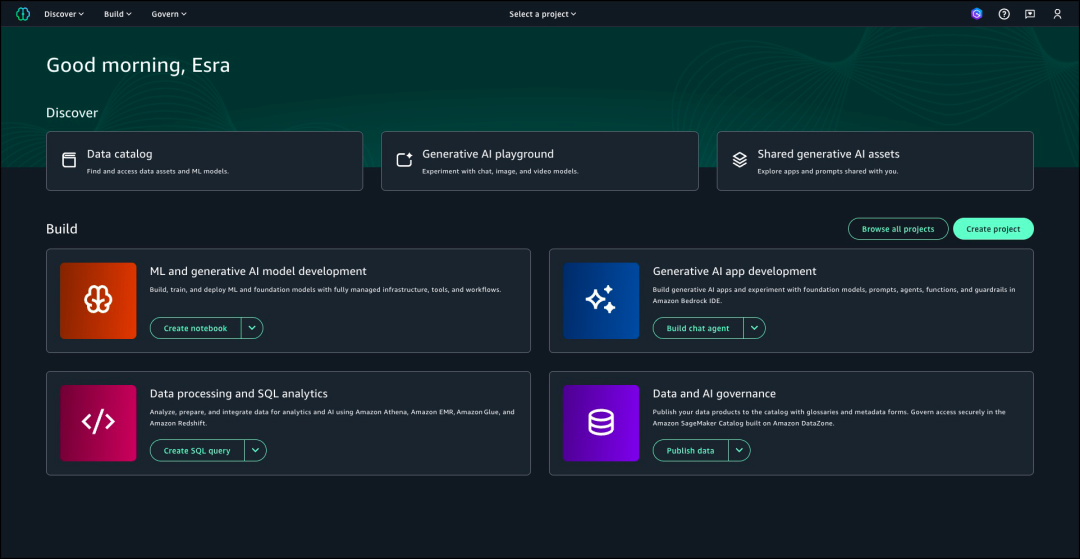
有两种项目配置选项来构建湖仓一体架构并进行交互。
第一种是数据分析和人工智能——机器学习模型开发,在此您可以分析数据,并构建由Amazon EMR、Amazon Glue、Amazon Athena、Amazon SageMaker AI和Amazon SageMaker Lakehouse支持的机器学习和生成式AI模型。
第二种是SQL分析,您可以使用SQL在Amazon SageMaker Lakehouse中分析数据。
本文演示SQL分析。
在“项目名称”字段中输入项目名称,并在“项目配置文件”下选择“SQL分析”,再选择“继续”。
