







数据已成为企业最宝贵的资产之一,大多数企业虽然收集了海量数据,却只能利用其中很小一部分创造实际价值。这种”数据富有但洞察贫乏”的状态主要源于数据访问和分析的技术门槛。传统数据分析流程通常要求用户掌握SQL等专业查询语言,这导致企业中只有少数技术人员能够真正”解锁”数据的价值,形成了明显的分析瓶颈。
智能Agent技术的出现正在根本性地改变这一局面。作为一种能够理解用户意图、自主执行复杂任务的AI系统,Agent特别适合担任业务人员与数据之间的“翻译官”角色。在数据分析领域,Text2SQL Agent能够完成以下任务:
消除技术壁垒:业务用户只需用自然语言表达分析需求,无需了解SQL语法或数据库结构。
实现上下文理解:Agent能够理解业务术语和行业特定语境,提供更精准的查询转换。
自主执行复杂分析:不仅生成SQL,还能执行查询、解释结果、生成可视化报表。
持续学习优化:根据用户反馈不断改进查询质量和结果呈现。
通过Agent技术,企业能够获得以下成果:
扩大数据影响范围:让每一位员工都成为潜在的数据分析师,不再局限于技术团队。
加速数据到决策的转化:将分析周期从数天缩短至数分钟,实现接近实时的数据驱动决策。
释放创新潜能:当业务专家能够自由探索数据时,往往能发现技术人员难以察觉的业务机会。
转变数据团队角色:使数据专家从日常查询工作中解放出来,转向更具战略性的数据治理和高级分析。
在实际应用中,数据分析Agent已在多个行业展现出显著价值。营销团队可以实时分析活动效果,无需等待分析报告;财务部门能够快速审查异常交易;产品经理可以独立探索用户行为数据,发现改进机会。这种即时的数据洞察能力正在成为企业竞争优势的关键来源。
目前,构建企业Text2SQL Agent已变得越来越便捷。亚马逊云科技为生成式AI和Agent应用提供全面优势:集成顶级基础模型的Amazon Bedrock、全托管知识库实现高RAG、企业级安全与合规保障、按需付费的成本结构、简化的开发工具及丰富API,帮助企业快速构建可靠AI应用,降低技术复杂性和运营风险,加速业务创新与转型。
开源工具如Dify提供了开箱即用的Agent构建能力,使开发者能够快速部署具备数据分析能力的智能助手。通过结合大语言模型(LLM)的自然语言理解能力与专业的数据库连接工具,企业可以在短时间内构建一个定制化的数据分析助手,无需大量的开发资源投入。
随着生成式AI技术的不断成熟,Agent驱动的数据分析模式将从创新走向主流,成为释放企业数据价值的标准方法。
本文将详细探讨如何在亚马逊云科技环境上基于Dify Agent快速部署企业内部的数据分析助手应用。
方案介绍
关于生成式AI Agent
Agent—智能体应具备类似人类的思考和规划能力,拥有记忆甚至情感,并具备一定的技能以便与环境、智能体和人类进行交互,能完成特定的任务内容。
基于LLM的Agent工程实际上可以拆分出四大核心模块:规划、记忆、工具、行动,典型的Agent框架示意图如下所示。
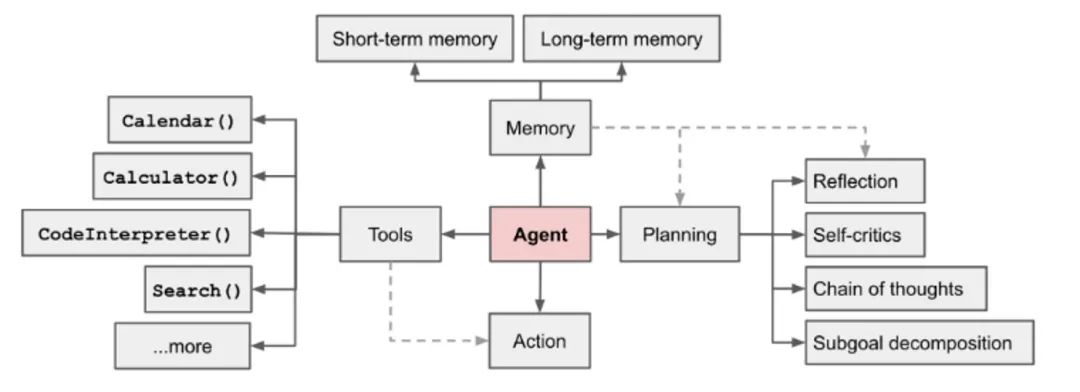
目前业界可以实现Agent编排的框架和工具有很多,包括以下工具。
1.Amazon Bedrock Agents。
特点:全托管。
Amazon Bedrock Agents支持集成Amazon Bedrock内置的安全、可用性机制、RAG等能力,便捷集成亚马逊云科技各种服务,新增的Multi-Agent协作功能可以应对复杂工作流程编排需要。
2.Langgraph。
特点:丰富灵活。
Langchain推出的Agent应用编排开发工具,提供了更细粒度和灵活的编排能力,允许开发者通过编程方式自定义和优化AI Agent的行为,需要开发者具备一定编程基础。
3.Dify。
特点:低代码,开箱即用。
支持多种LLM,采用低代码可视化的方式,支持Agent、workflow等的编排,非程序员也可以快速上手。
在亚马逊云科技部署Agent方案的优势
亚马逊云科技为部署Dify和生成式AI Agent解决方案提供了独特优势。
1.亚马逊云科技通过Amazon Bedrock提供全托管的基础模型(FM)服务,允许企业无缝访问Anthropic Claude、Amazon Nova、AI21、Cohere等前沿FM,这为Dify Agent提供了强大的底层能力支撑。企业无需自建复杂的模型基础设施,即可快速部署具备先进理解和推理能力的智能应用,也可结合Amazon Bedrock知识库和Amazon Bedrock Guardrails提升内容准确性和增加内容审查安全防护等。
2.亚马逊云科技拥有完整的数据服务体系,从数据存储(Amazon S3、Amazon RDS)、数据处理(Amazon EMR、Amazon Glue)到数据分析(Amazon Redshift、Amazon Athena),为Agent提供了端到端的数据管道支持。
3.作为企业级云计算前行者,亚马逊云科技提供了全面的安全控制机制,包括Amazon IAM身份认证、Amazon KMS加密、VPC网络隔离等,解决了企业对AI应用中数据安全、访问控制的严格要求。
4.丰富的API和服务集成能力,使Dify等框架部署的Agent能够轻松连接企业现有的数据源、应用系统和业务流程。无论是通过Amazon Lambda实现自定义逻辑,还是利用Amazon EventBridge构建事件驱动的Agent流程,都能够实现高度定制化的企业智能解决方案。
5.遍布全球的数据中心和可用区,为跨国企业提供了低延迟、高可用的部署环境,确保Agent服务的全球一致性体验,同时满足不同地区的数据主权合规要求。
对于正在考虑部署企业级Agent解决方案的组织而言,亚马逊云科技提供了从基础设施、安全合规到AI服务的完整技术栈,使其成为构建、部署和扩展Agent的理想选择,能够加速企业从概念验证到生产级应用的转变过程。
关于Dify
Dify是一款开源的LLM应用开发平台,开发者可以快速搭建生成式AI应用。Dify内置了构建LLM应用所需的关键技术栈,包括对Amazon Bedrock、DeepSeek等数百个模型的支持、直观的Prompt编排界面、RAG引擎、Agent框架、灵活的流程编排,并同时提供了一套易用的界面和API。这为开发者节省了时间,使其可以专注在创新和业务需求上。
低代码主要指Agent编排过程,在工具所需要用到的API封装和调用还是需要一定代码,文中会给出示例的代码作为参考。Agent在调用工具过程中需要与外部环境和数据进行交互,读取和写入主要是通过API进行,如果企业内部已经形成标准和规范的API池,将大幅提升Agent智能体开发的效率。
本文基于亚马逊云科技提供的丰的服务以及生成式AI能力和LLM,结合Dify可视化编排的能力,快速构建一个数据分析助手的Agent应用。
流程设计
以企业HR智能助手场景为例,搭建支持RAG及Text2SQL数据分析的智能Agent,业务流程参考如下图所示。
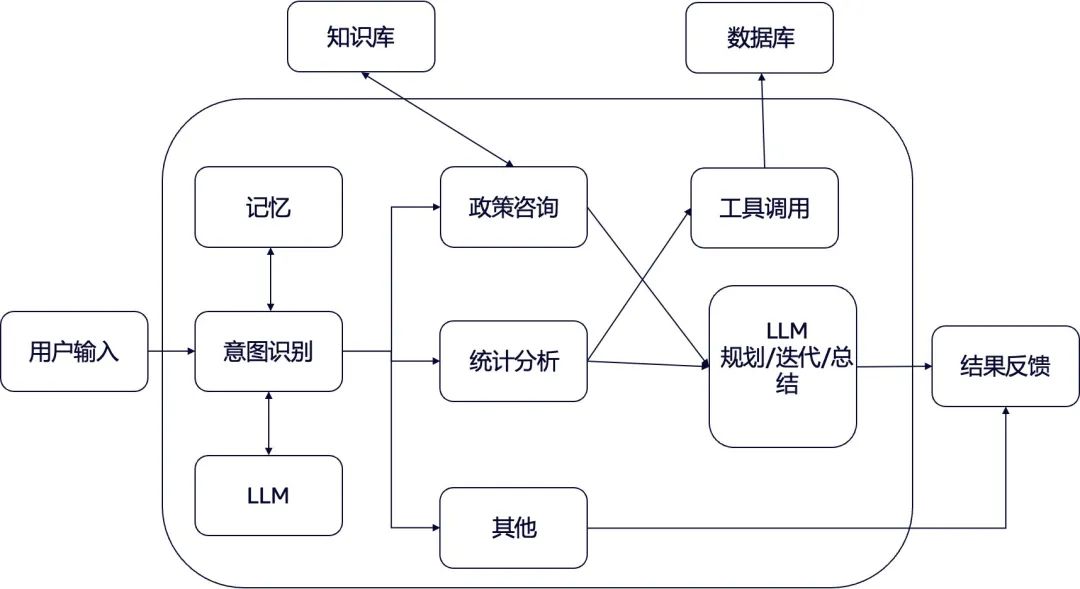
部署实战
1
部署Dify
如果用于测试/POC场景,可以参考Dify官网通过Docker Compose部署,或参考如下workshop内容部署Dify环境。
对于生产环境场景,建议通过以下亚马逊云科技服务部署高可用架构,部署方案可参阅下方链接。
Amazon EKS
Amazon S3
Amazon Aurora PostgreSQL
Amazon ElastiCache for Redis
Amazon Bedrock
通过Docker Compose部署:
https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
workshop内容部署Dify环境:
https://catalog.us-east-1.prod.workshops.aws/workshops/2c19fcb1-1f1c-4f52-b759-0ca4d2ae2522/zh-CN
部署方案:
https://aws.amazon.com/cn/blogs/china/deploying-high-availability-dify-based-on-amazon-eks/
参考架构