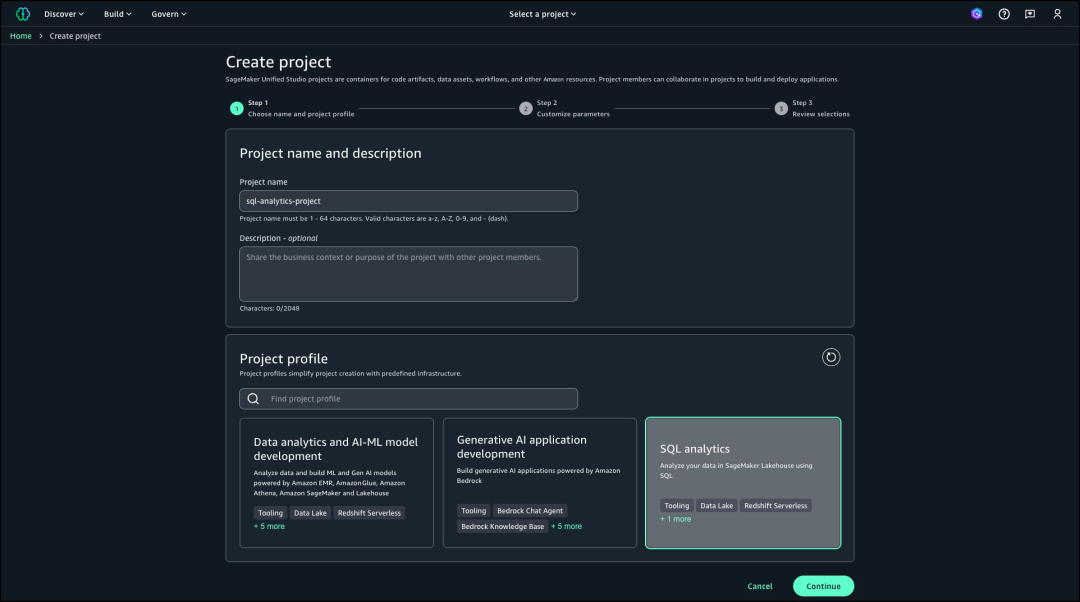
在“工具”一栏输入所有参数的值。本文演示输入了创建湖仓一体数据库的值,随后再输入创建Redshift无服务器资源的值,最后在湖仓一体目录下输入目录名称。
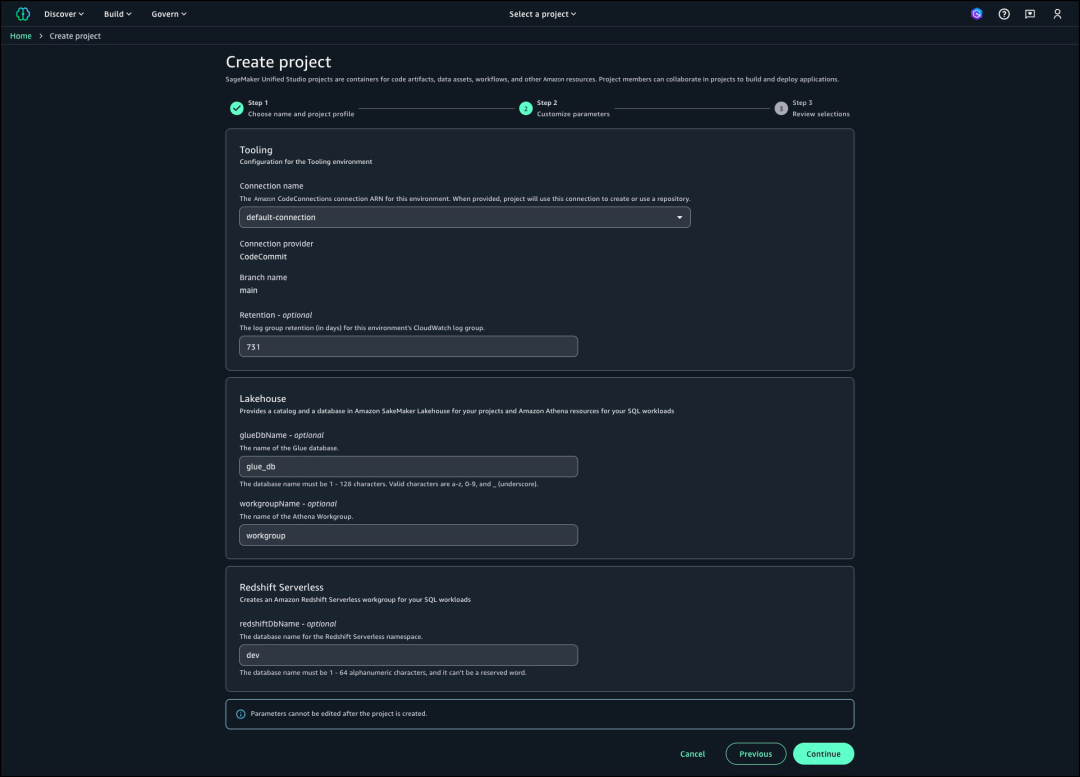
下一步,查看资源并选择创建项目。
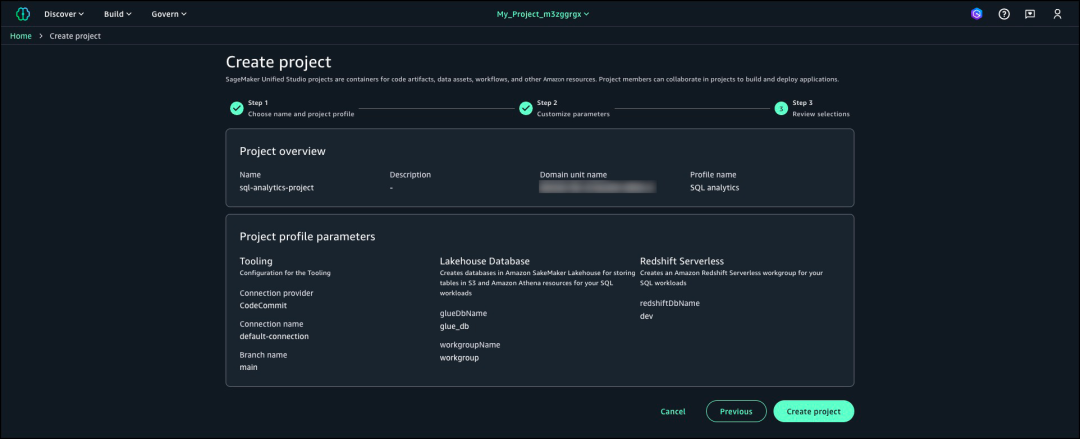
项目创建后查看项目详细信息。
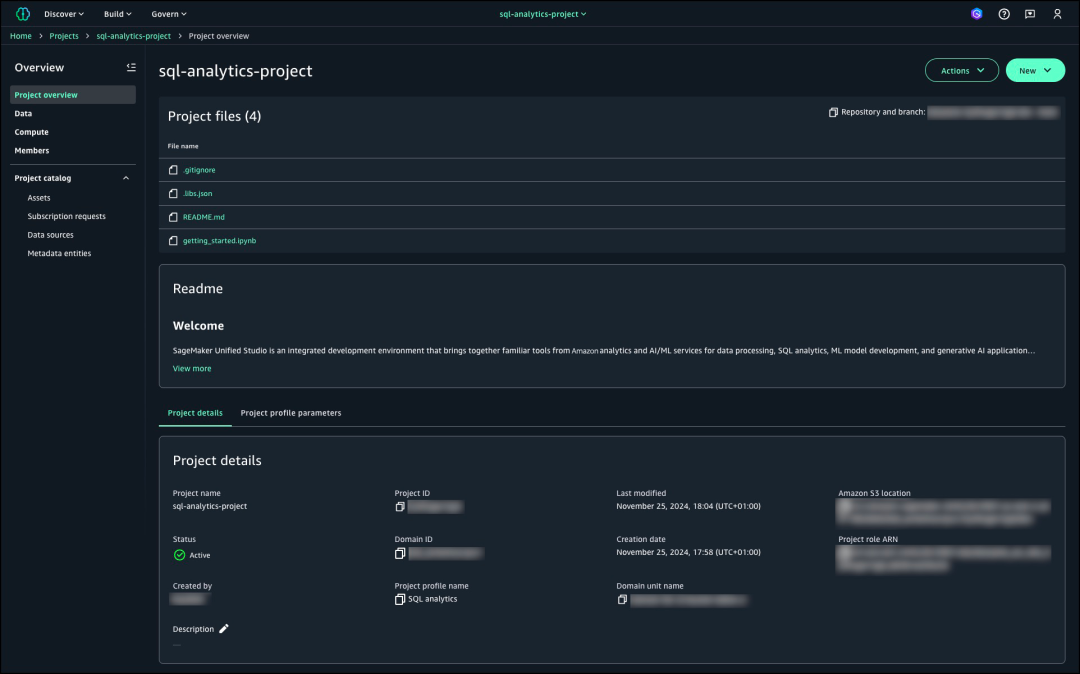
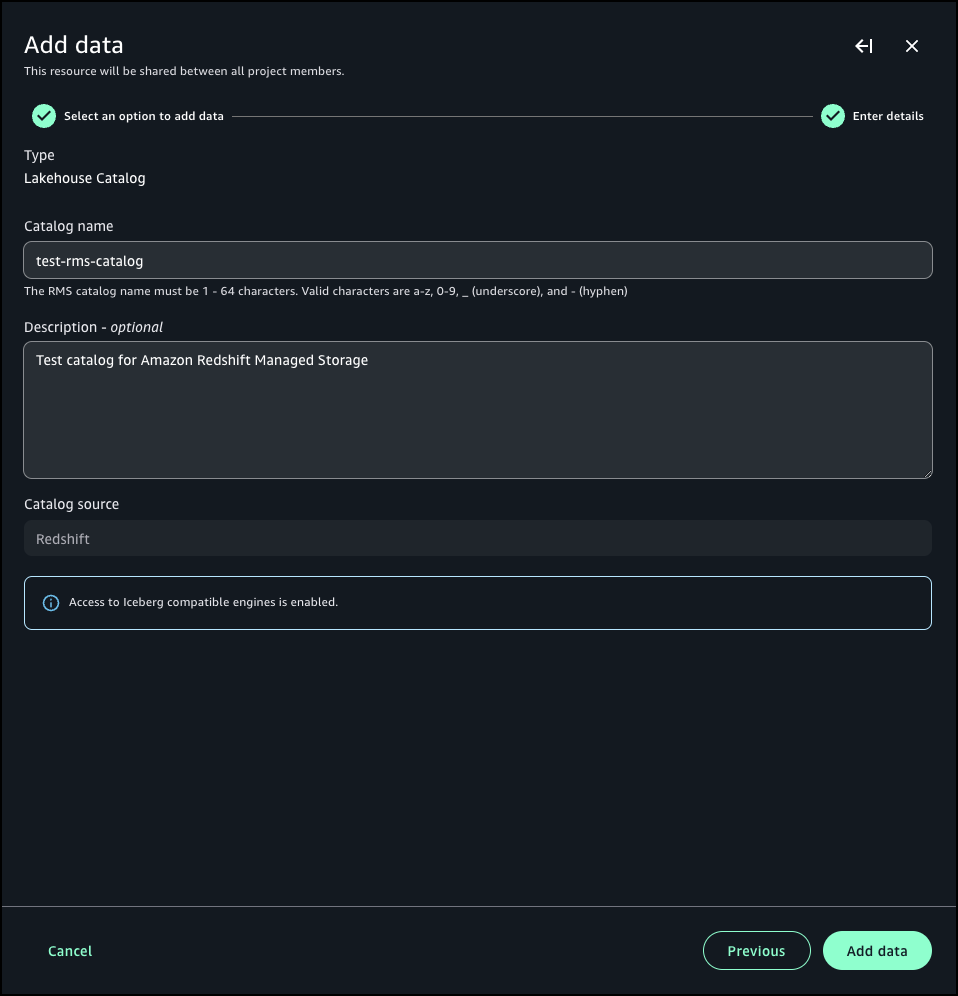