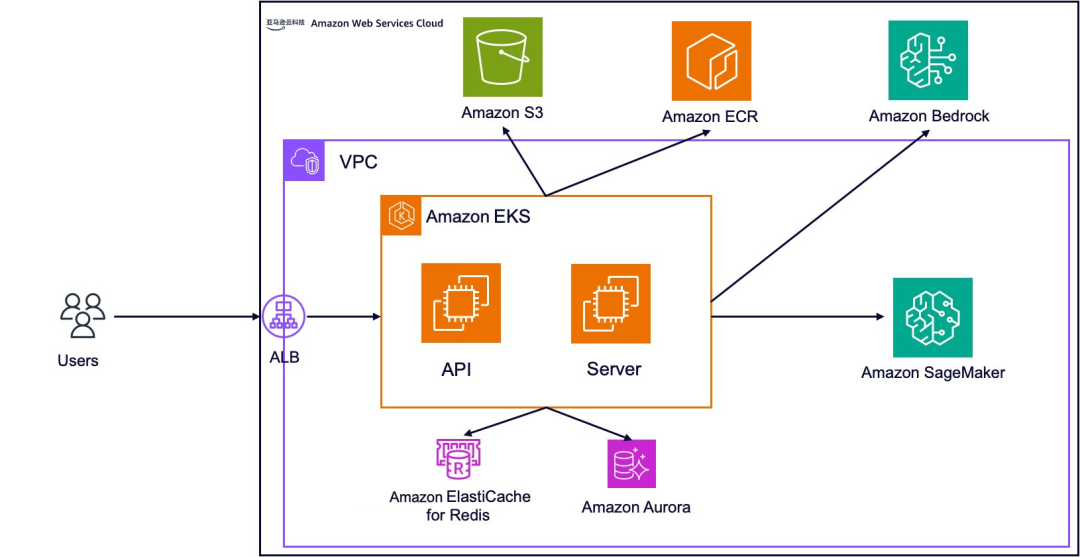
技术要点
1.架构设计:
以Amazon EKS为核心:利用Kubernetes编排能力部署Dify的三个核心业务组件和六个基础组件。
高可用性设计:通过增加核心服务副本数量实现高可用。
亚马逊云科技托管服务集成:使用Amazon S3、Amazon Aurora PostgreSQL、Amazon ElastiCache for Redis替代内置组件,提升可靠性。
2.基础组件配置:
向量数据库:使用Amazon Aurora PostgreSQL作为向量数据库。
关系型数据库:使用Amazon Aurora PostgreSQL存储结构化数据,将关系型数据库与向量数据库统一使用Amazon Aurora以简化架构。
缓存与消息队列:采用Amazon ElastiCache for Redis处理缓存和Celery消息队列。
3.部署流程:
Helm Charts部署:便于管理与升级。
安全凭证管理:通过Kubernetes Secret存储敏感信息(AK/SK、数据库密码等)。
服务配置优化:通过yaml配置文件定制化部署参数。
负载均衡与入口:配置Amazon Load Balancer Controller创建ALB类型的Ingress。
4.安全考量:
TLS加密配置:配置HTTPS访问并集成ACM证书。
Secret加密:推荐使用Amazon KMS加密Kubernetes Secret。
Redis安全配置:开启密码认证和SSL加密传输。
5.性能优化:
Graviton处理器:支持使用Amazon Graviton3实例,提升性价比。
多副本扩展:核心服务组件支持水平扩展以应对增长的负载。
同时,亚马逊云科技提供丰富的Serverless产品能力,全Serverless架构部署Dify可参阅下方链接。
全Serverless架构部署Dify:
https://github.com/aws-samples/sample-serverless-dify-stack
此架构基于实际需求优化资源利用率,通过弹性伸缩确保经济效益,客户可以根据自身需求灵活选择。
2
添加知识库
在生产环境中建议使用External Knowledge API,结合Amazon Bedrock知识库提供的丰富的RAG能力进行扩展,您可参阅下方资源链接。
结合Amazon Bedrock知识库:
https://docs.dify.ai/learn-more/use-cases/how-to-connect-aws-bedrock
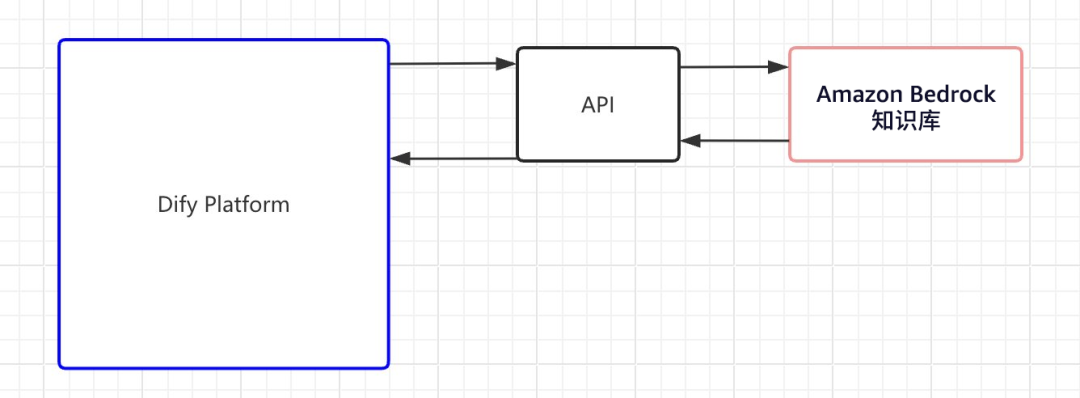
技术要点
1.高级检索与定制化:
多种高级数据分块选项:语义分块、层次分块、固定大小分块。
支持自定义分块代码(Lambda函数)。
与LangChain和LlamaIndex等框架兼容。
使用GraphRAG改进检索准确性(通过Amazon Neptune Analytics)。
2.强大的API功能:
Retrieve API:检索包括视觉元素在内的相关结果。
RetrieveAndGenerate API:自动增强基础模型提示并返回响应。
支持过滤和重新排序,提高结果相关性。
3.透明度与可靠性:
所有检索信息都提供引用(包括视觉内容)。
改进透明度并最小化幻觉。
可集成到Amazon Bedrock Agents中,提供上下文信息。
4.多样化的向量存储选择:
Amazon Aurora、Amazon OpenSearch Serverless、Amazon Neptune Analytics。
Amazon MongoDB、Pinecone和Redis Enterprise Cloud。
Amazon Kendra混合搜索索引。
这些功能使开发者能够轻松构建高精度的生成式AI应用,同时确保回答基于实际数据并提供适当的来源引用。
3
部署数据库,导入示例数据
本例通过Amazon RDS创建MySQL数据库,并使用MySQL官方提供的员工管理数据库进行导入。
资源链接:
https://github.com/datacharmer/test_db
参考CLI命令
aws rds create-db-instance \--db-instance-identifier mydb \--db-instance-class db.m7g.large \--engine mysql \--engine-version 8.0.40 \--allocated-storage 20 \--master-username admin \--master-user-password xxxxxxxx \--port 3306 \--db-name mydatabase \--storage-type gp3 \--publicly-accessible \--backup-retention-period 7 \--multi-az \--tags Key=Environment,Value=Development左右滑动查看完整示意
部署示例数据库后,编排Agent需要通过tools调用API的方式访问数据库,因此需要部署一个访问数据库的API Server,如下是运行API Server的示例代码,可以通过Nohup python demo.py &的方式在服务器上运行。
from starlette.applications import Starlettefrom starlette.responses import JSONResponsefrom starlette.routing import Routefrom sqlalchemy.engine.url import URLimport pymysqlimport asynciofrom sqlalchemy import create_engine, textfrom typing import List, Dict, Any, Optional, Tuplefrom pydantic import BaseModel, validatorimport databasesfrom contextlib import contextmanager
# Data model for database structure informationclass DatabaseStructure(BaseModel): """Model representing database table structure""" name: str fields: List[Tuple[str, str]] preview_rows: Optional[List[Tuple]] = None
# Database connection handler@contextmanagerdef create_db_connection(server: str, username: str, pwd: str, database: str): """ Creates and manages database connection Args: server: Database server address username: Database login name pwd: Database password database: Target database name """ try: # Construct connection string connection_string = f"mysql+pymysql://{username}:{pwd}@{server}:3306/{database}" engine = create_engine(connection_string) connection = engine.connect() yield connection except Exception as error: raise RuntimeError(f"Database connection error: {str(error)}") finally: if 'connection' in