在导航窗格转到“数据”并选择+号以添加数据,随后选择“创建目录”,并选择“添加数据”。
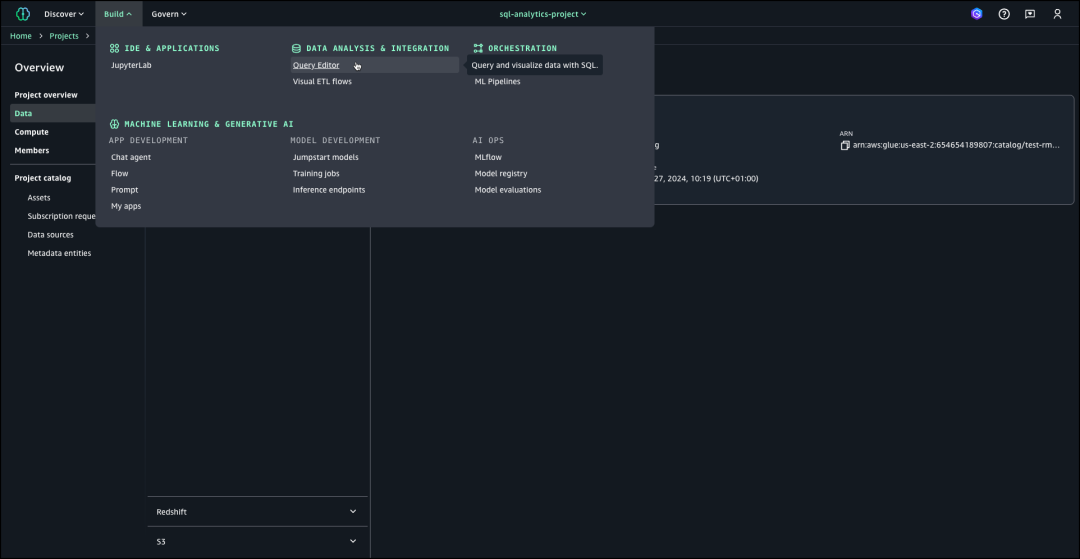
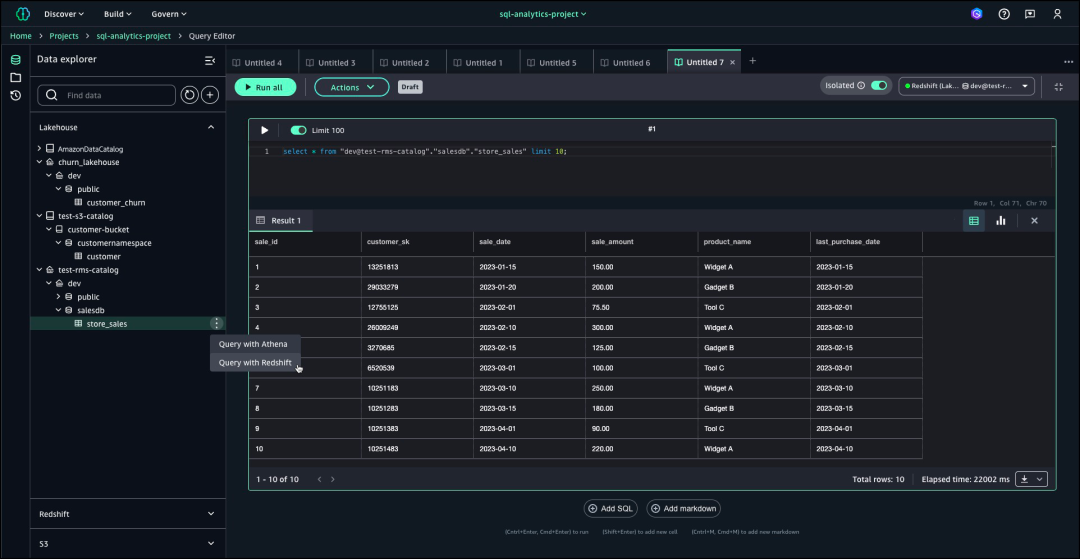
创建RMS目录后,在导航窗格中选择“构建”,然后选择“数据分析与集成”下的“查询编辑器”,以便在RMS目录下创建架构、创建表,然后使用示例销售数据加载表。
在将SQL查询输入到指定单元格后,从右侧下拉菜单中点击“选择数据源”,以连接Amazon Redshift数据仓库的数据库。通过此连接,您可以执行查询并从数据库中检索所需数据。
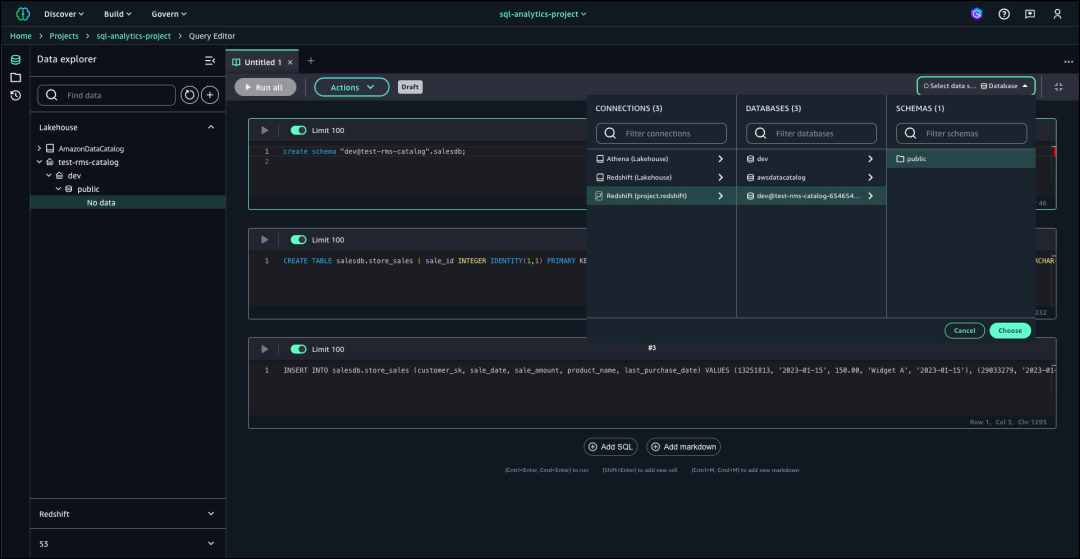