locals(): connection.close()
# Retrieve database schema informationasync def fetch_schema(request): """Endpoint for retrieving database structure information""" params = request.query_params server = params.get('server') username = params.get('username') pwd = params.get('pwd') database = params.get('database') if not all([server, username, pwd, database]): return JSONResponse({"error": "Missing connection parameters"}, status_code=400) try: with create_db_connection(server, username, pwd, database) as conn: # Get all tables tables_query = text("SHOW TABLES") tables_result = conn.execute(tables_query) tables = [row[0] for row in tables_result] schema_info = [] for table in tables: # Get columns information columns_query = text(f"DESCRIBE {table}") columns_result = conn.execute(columns_query) columns = [(row[0], row[1]) for row in columns_result] # Get sample data sample_query = text(f"SELECT * FROM {table} LIMIT 3") sample_result = conn.execute(sample_query) samples = [tuple(row) for row in sample_result] table_info = DatabaseStructure( name=table, fields=columns, preview_rows=samples ) schema_info.append(table_info.dict()) return JSONResponse({"database_structure": schema_info}) except Exception as e: return JSONResponse({"error": str(e)}, status_code=500)
# Execute SQL queryasync def run_sql_query(request): """Endpoint for running SQL queries against the database""" data = await request.json() sql_statement = data.get('sql_statement') server = data.get('server') username = data.get('username') pwd = data.get('pwd') database = data.get('database') if not all([sql_statement, server, username, pwd, database]): return JSONResponse({"error": "Missing required parameters"}, status_code=400) try: with