数据库连接成功建立后,选择“运行全部”来执行所有查询,并监控执行进度,直到显示所有结果。
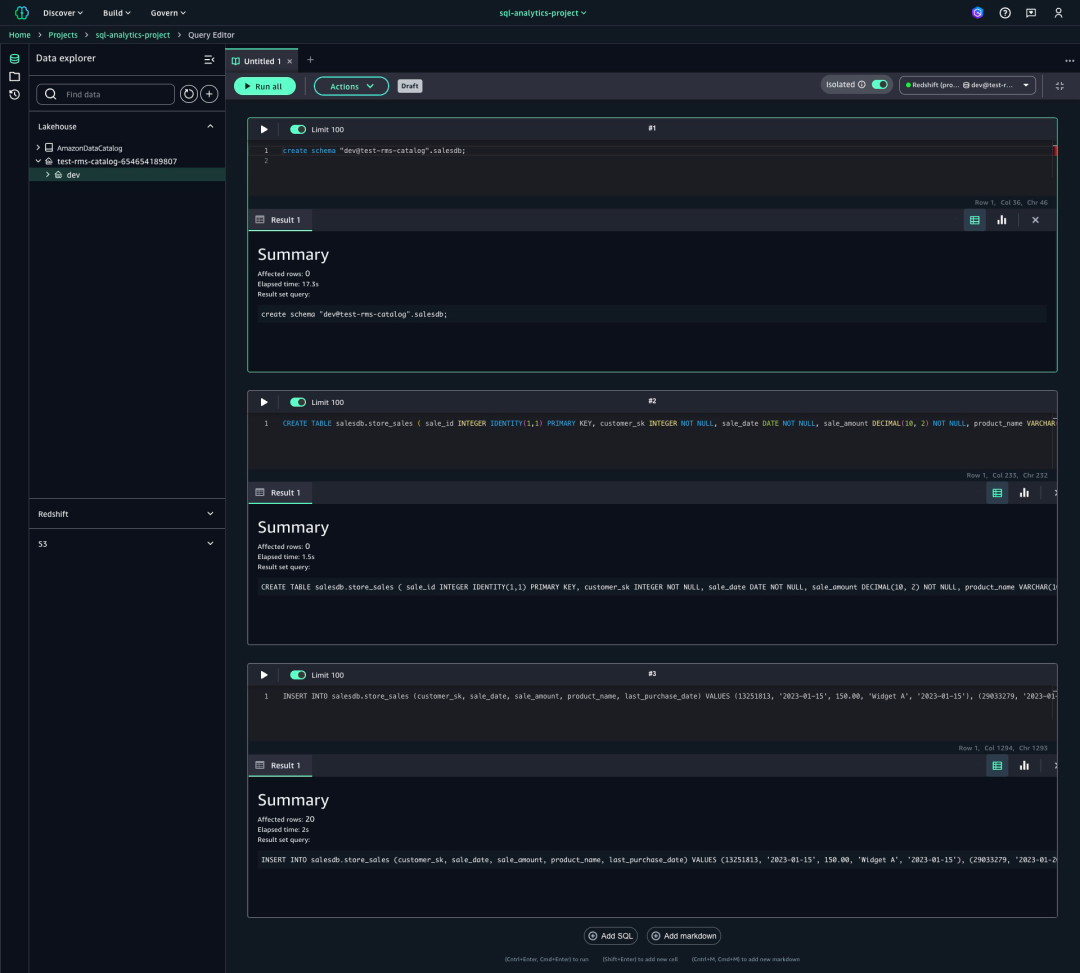
本演示使用了两个额外的预配置目录,这是用于组织湖仓一体对象定义(如架构和表)的容器。
第一个是Amazon S3数据湖目录(test-s3-catalog),用于存储客户记录,其中包含详细的交易和人口信息。
第二个是专门用于存储和管理客户流失数据的湖仓一体目录(churn_lakehouse)。通过这种集成,您可以创建一个能够同时分析客户行为与预测客户流失率的统一环境。
在导航窗格选择“数据”,并在“湖仓一体”部分找到目录,Amazon SageMaker Lakehouse提供多种分析选项,包括使用Amazon