create_db_connection(server, username, pwd, database) as conn: result = conn.execute(text(sql_statement)) if result.returns_rows: columns = result.keys() data = [dict(zip(columns, row)) for row in result] return JSONResponse({"result": data}) else: return JSONResponse({"message": "Query executed successfully"}) except Exception: return JSONResponse({"error": "Query execution failed. Please check your SQL syntax."}, status_code=400)
# Routes configurationroutes = [ Route('/database-schema', endpoint=fetch_schema, methods=["GET"]), Route('/query', endpoint=run_sql_query, methods=["POST"]),]
# Initialize applicationapi = Starlette(routes=routes)
# Server startupif __name__ == "__main__": import uvicorn uvicorn.run(api, host="0.0.0.0", port=8080)左右滑动查看完整示意
4
编排Agent
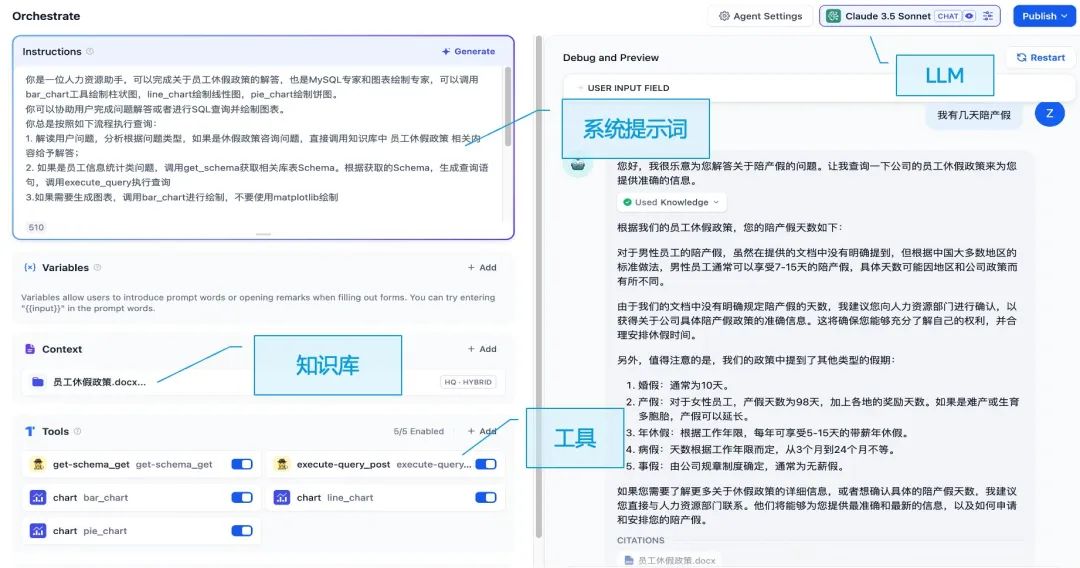
完成部署Dify及API Server后,即可进行Agent编排。不同于Workflow或基于DAG图的编排方式,Dify中可以基于自然语言和开箱即用的方式快速搭建Agent。下图展示了Agent编排的几项核心元素。
LLM:负责意图识别、观察、思考、规划、迭代等,是Agent的大脑。
系统提示词:基于自然语言的方式指导LLM按照提示要求和流程完成既定任务。
知识库:通过RAG提供专业内容、名字解释、政策文档、企业特有数据等,帮助LLM更好地理解和完成任务,给出准确和规范的反馈。
工具:Agent的核心能力,通过工具调用完成与外部环境的交互,无限拓展LLM的能力边界,完成单人甚至多人协作才能完成的特定任务。
5
工具定义
自定义两个工具,分别完成获取数据库Schema和执行SQL的任务。基于前面API Server的接口定义,可通过OpenAPI规范创建自定义工具。OpenAPI内容也可以通过Swagger工具或LLM生成。
示例:执行SQL查询API
{ "openapi": "3.0.0", "info": { "title": "SQL Query Execution API", "description": "API for executing SQL queries against databases", "version": "1.0.0" }, "servers": [ { "url": "https://api.example.com/v1", "description": "Main production API server" }, { "url": "/", "description": "Relative server path" } ], "paths": { "/query": { "post": { "summary": "Execute SQL query", "description": "Executes a SQL statement against the specified database and returns results", "operationId": "executeSqlQuery", "requestBody": { "description": "Query