Athena查询、使用Amazon Redshift查询和在Jupyter Lab笔记本中打开。
如果您想选择“在Jupyter Lab笔记本中打开”选项,则需要在创建项目时选择“数据分析和人工智能——机器学习模型开发配置文件”。如果选择在Jupyter Lab笔记本中打开,您可以通过配置Iceberg REST目录,使用EMR 7.5.0或Amazon Glue 5.0中的Apache Spark与Amazon SageMaker Lakehouse进行交互,从而能够统一处理您的数据湖和数据仓库中的数据。
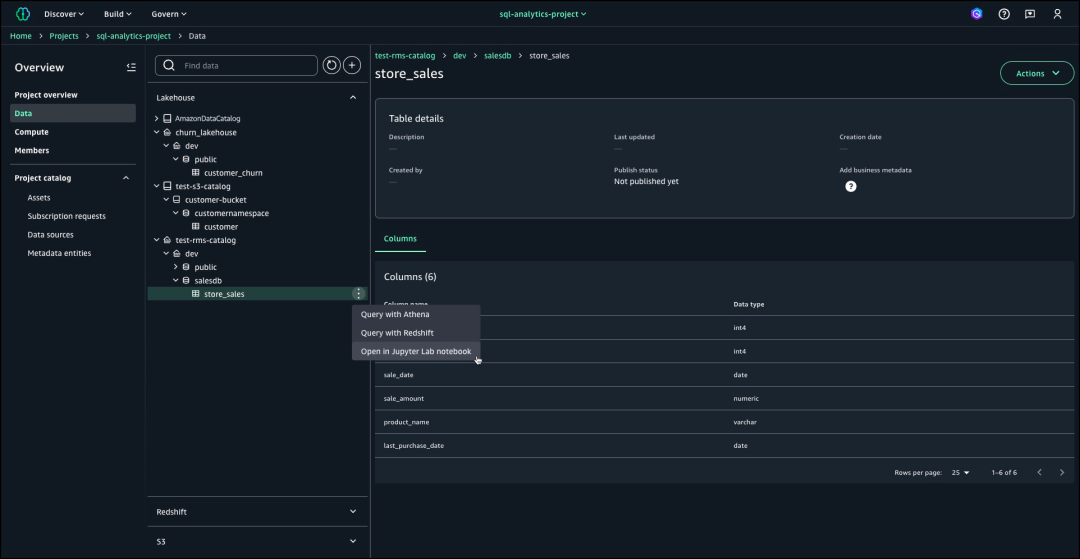
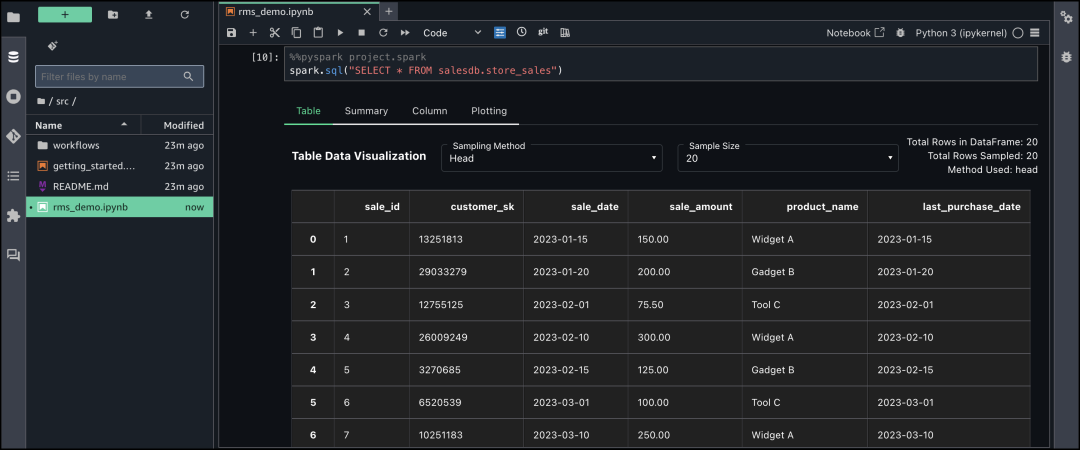
下面是使用Jupyter Lab笔记本进行查询的过程:
接下来选择“使用Athena查询”,通过这个选项,您可以利用Amazon Athena的无服务器查询功能,直接在Amazon SageMaker Lakehouse中分析销售数据。选择“使用Athena查询”后,查询编辑器会自动启动,并提供一个可以在其中编写和执行针对湖仓一体的SQL查询的工作区。这一集成的查询环境为数据探索和分析提供了无缝体验,并配备了语法高亮和自动完成功能,将帮助您提高工作效率。
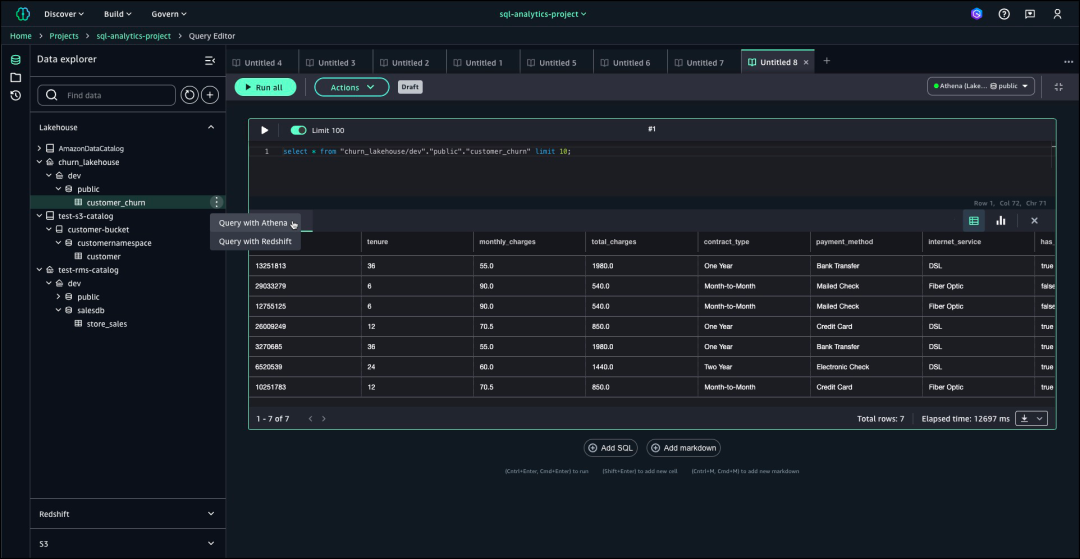
您还可以使用Redshift查询来对湖仓一体运行SQL查询。
Amazon SageMaker Lakehouse为现代数据管理和分析提供了全面的解决方案。通过统一跨多个数据源的数据访问,Amazon SageMaker Lakehouse支持广泛的分析和机器学习引擎,并提供细粒度的访问控制,有助于企业充分利用数据资产。
无论是处理Amazon S3数据湖、Amazon Redshift数据仓库,还是运营数据库和应用程序,Amazon SageMaker Lakehouse都将为企业提供推动创新和数据驱动型决策所需的灵活性和安全性。此外企业还可以使用数百个连接器来集成来自各种数据源的数据,以及使用跨第三方数据源的联合查询功能,就地访问和查询数据。
您可复制下方链接访问Amazon SageMaker Lakehouse文档,了解Amazon SageMaker Lakehouse的详细信息,获取如何简化数据分析和人工智能与机器学习的工作流程。
Amazon SageMaker Lakehouse文档:
https://docs.aws.amazon.com/sagemaker-unified-studio/latest/userguide/lakehouse.html




星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9443
9443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