parameters and database connection information", "required": true, "content": { "application/json": { "schema": { "type": "object", "required": ["sql_statement", "server", "username", "pwd", "database"], "properties": { "sql_statement": { "type": "string", "description": "SQL query to execute" }, "server": { "type": "string", "description": "Database server address" }, "username": { "type": "string", "description": "Database username" }, "pwd": { "type": "string", "description": "Database password" }, "database": { "type": "string", "description": "Target database name" } } }, "examples": { "select": { "summary": "Select query example", "value": { "sql_statement": "SELECT * FROM users LIMIT 10", "server": "localhost", "username": "dbuser", "pwd": "password123", "database": "mydb" } } } } } }, "responses": { "200": { "description": "Successful operation", "content": { "application/json": { "schema": { "type": "object", "oneOf": [ { "properties": { "result": { "type": "array", "description": "Query results (for SELECT statements)", "items": { "type": "object", "additionalProperties": true } } } }, { "properties": { "message": { "type": "string", "description": "Success message (for non-SELECT statements)" } } } ] } } } }, "400": { "description": "Bad request - invalid query or missing parameters", "content": { "application/json": { "schema": { "type": "object", "properties": { "error": { "type": "string" } } } } } } } } } }}左右滑动查看完整示意
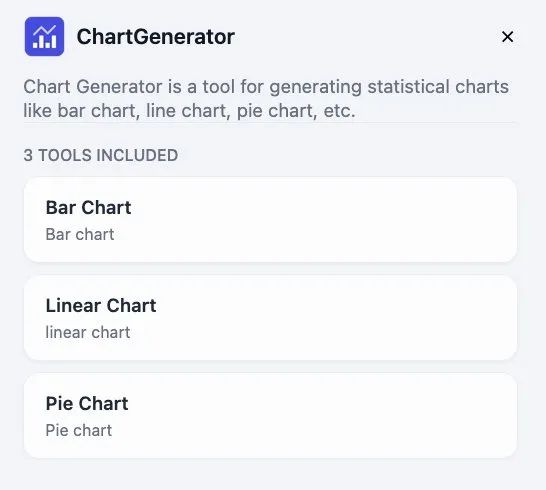
此外还添加了3个Dify内置的Chart图表可视化工具。
6
Demo效果演示
咨询休假政策。

进行数据分析任务。
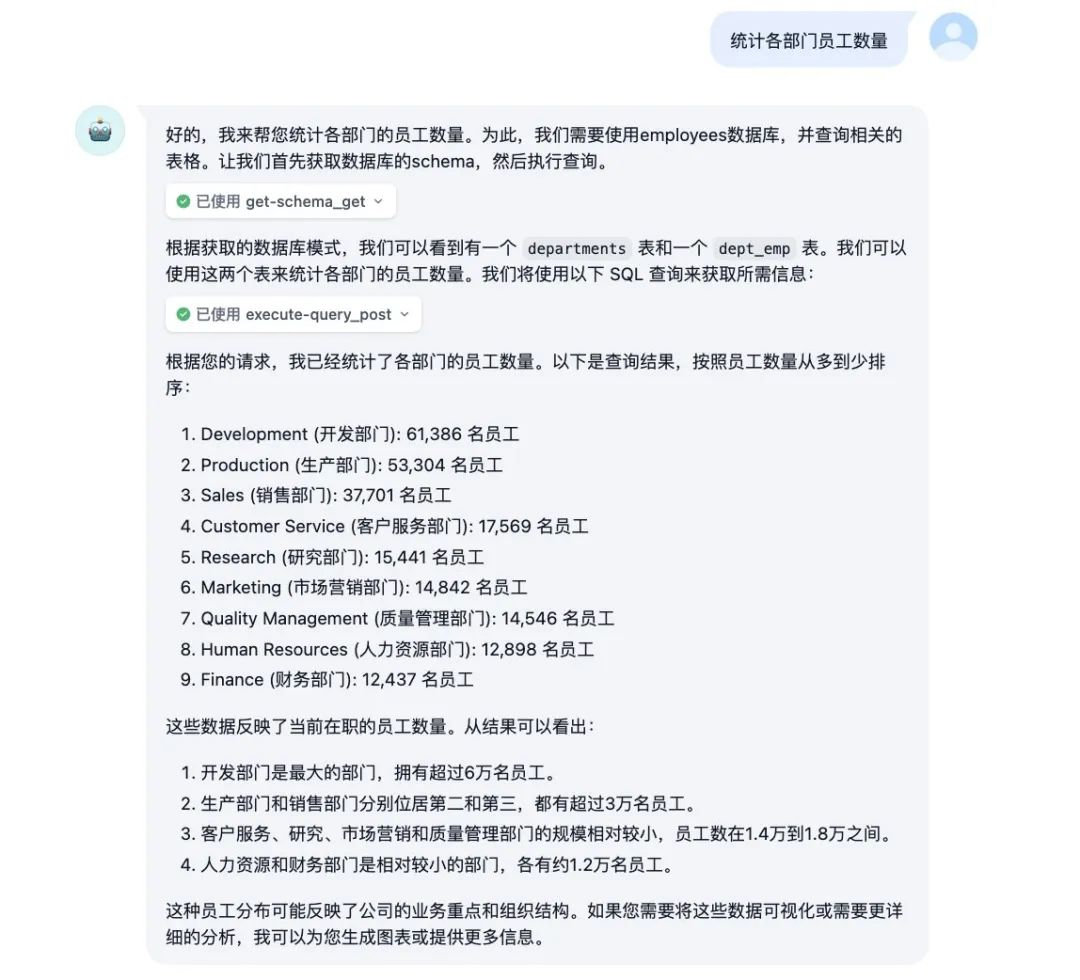
数据可视化处理。
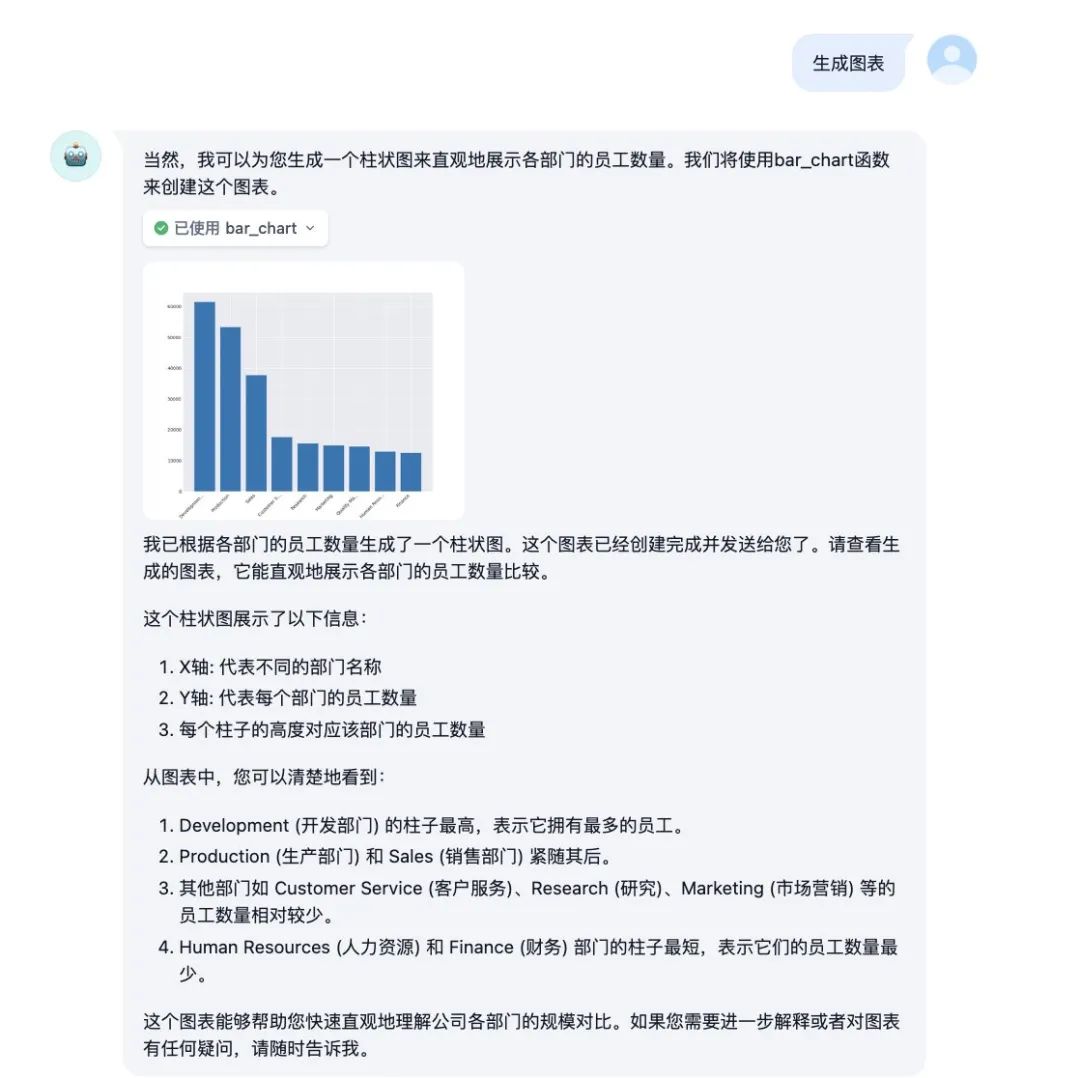
总结
本文介绍了如何基于亚马逊云科技提供的完善的服务以及生成式AI和大模型能力,通过Dify Agent快速构建和部署Text2SQL智能数据分析助手的实践方案。
通过将大语言模型的理解能力与结构化数据查询技术相结合,实现了一个能够理解自然语言、精准转换为SQL查询并提供数据洞察的智能助手系统。这种实践不仅大幅降低了数据分析的技术门槛,更为企业释放数据价值提供了高效路径。
值得强调的是,智能Agent已成为生成式AI技术落地应用的关键范式和主要趋势。相比于单纯的对话机器人,Agent具备理解、规划、执行和反馈的闭环能力,能够真正完成复杂的业务任务,实现AI从“能对话”到“能工作”的关键跨越。
当前,企业可以根据自身技术储备和业务需求,在Amazon Bedrock、Dify、LangGraph等不同Agent编排框架和技术路线中进行选择,每种方案都具有其独特优势和适用场景。
然而,要将Agent技术真正落地为生产级应用,工程化方面还有诸多挑战有待深入探索:
质量保障:如何确保RAG检索结果的相关性和全面性,如何提高生成SQL的准确性,以及如何验证分析结果与反馈的可靠性。
安全与治理:如何实现不同角色人员的数据访问控制,包括认证、授权和租户隔离,保障数据安全的同时不影响使用体验。
复杂任务处理:如何通过Multi-Agent编排完成涉及多个步骤和多种能力的复杂业务流程,实现更贴近真实业务场景的端到端解决方案。
领域适配:如何结合特定行业知识和业务规则,使通用Agent演变为真正的领域专家。
持续监测:通过监控、日志分析Agent运行情况,持续优化成本与架构。
相信Agent技术将沿着以下几条清晰的发展轨迹持续演进:
能力边界的扩展,从单一任务向复杂工作流程延伸。
自主性的提升,减少人工干预,增强自我纠错和学习能力
专业化的深入,形成针对不同领域的专家级Agent。
协作模式的成熟,多Agent协同工作将成为解决复杂业务问题的标准方式。
在这场AI驱动的革命中,早期探索者将获得显著的竞争优势,期待看到更多企业勇于尝试Agent技术,构建更加智能高效的AI数据驱动未来。
亚马逊云科技提供完整的生成式AI解决方案,从Amazon Bedrock丰富的生成式AI能力,到容器化、Serverless等高可用部署架构,亚马逊云科技集成丰富的AI基础设施、托管数据服务和安全合规框架,支持多种向量数据库和LLM,全面加速企业生成式AI应用从开发到生产的全流程。

参考资料
https://catalog.us-east-1.prod.workshops.aws/workshops/2c19fcb1-1f1c-4f52-b759-0ca4d2ae2522/zh-CN
https://aws.amazon.com/cn/blogs/china/deploying-high-availability-dify-based-on-amazon-eks/
https://github.com/aws-samples/sample-serverless-dify-stack
https://docs.dify.ai/learn-more/use-cases/how-to-connect-aws-bedrock
https://github.com/datacharmer/test_db
本篇作者

张瑞焱
亚马逊云科技资深解决方案架构师,具有多年IT、DevOps、SRE、基础架构等方向从业经历,架构规划设计、团队管理经验丰富。致力于推广高效优雅的云原生体系架构,助力客户业务成功。

裴秋利
亚马逊云科技解决方案架构师,多年互联网行业沉淀,精通OPS、SRE、大数据平台设计与团队管理。现专注零售电商领域架构设计,提供高效云原生解决方案,助力客户业务数字化转型与创新增长。

邢倩
亚马逊云科技资深解决方案架构师,具有丰富的互联网头部企业技术团队管理、产研体系建设实践经验,对于各行业商业、产品、运营、技术架构有综合和深入的理解,擅于将云服务和生成式AI能力与客户业务成长深度结合,创造多赢机会。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客!获得更详细内容!


















 9466
9466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









